Alan Dix, Janet Finlay and Russell Beale
|
The trace of user interactions with a system is the primary source of data for on-line user modelling and for many design and research experiments. This trace should really be analysed as a time series, but standard time series techniques do not deal well with discrete data and fuzzy matching. Techniques from machine learning (neural nets and inductive learning) have been applied to this analysis but these are limited to fixed size patterns and fail to deal properly with the trace as a time series. Many of the notations used to describe the system dialogue (e.g. CSP, production systems) and the user's behaviour (e.g. GOMS, grammars) can be regarded as describing non-deterministic finite state machines. Such a representation forms a key to using machine learning techniques, focussed on the state transitions.Keywords Trace analysis, user modelling, machine learning, time series, state transition, GOMS.
System-logged traces of a user's interaction with an application are a primary source of data for automatic user modelling and for a wide range of research and evaluation experiments. Such traces are important for these applications for two reasons. Firstly, and primarily, in many instances this trace information is the only data available. This is particularly the case in automatic user modelling, where the user is working freely, observed only by the system itself. In the case of experiments, other data may be available, such as video or audio recordings or transcripts of conversation, yet these records serve to annotate rather than to replace the on-line trace. The on-line trace remains the most immediate and accurate record of the user's actions.
The second reason why traces are important is the ease with which they can be collected. Automatic logging can take place unobtrusively in the background of an application, and can record a wide range of data including all input, output, display details, state changes and temporal information. Unlike the other methods mentioned, it does not require the constant attention of an experimenter and can therefore record `normal' as well as experimental working patterns.
However these advantages may also create problems in the use of trace information; in particular it can be difficult to interpret the traces correctly since the context of an action cannot be observed directly and must therefore be inferred. One way of analysing the traces is to identify recurrent patterns within them, where a pattern corresponds to a particular action or goal execution. In order to do this effectively the trace must be viewed as a time series, where each item in the trace may be dependent on previous items. Viewing the trace in this way enables us to make use of automatic pattern recognition methods such as inductive learning and neural networks, which, as we shall see, have a number of advantages over alternative methods.
User behaviour is complex but it is not arbitrary. Rather, it contains recurrent patterns of behaviour. By training a pattern recognition system on known trace examples of such patterns we can analyse unseen behavioural traces and identify types of user or user behaviour (Finlay 1990, Finlay and Beale 1992).
There are a number of advantages to taking such a minimalist approach to trace analysis. Firstly, the analysis uses trace information only: the machine learning systems are trained on trace examples and can recognise other trace examples. No additional knowledge about the system or the way the system is used is required. This bypasses the inherent problem of knowledge acquisition found with knowledge-based methods. Secondly, the pattern recognition methods have the property that they can generalise from the seen example to an unseen example with similar but not identical properties. This means that variation within trace patterns does not prevent recognition. Thirdly, the approach is not domain dependent: a new set of examples allows a different set of system traces to be identified.
The analysis of traces `by example', using pattern recognition methods, has application in a number of areas. Automatic user modelling for adaptivity is an area where a `profile' of the user is required. Conventionally this is produced using knowledge-based methods but these tend to be resource-intensive, domain-dependent, and knowledge acquisition is problematic and time-consuming. Using example-based methods the traces can be classified on a number of dimensions at different granularities, ranging from identifying behavioural traits and experience levels, to identifying the user's current task.
The approach can also be used to analyse behavioural data in evaluation or design experiments, both to verify expected user behaviour and to identify deviations from the expected behaviour, which may represent a design flaw. This provides an automated means of performing at least the initial filtering of the trace.
The behavioural trace is a time series where the interpretation of each item may be dependent on the context of what has gone before. The machine learning methods proposed require fixed length input and therefore do not deal naturally with the trace as a time series. However it is possible to use `windowing' as a means of dealing with time series. This method provides a simple means of testing the machine learning methods for trace analysis but also highlights the need for a more sophisticated way of handling context. Later in this paper we investigate a method of representing the trace in terms of state transitions in such a way that allows us to use machine learning methods, while also handling the trace as a time series.
Firstly, in the next section, we review previous experiments using machine learning methods with windowing for trace analysis, which highlight the problems encountered when the data is a time series. We then review some possible time series analysis methods, and show how models and notations for describing users and systems, such as GOMS and CSP, can provide a representation for the trace which incorporates state transitions.
This section describes some previous experiments using data from a bibliographic reference database, REF. A standard neural network technique (ADAM, a form of associative memory [Austin 1987] and inductive learning (based on ID3 [Quinlan 1979]) were used to recognise standard task sequences. These experiments demonstrate the usefulness of machine learning techniques for trace analysis, but also highlight the problems due to the time series nature of the traces.
REF is a database system running on a PC machine, for accessing bibliographic entries, that have fields such as author, title, source, and date. It supports conventional database operations including search, delete, insert, and alter, as well as providing facilities for maintaining and creating libraries. Search operations include refining or adding to the result of a search, and beginning a new selection. REF is menu-based and items are selected by typing their initial letter at the keyboard.
The aim of the experiment was to identify task patterns in actual user traces (28 hours of use were logged from 14 subjects). Each subject performed a set of standard tasks (finding, amending, adding and removing references) based on Monk and Wright's more extensive evaluation [Monk and Wright 1989]. Their use was analysed in real-time -- to offer `advice' when required, and the interaction was also logged for off-line analysis.
In order to maintain a consistent and balanced representation of the trace, each trace feature was replaced by a unique symbolic code, resulting in a character string representing each trace [Finlay 1990]. Variable information, such as author names and titles, were ignored in this symbolic representation.
As example-based learning was used, a training set was required which matched traces with tasks. Because REF has such a highly constrained task-oriented menu interface, it is possible to generate a CSP description of all valid task sequences. This description can then be used to generate all possible valid traces of these task sequences (529 of them!). The traces, divided into 11 task categories, formed the training set.
Two machine learning techniques were used to analyse the data. ADAM is an associative memory, a form of neural net. It has very rapid learning and recall and was used for both on-line and later off-line analysis. Class is based on the ID3 inductive learning algorithm -- it was only used off-line, being slower than ADAM.
Both techniques classify fixed length inputs. A training set of inputs together with associated classes is used. This is presented to the systems which `learn' the classes. Later, when shown actual inputs, the systems allocate the inputs to one of the classes (or possibly as `unknown'). In this case the task categories were the classes and the sequences of valid traces for each task formed the training set.
As the inputs are required to be fixed length and the trace is continuous, some `fix' was required. The easiest fix is to use a moving fixed length `window' into the data. Two window lengths were used: 2 characters and 6 characters, being the lengths of the shortest and average task sequences respectively. The items in the training set were either padded or curtailed to make them fit the fixed length window.
Despite the obvious problems of this windowing method, task recognition was still quite high -- over 99% and 65% for window lengths of 2 and 6 respectively.
Although the recognition rates above were good there were problems with the technique. With the very short window length any task cycles which began with the same 2 features were indistinguishable. It was only the constrained task-oriented menus which made it possible in general to identify tasks by such a short sequence.
In general, one might expect a longer window to be necessary. However, the recognition began to fall off as the window size increased. This was because of the noise introduced as the short task cycles were padded
[Finlay 1990]. For instance, the sequence Me is padded out to Me%%%% in the training set, but in the actual interaction may appear as MeMsSk. The presence of these extra characters make identification of the cycle difficult (in fact in this case 2/3 of the pattern is different).
Further problems occurred where tasks consisted of some opening and closing, enclosing a sequence of repeated sub-tasks. Examples of the entire task would have demanded far bigger windows, and yet examples based on the sub-task alone were difficult to identify without contextual information about the larger task. It is exactly this contextual information which is missing when using a window based analysis.
In short, the actual task sequences were of variable length and in actual use embedded within a continuous trace. Although analysis using fixed windows has shown some success it is clearly inadequate when the data is a time series.
Our initial experiments show that machine learning methods have promise for trace analysis but fail, in their basic form, to deal adequately with time series data. We would therefore like to apply true time series techniques to user traces. We will briefly consider some options from statistical methods and extensions to machine learning.
Time series analysis is a major area in applied and theoretical statistics; it is the basis of much digital signal processing and is used in applications ranging from ocean waves to economic analysis. It yields both analytic and predictive results, but, in its standard form, it deals with continuous data and usually linear models over this data. It is thus inappropriate for our purposes; however, it represents the ideal for linear systems that we should strive to emulate when using whatever non-linear technique we apply.
Markov processes are based upon discrete, symbolic time series and have been used in user modelling. Basically one can calculate the probabilities of successive inputs given the last few inputs. Strictly a Markov process only uses the current input to predict the next, but models which use a small but fixed number of previous inputs can also be dealt with.
One of our requirements is for fuzzy matching of the input and generalisation. The probabilistic nature of the Markov model does embody this to some extent, but it would not deal well with a single erroneous input corresponding to a mis-keyed command, for instance. Also the simple Markov model uses a fixed length window and thus suffers the same drawbacks as the techniques described in the last section.
Linear time series analysis is able to deal with relationships extending arbitrarily far into the past. In digital signal processing this is called infinite input response (IIR) where the output depends upon all the inputs so far, as opposed to finite input response (FIR) where, like the Markov models, the output only depends on a fixed number of previous inputs. One way of understanding an IIR filter is by way of a hidden state. The statistical analysis infers this state and uses it for prediction. If one regards the Markov process as the discrete analogy of FIR then one might try to use the similar discrete analogy of IIR, a `Markov' model where one has inferred a hidden state. Clearly generating such a model is more complex than a standard Markov model and also still has problems with generalisation.
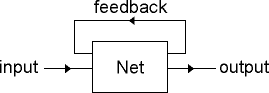
The same approach of using hidden states to attack time series can be applied to machine learning techniques. A standard neural net or inductive learning system associates an input with an output. We can make a recurrent system by simply mapping some of the outputs back to the input (Figure 1). This feedback is the `hidden' state of the system. The problem with such a system (as with the state version of the Markov model) is how to teach the system.
Figure 1. Recurrent system with hidden state
Back-propagation neural nets can be adapted in this way, as in the Jordan and Elman networks [Jordan 1986a, 1986b, Elman 1988]. Training of these normally proceeds by feeding errors in output back through the net and adjusting weights appropriately. For a recurrent net one also needs to feed back the errors to the state to give an `error' for the state which can be given to the previous time step. It involves storing intermediate states during the training stage and running the training sequences forward and backward. Training for back-propagation is already very costly and recurrent nets are bound to be yet slower, but this may be acceptable if the results are useful.
The ADAM associative memory was used in the experiments described above because of its very fast learning and recall. This is because its training is all `forward' with no back error propagation and only single presentation of input-output pairs. Despite its clear advantages in terms of performance, there is no obvious way in which its training can be generalised to the recurrent system without some prior knowledge of states.
Finally, if we look at inductive learning systems, they have clear advantages in terms of comprehensibility, as their decision structure is observable. However, there is again no obvious way for the systems to `learn' hidden states -- they would also require some prior knowledge about the states of the system. Also their generalisation is based upon an attribute-value based description of the inputs -- the state must therefore be in this form. However, the state must also be an output and this is not normally in an attribute-value form. Extensive work must be done to apply such techniques.
From the above description there is no obvious best method for analysis of traces. However, we have seen that both statistical and machine learning techniques can most easily be applied if we regard the system as possessing a (finite) hidden internal state. How useful is this representation? If we look at notations and models for describing interactive systems and their users, we find that they have precisely this form.
First we will consider the system. Various notations are used to describe the dialogue: for formal analysis, prototyping or for final systems. Some use a finite state description directly or with some syntactic sugar [Jacob 1986, Cockton 1988]. Regular expressions are also used [Plasmeijer 1981], for example, one might describe line drawing as:
Again regular expressions are exactly equivalent to finite state descriptions. Often these descriptions of the dialogue syntax are augmented by semantic actions relating, say, the precise values of system inputs and outputs. These correspond to a far richer model of the system, but can be regarded at the syntactic level as non-deterministic or random.button_down move* button_up
There are other dialogue notations but one of the most important for our purposes is CSP a process algebra [Hoare 1985], as this was used to describe the REF system above. It has also been used by Alexander as the basis of her SPI interactive system specification language [Alexander 1987]. Strictly CSP, even devoid of the `semantic' additions, is more powerful than a simple finite state system. However, actual descriptions rarely use this extra power, and in particular, dialogue descriptions sit within the `finite state' part of the language.
The different notations above make certain types of system easier to handle, for instance, in their handling of concurrent dialogues such as multiple windows. But at a deep level, once we strip out the semantic additions, they can be treated as (possibly non-deterministic) state transition systems.
Now, if we switch our focus to the user, a similar story unfolds. Some models (e.g. ICS [Barnard et al. 1988]) involve deep cognitive understanding: these, like the semantic parts of the systems models, are too complex for a simple state transition approach. However, there are many models which operate closer to the syntactic level while still embodying interesting cognitive features. GOMS is a good example [Card et al. 1983]. The hierarchical goal structure leads to the generation of a goal stack while the GOMS model is `executing'. Because the goal structures are normally not recursive, the goal stack will be of bounded size (in any case short term memory requirements would demand it). We can thus regard the goal stack as the state, with transitions corresponding to the selection of new sub-goals and the execution of operators. Other syntactic cognitive notations can be similarly treated, for instance the use of grammars or production system [Reisner 1981].
So we have seen that both system dialogue models and simple cognitive models can be treated as non-deterministic state transition systems. In the former case the states correspond to system states such as modes, in the latter to cognitive states such as a goal stack. Often a simple translation has transitions corresponding to non-observable events. On the system side this would be processing which involved no input or output, on the user side this would include events such as pushing a sub-goal. As the traces we wish to analyse only record the observable interaction, we must factor out these unobservable events. This tends to make the description more non-deterministic, but is not fundamentally difficult.
When we discussed the various time series analysis techniques, we found that most had difficulty if there was no existing state description. We have just seen that if we possess, for instance, a CSP system description or a GOMS model of the user, then we already have such a state description. This can then form the basis for training, say, a recurrent version of ADAM for analysing traces.
Alternatively, we may start with the traces and attempt to learn a state description using, say, back propagation. Can we then use this in deriving a user model?
In the following sub-sections we will look at the uses of these two activities: forward from models to traces and backward from traces to models.
As we have noted, the states from a model, such as CSP or GOMS, can be used to train a recurrent system. In the case of CSP, one could generate example traces automatically. One could do the same for GOMS, or alternatively annotate actual traces by hand with the supposed goals active at each point.
We can now take transitions of the form:
and train an ADAM network. The training set consists ofinputold state
output
input - old state pairs
as stimulus and output - new state pairs as response. After training the network
can be wired up as a recurrent system and given a trace will generate a sequence
of states and outputs [Beale 1991].
We envisage various applications for this technique. GOMS type analysis is usually of expert error free behaviour. It is hard to predict all possible error behaviours, and harder still to code them within the model without destroying its structure entirely. However, if we use an error free GOMS model for training, the fuzzy matching of the net will allow it to match traces which are not perfect executions of a GOMS method. We can thus recognise user's goals even when his behaviour contains errors or unexpected deviations from the specified behaviour. This recognition of goals is of course extremely useful for help systems where a rule based system can advise the user based upon the user's inferred goals.
Goal recognition is also useful during system design. A pass over example traces can highlight areas where recognition is poor -- that is where the GOMS model does not adequately describe the behaviour. These areas can then be the focus for further human analysis, possibly updating the GOMS model. Areas where there is recognition, but where the actual trace does not exactly match the `ideal' trace represent possible user errors. Thus the designer can fast-forward through the trace to these potential error sites. The simple fixed window scheme has been used in exactly this fashion [Finlay and Harrison 1990]. A list of error types, `critical incidents', was made by hand as part of Monk and Wright's analysis of REF. A large number of these were recognised as imperfect examples of otherwise valid CSP traces. For some classes of error all the errors were correctly recognised as the underlying or `base' task sequence but with large `distance measures' and low confidences which indicated clearly that an error had occurred (i.e. the example deviated from that trained for the task class). However, the problems of fixed windows became apparent again with shorter error traces as the system tended to regard them as correct, due to the padding. We expect that the performance on these errors can be improved substantially when recurrent nets are used. The process can be repeated, having recognised some classes of error. These can then be taught to the net, which can recognise them in future traces and skip them during the fast-forward. Even if only the simple incidents can be handled automatically, the job of evaluation can be substantially eased.
As we have noted it is possible to use methods such as back propagation to generate a fuzzy state transition model. We would not expect this inferred model to be as clean as one generated by hand as it would include all the elements of the real user behaviour, including typing errors, mistaken and half executed plans. Where such non-optimal behaviour is common it would become incorporated into the model; otherwise it would just be noise. By adjusting parameters of the learning algorithm we can change the level at which these error behaviours become part of the model. With the exception of such parameter tuning, the learning is completely unsupervised.
How do we use such a model? Firstly, we may use the model as a black-box. As with the model taught from a GOMS or other description, we can play the inferred model against a trace (either the trace it was taught from or a new one). It will annotate the trace with states. Points at the trace with the same state are in some way similar, and points which have poor fit or infrequent states represent odd incidents in the trace. The designer can then focus on the odd incidents, or, having seen some portion of the trace, ask to see `something new' and have the system find a portion with an as yet unseen state representing some fresh user behaviour. Again this does not automate the analysis of such traces entirely, but is a way of substantially reducing the laborious trawl through of vast bodies of data.
Ideally, we would like to use the model in a second way -- as a first step towards a GOMS or similar description of the system. It would not be reasonable to expect the net to generate a sensible cognitive model in entirety, but if it can help in the process this would be an advantage. Unfortunately, the mappings inferred by a neural net are likely to be incomprehensible: their very fuzzy nature, which is an advantage when dealing with real user behaviour, means they are not easy to interpret. There are two possible ways to deal with this. One is to use the inferred states to train a different method such as ADAM or a Markov type model. This is not as silly as it sounds, these other methods are more comprehensible but are incapable or impractical at inferring states. Alternatively, we can use the inferred states at the level of the trace, looking at examples of each state and make judgements: ``ah yes, the user is updating a record here''. The human analyst would gradually paint in the states with meaningful descriptions. To some extent the analyst is still producing the model by hand, but guided by the automatic analysis.
So far we have examined what can be achieved using existing techniques with little modification. There are some additional problems which require more extensive theoretical work. The technicalities are not of interest here, but we will outline some of the reasons for the additional difficulty.
Although we have suggested one way to address the incomprehensibility of the state models generated by a back propagation neural network, this remains a problem. However, this is not a special feature of trace analysis, but a general issue whenever neural nets are used. There is ongoing work on explanation facilities for different forms of neural net, but possibly more domain-specific solutions, such as those we have outlined, stand the most likelihood of success.
Many traces we would like to analyse contain variables. For instance, command line usage of an operating system will contain references to file names. Consider the sequences:
1. 2. 3.
We would like the first two to be recognised as similar as they are both instances of the generic pattern:
cc -c <a name> vi <the same name>
However we do not want the last example to be recognised as the same thing since the sequence deals with operations on different files. This form of variable matching is not possible given current machine learning or statistical techniques, although it is of course used in more AI-based systems such as programming-by-example. Marrying this form of symbolic processing with the fuzzy pattern matching offered by, for instance, neural nets is a difficult but important problem.
We have several extensive data sets with different properties, which we are or intend to analyse:
The experimental data which has already been analysed using fixed window techniques, and which we are beginning to analyse using the recurrent ADAM network. The existing CSP description means we already have an appropriate state model for training. It also can yield good comparative results between fixed window and state-based analysis.
We have extensive transcripts of use of various experimental electronic conferencing systems [McCarthy et al. 1991]. The trace of interest here is not the human--computer dialogue, but the human--human dialogue between the conference participants. We do not expect to analyse the actual language used (!), but some of the logs have been annotated with the topics discussed during each conversational turn. Of particular interest is whether the discussion of a topic results in common understanding, which has been measured using post-experiment questionnaires. The topics usually only last a short time, and hence it is possible to use fixed window techniques. On the other hand the data is almost entirely variable based, the important thing is the structure of the discussion of topics. It is thus an interesting test bed for the use of variable based techniques.
This is a programming environment, for which we possess a large body of free use logs. These have already been analysed on a per-session basis using both ADAM and ID3 [Finlay 1990] concentrating on recognising expertise. A more detailed task-based analysis is far more complex than the REF system because of the less constrained nature of the system making, for example, a CSP or GOMS description impractical. Furthermore, the glide logs contain many variable references to program function names. The existing analysis simply ignored these, however the data set is an ideal testing ground for techniques combining true time series with symbolic inference.
Analysis using fixed window techniques has been pursued as far as seems useful. For the reasons outlined above we need to use true time series techniques. We have outlined a methodology for doing this, using existing modelling approaches. We are currently using the recurrent version of ADAM trained using hand coded dialogue descriptions, as this requires little modification to our existing systems. We expect to move on to use back-propagation techniques for inferring states at a later date.
The results using simple windowing methods, and initial success with a recurrent version of ADAM, suggest that the extensions outlined here will prove beneficial for trace analysis in user modelling and design. In particular, they will allow more accurate interpretation of recorded user actions by taking account of surrounding context, while retaining the benefits of efficiency and example based learning afforded by the neural approach.
Alan Dix is funded by a SERC Advanced Fellowship B/89/ITA/220 and Russell Beale is funded by Apricot/Mitsubishi.
This is an example derivation from a GOMS-like description to non-deterministic state transitions. The task is using a function key based word processor to change single words in a manuscript to more appropriate ones. It is assumed that the manuscript is marked with all the words requiring correction, the typist's only job is repeatedly to correct the next word. Only two methods for correcting a word are considered. One uses the search-replace option setting the correct spelling as the replacement string. The other way uses the search facility to find the word, delete it, and then type in the replacement.
This is relatively complete, but doesn't bother with any mental or perceptual operators (e.g. looking at the manuscript) as these do not appear in the behavioural trace.
Goal: correct manuscript . [1] Goal: correct word repeat until all done Goal: correct word . Select M1: search-replace method . . [1] press F9 . . [2] type old word . . [3] press F10 . . [4] type new word . . [5] press grey+ repeat until found word . . [6] press F10 . M2: delete retype method . . [1] press F9 . . [2] type old word . . [3] press grey+ repeat until found word . . [4] Goal: delete word . . [5] type new word Goal: delete word . [1] press F4 . [2] press word-right . [3] press F4
We now go through the model tracing the possible goal stacks. At this stage,
to ease exposition and make the correspondence clearer, state transitions corresponding
to most state transitions in this example are labelled by the associated operator
-- that is the key pressed. These are external visible actions which will appear
on the trace. Some state transitions correspond to internal cognitive actions:
selection of methods, pushing and popping of sub-goals. These are included at
this stage and marked with a ![]() , however,
at a later stage they will be removed.
, however,
at a later stage they will be removed.
The full goal stack model generated at this stage, a portion of which is shown in Figure 3 at the end of the paper, is very large and repetitive. This and subsequent stages of processing can be performed automatically given the GOMS description.
Finally we turn the goal stack states into abstract states (labelled here S1, S2 etc.). The ![]() transitions representing internal cognitive transitions have been removed. Also states having identical behaviour have been collapsed: both methods started by using F9 and then typing the old word. So, for example, state S2 corresponds to either of the following goal stacks:
transitions representing internal cognitive transitions have been removed. Also states having identical behaviour have been collapsed: both methods started by using F9 and then typing the old word. So, for example, state S2 corresponds to either of the following goal stacks:
[1] press F9 Method: search-replace Goal: correct word |
OR |
[1] press F9 Method: delete retype Goal: correct word |
An approximate mapping between states and the GOMS goals is as follows:
S1: press F9 - either method, initial state S2: type old word - either method S3: type new word - search-replace method S4: press grey + - "" "" "" S5: press grey + - delete retype method S6: press word-right - in delete word sub-goal S7: press F4 - "" "" ""
 x
x
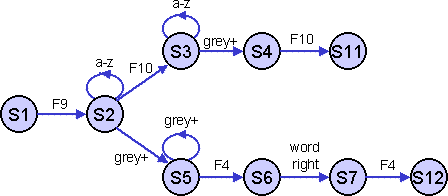
Figure 2. State transition scheme
The state transition scheme can be represented diagrammatically (Figure 2). Alternatively, we can show the state transitions in tabular form, somewhat as they would be stored in the system. The row labels denote the current state, the column labels show the various actions and the states in the table show the new state. The gaps in the table denote departures from the GOMS model, if any occur in a trace these would correspond to errors or spontaneous non-predicted behaviour.
a-z F9 F10 grey+ F4 word-right S1 S2 S2 S2 S3 S5 S3 S3 S4 S4 S1 S4 S5 S5 S6 S6 S7 S7 S1
Finally, the state model is used to generate examples to train a neural net or similar system. The examples are triples of the form:
old state - action - new state
and are simply read from the table above:
old action new S1 F9 S2 S2 a-z S2 S2 F10 S3 . . . S6 word-right S7 S7 F4 S1
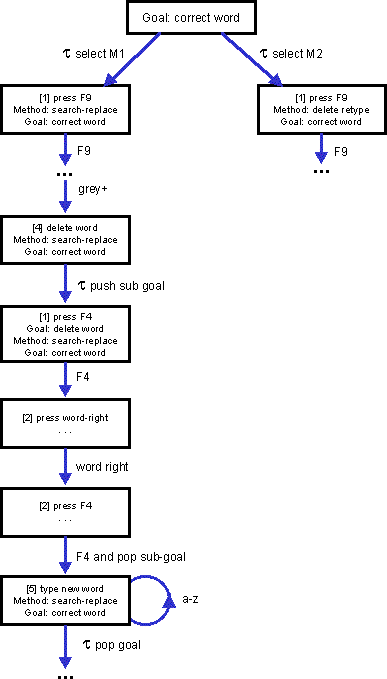
Figure 3. Portion of goal stack model
| http://www.hcibook.com/alan/papers/hci92-goms/ |
Alan Dix,
2/1/2002
|