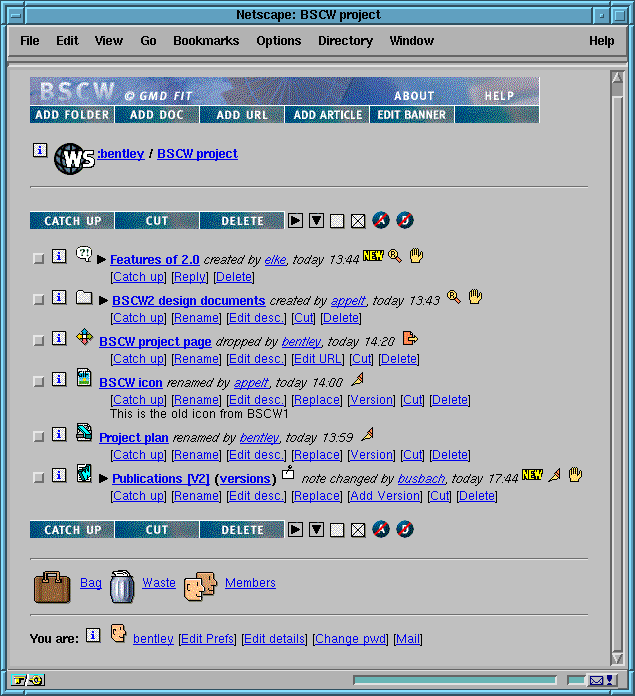
Figure 1. BSCW version 2.0 HTML user interface
This is the content of the slides for my presentation at the panel session of the Time and the Web workshop. I've expanded the bullets into some explanatory text, added references, and a few comments based on the discussions on the day.
A 'BSCW server' (Web server with the BSCW extension) manages a number of shared workspaces; repositories for shared information, accessible to members of a group using a simple user name and password scheme. In general a BSCW server will manage workspaces for different groups, and users may be members of several workspaces (e.g. one workspace corresponding to each project a user is involved with).
A shared workspace can contain different kinds of information such as documents, pictures, URL links to other Web pages or FTP sites, threaded discussions, member contact information and more. The contents of each workspace are represented as information objects arranged in a folder hierarchy (Figure 1). Members can transfer (upload) information from their machines to the workspace and set access rights to control the visibility of this information or the operations which can be performed for others. In addition, members can download, modify and request more details on the information objects by clicking on buttons - HTML links that request workspace operations from the BSCW server, which then returns a modified HTML page to the browser showing the new state of the workspace.
Figure 1. BSCW version 2.0 HTML user interface
Access to workspace functions is provided by the buttons at the very top of the page as well as the text HTML anchors below each object. The former operate on the current folder being shown, so that 'add URL' will return a HTML form for specifying the name and URL of a URL link object to be added to the current folder, while the latter perform operations on the individual objects, such as 'rename', 'edit description' and so on. As a short cut, the checkboxes to the left of each object in combination with the buttons above or below the list of objects allow operations on multiple object selections.
'The Web shows through'
Initial designs of the BSCW user interface attempted to provide, within
the constraints of HTML, a rich user interface familiar to users of modern
graphical desktop machines. Such interfaces rely on rapid response to user
clicks to update the underlying application state and provide consistent
representation of that state in the user interface, thus exploiting the
local connection between application and user interface to provide a rich,
bi-directional channel for update messages. This channel does not exist
for Web-based applications, where presentation and application are separated
by the Internet and all communication is based around client-initiated,
request-response patterns.
As a consequence for BSCW, each operation required at least one round-trip to the BSCW server. As network delays were (by far) the major component of the feedback loop for the majority of users interacting over the Internet, this greatly reduced the 'interactivity' of the system; for focused 'sessions' (as opposed to loosely-connected requests which can be 'backgrounded') this lack of response was especially problematic.
This observation is perhaps interesting for the designers of all Web-based systems, and points to the need to reduce, as much as possible, the number of times the client needs to go to the server for a given task. This in turn raises questions of whether interface design for such applications is better described with a 'batch processing' rather than 'direct manipulation' metaphor, whereby multiple 'requests' might be submitted to the application as a single 'job'. This is especially pertinent for porting existing systems to the Web, where the interface-application dialogue might rely on a much richer channel for communication.
'Individual differences'
A rationale for building a system like BSCW on the Web is to exploit
the 'homogenous client' offered by the Web browser across different computing
infrastructures. An application need only provide one user interface -
in HTML - instead of multiple instances coded for native toolkits like
Motif, Windows and the Mac toolbox.
In actual fact, experience with early versions of BSCW showed that the notion of the 'homogenous client' is not true. Although the browser might provide a common environment, different computing platforms, levels of network connectivity, applications software, screen size and so on all have an effect on the utility of the design of the application's interface and the way we use it. For temporal implications consider the role of network connectivity; while at work on a powerful workstation with a direct connection to the Internet I might download a document, scan it, download another etc., at home with a modem link I might request a number of documents to be archived and compressed before downloading (and then go put the kettle on).
These aspects concern the role software and hardware infrastructure might play on how we use the Web and Web-based applications. Equally important is the tasks the user is trying to achieve. An example from BSCW concerns the amount of information the system should present (and thus the time taken to arrange and download it) when a user is browsing a workspace to see what's new, as against navigating to a known location to fetch a specific document. Other implications of the user's task might concern 'quality' of required information, suggesting we might sacrifice quality for speed in certain, task-specific situations.
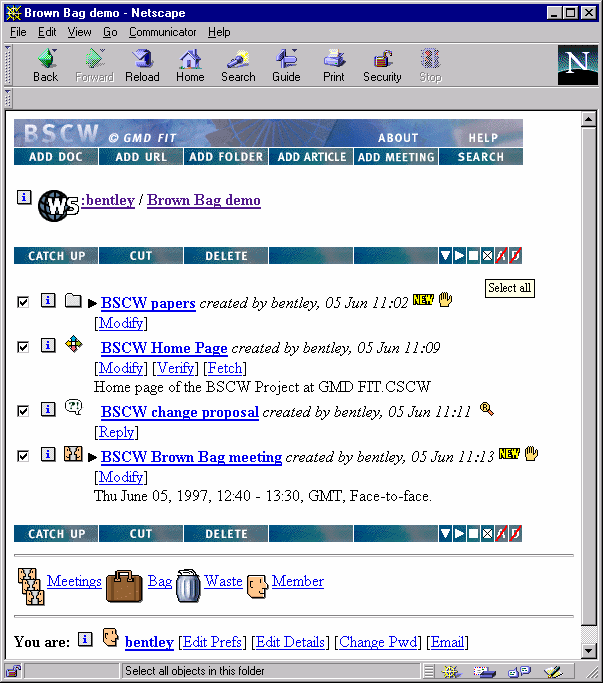
Figure 2. BSCW 3.0 user interface
'JavaScript for user interface state changes'
The need to go to the server for simple user interface state changes
has been partly removed by selective use of JavaScript. JavaScript is a
simple yet powerful scripting language allowing code fragments to be embedded
in a HTML page. As it is understood by both Netscape and Internet Explorer
Web browsers it is a good candidate for enhancing HTML pages. In Figure
2, the 'select all' toggle has been modified to use a JavaScript routine
to select all the items in the workspace listing, thus removing the previous
need to go to the server to re-compute the entire page. A similar solution
is applied to folding and unfolding of action and description lines to
customise the presentation of the listing.
'Better use of HTTP caching'
Because BSCW is multi-user application, it was felt in earlier versions
that none of the pages generated by the server should be cached to force
the client to request an up to date version whenever a request was sent
to the server. The rationale for this was that objects could be added and
deleted by other users, events could be generated and so on, and a browser's
cached copy of a page could quickly become out of date. In fact, HTTP provides
better control over caching than this might suggest, and in more recent
versions the strategy has changed. Pages returned by the server now contain
time-stamp information, allowing browsers to perform 'conditional' requests
for pages they have old copies of in their cache; using this timestamp
the server can check if the page should be re-generated for that browser
and tell it to use its cached version if not, cutting out needless re-generation
and download of a page that hasn't changed. Advances in cache control in
the next version of the HTTP control might allow more flexible alternatives
for the user - for example, to select to browse 'disconnected' using cached
pages as much as possible, and synchronise at a later date.
'Chunking of workspace operations'
The notion of applying the same operation to multiple objects through
the select toggles and the multi-select operation bar was introduced in
earlier version of BSCW. This is being extended to applying multiple operations
to the same object. In the current version shown in Figure 2 the list of
'modifier' actions like 'rename', 'edit' etc. displayed under an object
in the workspace listing has been replaced by a single action called 'modify',
which allows the user to update any aspect of an object from a single screen
(filtered by access control). With this approach multiple updates to the
same object could be 'batched' together - for example a text document could
be edited in a HTML TEXTAREA and its description edited and the updates
commited with one request to the server.
'Images downloaded to local site'
The behaviour of disabling 'image loading' is often reported as a 'coping
strategy' for performance problems. In general users don't actually want
a text interface however - for a system like BSCW a textual equivalent
could easily be extremely cluttered and there are good arguments for icons
to represent document types, certain operations and so on. Rather than
invest time in designing a text only interface, the current version of
BSCW allows icons to be downloaded and stored locally, and the user to
indicate the system should generate icon URLs which point to the local
icon directory (or a directory on a local Web server) rather than URLs
which point to icons at the BSCW server. This greatly speeds up interaction
with the server for users with poor connections, particularly the initial
requests where icons are often unavailable from the memory or disk caches.
'Interface reveals information'
One approach to dealing with temporal problems with Web interaction
is to provide more information to users regarding what the various links
in a page point to - and what the costs might be in terms of download time
(see Chris
Johnson's workshop contribution for example). A simple example of this
is provided by BSCW, which uses the 'tool tips' feature of newer versions
of browsers like Netscape and Internet Explorer to display image ALT text
when the cursor is positioned over an icon in the listing (The 'select
all' button in Figure 2). Effort has therefore been invested in ensuring
ALT text for all images is as revealing as possible.
'Server-side archiving and compression'
To address problems of connectivity BSCW 3 also includes tools for
server-side archiving and compression (and also format conversion). It
is possible for users to select a number of documents, folders and so on,
choose from a list of archive and compression formats the server can generate,
and request download of the resulting archive with a single request to
the server. The rationale, design and benefits of this approach are discussed
in detail in a paper
available on-line.
BSCW is a Web-based collaboration tool, and it is worth considering how typical some of the experiences with this tool are and how well they might generalise to other uses of the Web. For example, some aspects of working with BSCW which may not be typical to other ways of working with the Web include:
'Treat media types differently'
Image data accounts for the vast majority of Web data transfer, and
thus for a major chunk of the download time for a Web page. The amount
of data is not the only reason for this; with the current standard for
the HTTP protocol browsers must open a separate connection to request each
image in the page, incurring all the overhead of connection set-up and
heavily loading the network and origin server. Although the next version
of HTTP - HTTP/1.1 - will address this problem by supporting multi-plexing
multiple data files over the same connection, the problem of disproportionate
size of image to text data size will remain - and disabling 'automatic
image loading' will remain a necessary coping strategy.
Designers of Web pages can help greatly here by specifying HEIGHT/WIDTH tags for each image in the page, and thus allowing browsers to allocate space for each image and display the text accordingly before the image data has started to arrive. A further improvement might result if origin servers were to treat image data different to text data, reflecting the fact that image behind a given URL rarely changes. Currently many servers timestamp all data returned to the browser (the 'Last-Modified' HTTP header), forcing the browser to check with the server to see if the data has changed before using a cached copy - if servers were to avoid this for image files but continue to timestamp text data files then many needless connections and requests might be avoided. In general, this might point to a need for Web components to treat different media-types differently.
'New approaches to caching'
Currently Web caching is driven solely by storing information relating
to 'where a user has been' (or a group of users in the case of a proxy
cache). It might be useful to extend this to 'where a user might go'. For
example, when a page is loaded a browser (or proxy cache) might examine
the various links and commence pre-fetching some or all of these, speeding
access to the linked page when the user navigated to it. An obvious problem
here is the extra wasted bandwisth involved in pre-fetching many pages
the user might not access, but this could be reduced perhaps by fetching
only the text and ignoring included images. (Someone during the workshop
mentioned a product called 'Peakjet' (sp.?) which does something similar
over a modem links to utilise idle time).
Another way in which a cache might be better used is during the request to the server to see iif a cached page can be used or a new one must be downloaded. While this check is being made it might be useful to display the cached page anyway - with suitable indication that it may be out of date and that the origin server is being queried. Some browsers do this if, for example, an origin server cannot be contacted and ask the user if they want to see an old cached copy instead; I think this could be made the default case; often when accessing previously visited pages the purpose is simply to re-locate some information. In general, the Web protocols and components seem to embed the notion that everything changes and must always be up to date; in fact, the nature of the Web means that information might be out of date as soon as it is downloaded and the connection closed, and in some situations it might be better to allow users to trade 'currency' to avoid delay.
'Make the Web more transparent'
The above suggestions focus on possibilities for improving the performance
of the Web once a link is clicked. An alternative and complementary approach
is to improve the information to the user regarding what the link points
to, allowing users to better discriminate if link is worth following in
the first place. Examples could go beyond adding file sizes next to links
to reveal possible costs (and see Chris
Johnson's paper for more examples) to downloading small chunks of 'meta-data'
about the link, available to the user with a pop-up right button (Windows)
menu for example - such would be straightforward with JavaScript, Active
HTML and the like. (A workshop participant mentioned that early hypertext
systems like Guide had similar features which allowed links to be typed
and their properties accessible from the referenced page).
As well as adding information to improve the transparency of links, we could perhaps usefully reflect underlying properties of the Web at the interface. Just as information on what a link actually points to might allow users to discriminate (or at least give a rough guide of the order of time for download), revealing whether a page is in the cache or not would also give valuable information. Currently Web browsers use different colours to indicate if a link is to a page a user has previously visited or not; and a similar approach might give users some indication of which information can be accessed immediately and which needs to be fetched. In general as the fact that 'the Web shows through' is beyond dispute, we shouldn't hide this behind opaque interfaces but actually give users information on what's going on underneath so they can make informed decisions on how to proceed. (This is similar to some of Paul Dourish's arguments for systems which account for their actions).
The pace of innovation in the technologies which support the Web has been extremely rapid. Here are some examples: