
Here we regard the core learning algorithm and its representations as entirely inscrutable. However, this inscrutable representation can be used with the black-box algorithm (e.g. classifier) to act as an oracle on unseen inputs. This enables various forms of exploratory or perturbation analysis that use manipulations of the inputs and explore their effects on the outputs.
BB1. Exploration analysis for human visualisation.
Lots of random or systematically chosen inputs can be used to create input–output maps that can be visualised using standard scientific or information visualisation techniques.. The influence explorer is a good example of this albeit for simulation-based results rather than black-box ML.
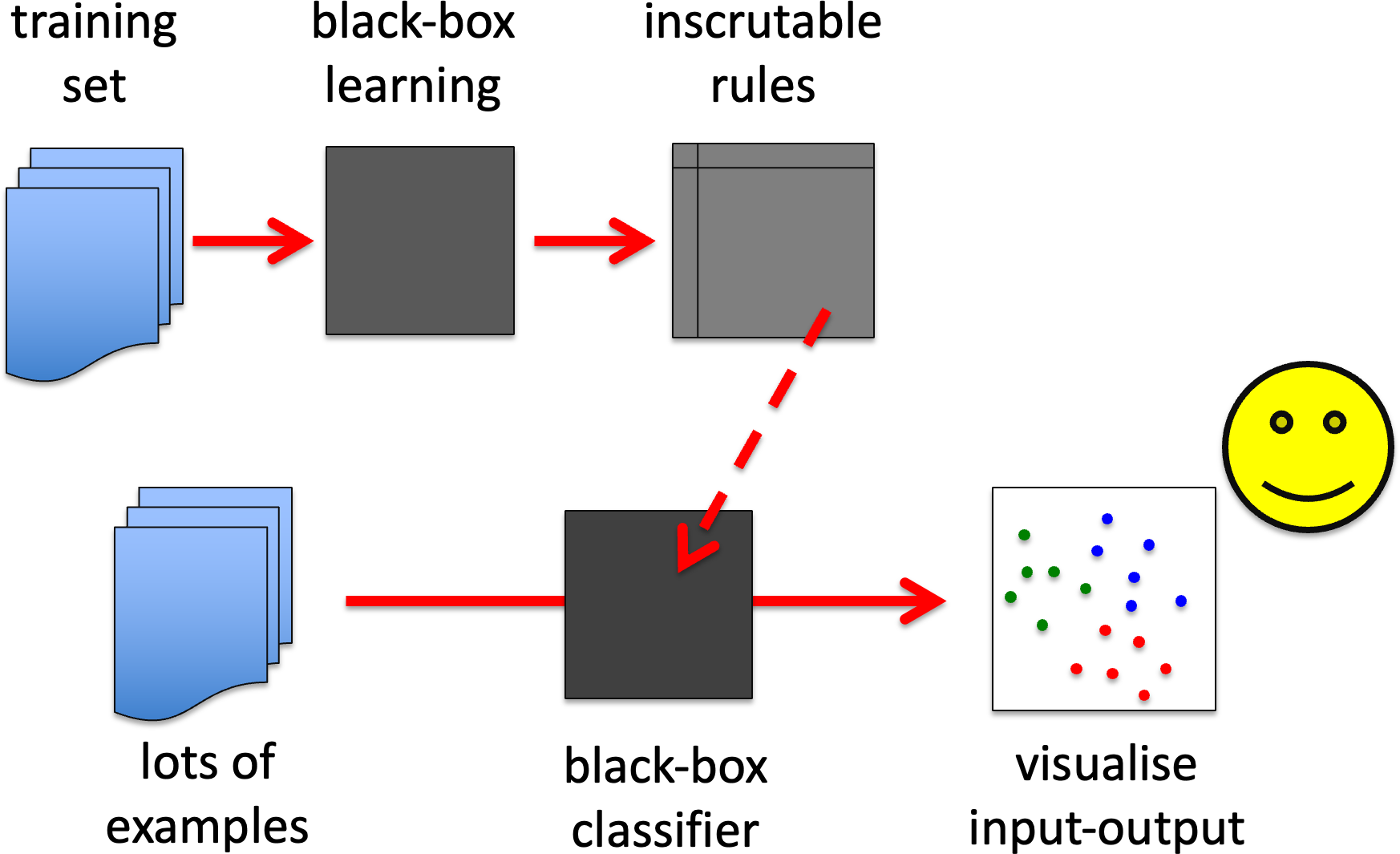
BB1. exploration analysis for human visualisation
BB2. Perturbation/exploration analysis for key feature detection.
This is especially useful where there is a large input feature vector, which is being used in an unknown or hard to comprehend way by an algorithm. Basically one either systematically or randomly changes individual input features or sets them as missing values (if the algorithm can deal with these) and see how this affects results. This can be used to establish which are the most important features for particular aspects of the automated decision-making.
An example of this is in vision research patches of pixels are randomised and this is then used to create hot-spot images of where the computer is focusing its ‘attention’ in making particular classifications. This can help determine, for example, whether the learnt rules are using sensible parts of the image or potentially accidental features (like the old example of a NN that appeared to be able differentiate US vs Russian tanks, but turned effectively be a sunny weather recogniser!).
The outputs of this can be used for human comprehension directly, or can be used for feature detection for second round of learning … including white box techniques.
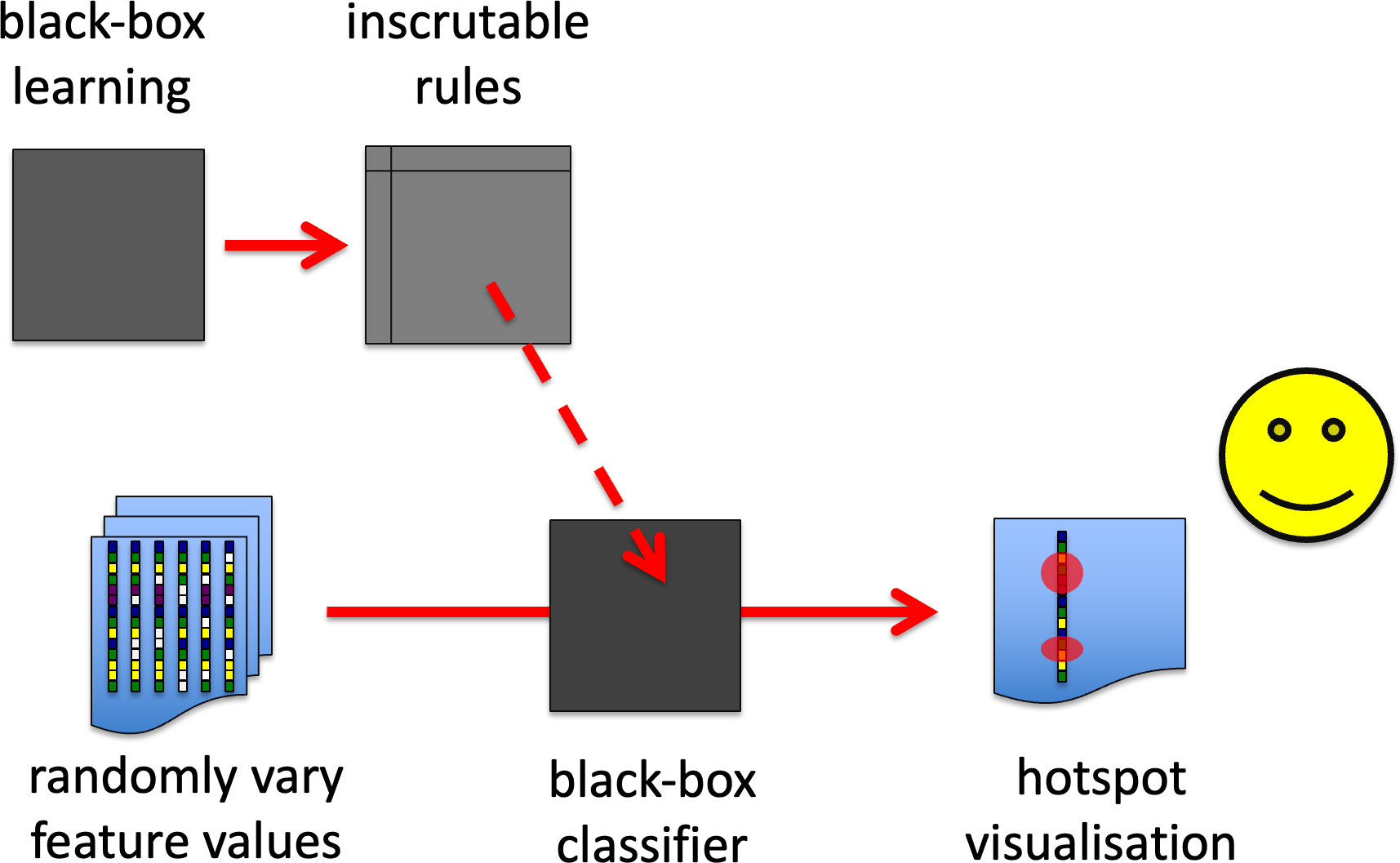
BB2. perturbation/exploration analysis for key feature detection
BB3. Perturbation analysis for central and boundary cases.
Use this for classification or other forms of discrete output algorithm. As with BB1, start off by generating lots of examples, but then perturb each. If an example’s output remains constant (e.g. discrete classification) despite perturbation it is central. If small perturbations change the class it is a boundary example. Those examples where small perturbations do not change it, but larger ones do (large and small as measured by Hamming distance, or other suitable metric) are in the penumbra of the boundary – these may also be useful.
The boundary and central cases can be used to help a human understand the classes. The examples can also be used to train different kinds of classifiers, for example using boundary cases to boost learning for more symbolic ML (BB methods feeding into WB). The actual boundaries or penumbra cases can be chosen depending on whether the secondary ML can deal with uncertainty.
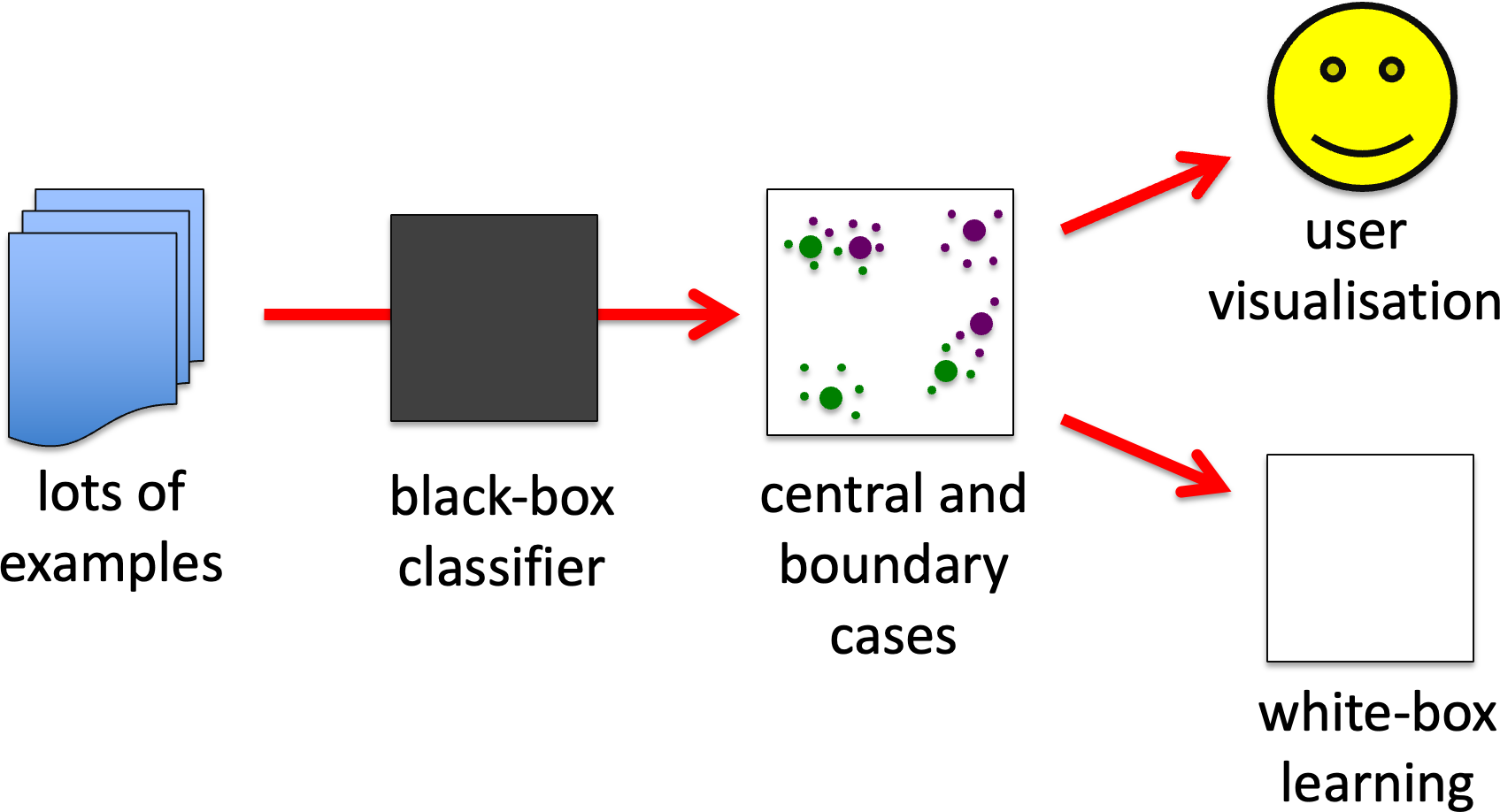
BB3. perturbation analysis for central and boundary cases

BB3. close up
BB4. Black-box as oracle for white-box learning.
Rather like BB1, the black-box model can be used to classify large numbers of unseen or generated examples. These generated input– output pairs can then be used as training data for white-box algorithms, as we described doing for adversarial behaviours in WB3.
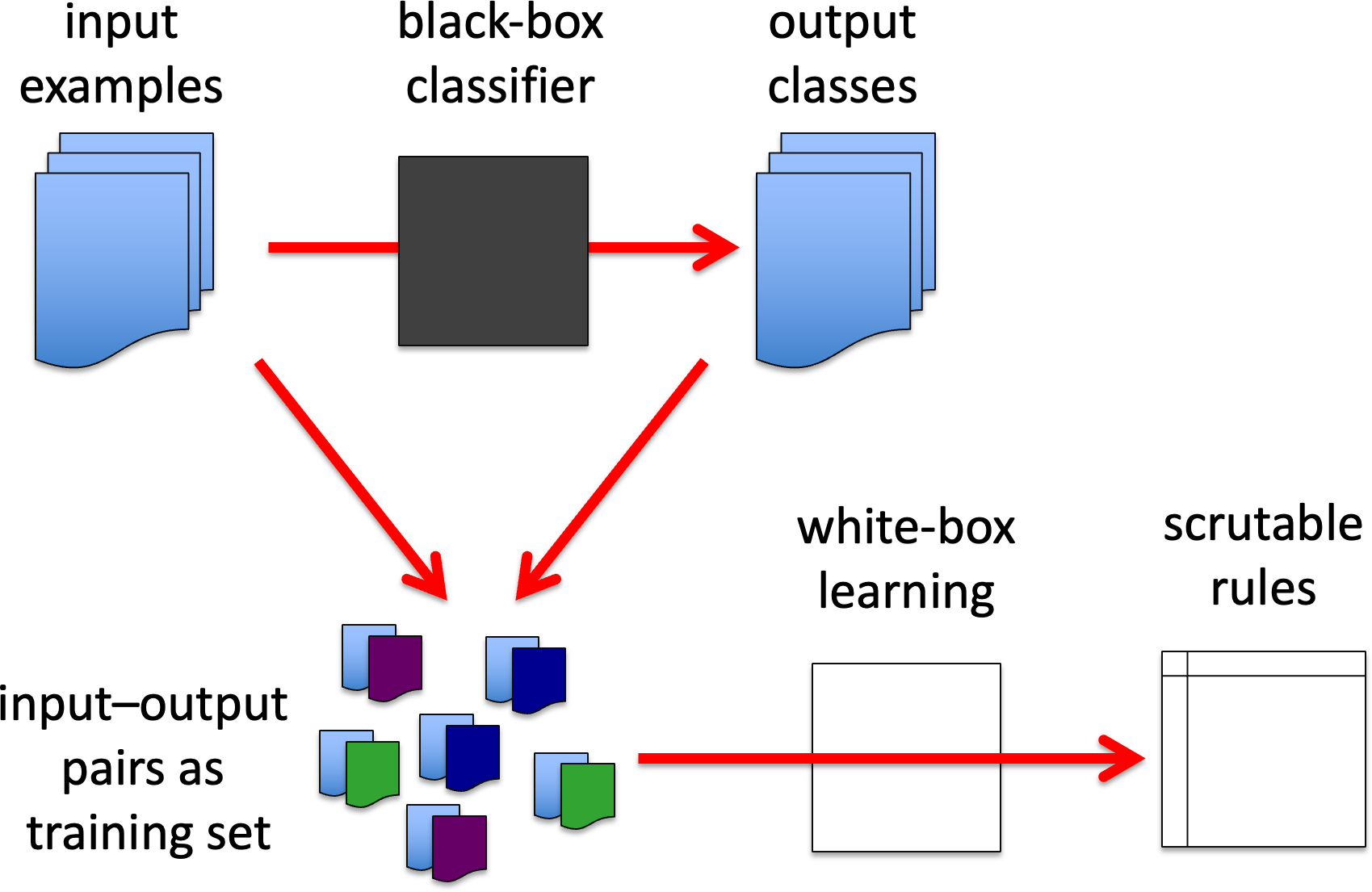
BB4. black-box oracle – white-box learning