
WB0. KISS
The simplest technique is to deliberately choose an algorithm that matches the domain and can be rendered in a comprehensible manner – for example the use of ID3 to generate SQL (via a decision tree) in Query-by-Browsing.
This is trivial, but has two slightly more interesting variants:
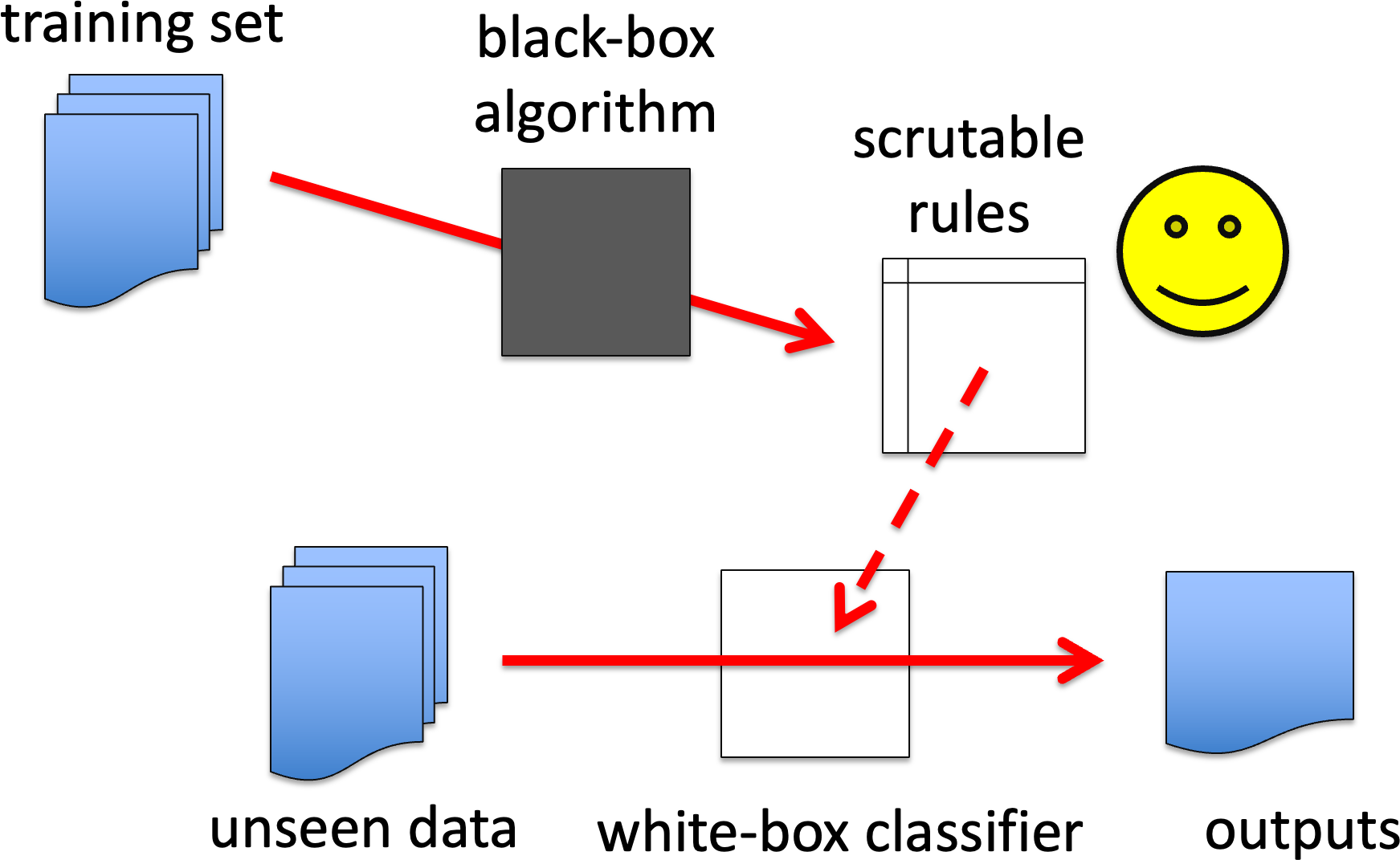
WB1. Black-box generation of white-box solution.
For example, one variant of QbB used genetic programming to generate decision trees, similarly genetic algorithms or similar techniques have been used to generate rule-based classifiers.
This is rather like the mathematician who can write the proof, but may struggle to explain how they came by it, or the programmer who creates the code, but may not be able to introspect their programming practice.
Note that it is may be easier to build in additional ‘comprehensibility’ goals into a fitness function for a black-box technique than it is to find a more procedural algorithm. For example, a variant of Quinlan’s ID3 generated long thin trees as it is easier to understand a set of conjunctive rules than a more balanced decision tree. To achieve this he had to make subtle tweaks to the ID3 algorithm, but in, say GA generation of decision trees you simple add tree shape as well as accuracy as part of the overall fitness function.
WB1. Black-box generation of white-box solution
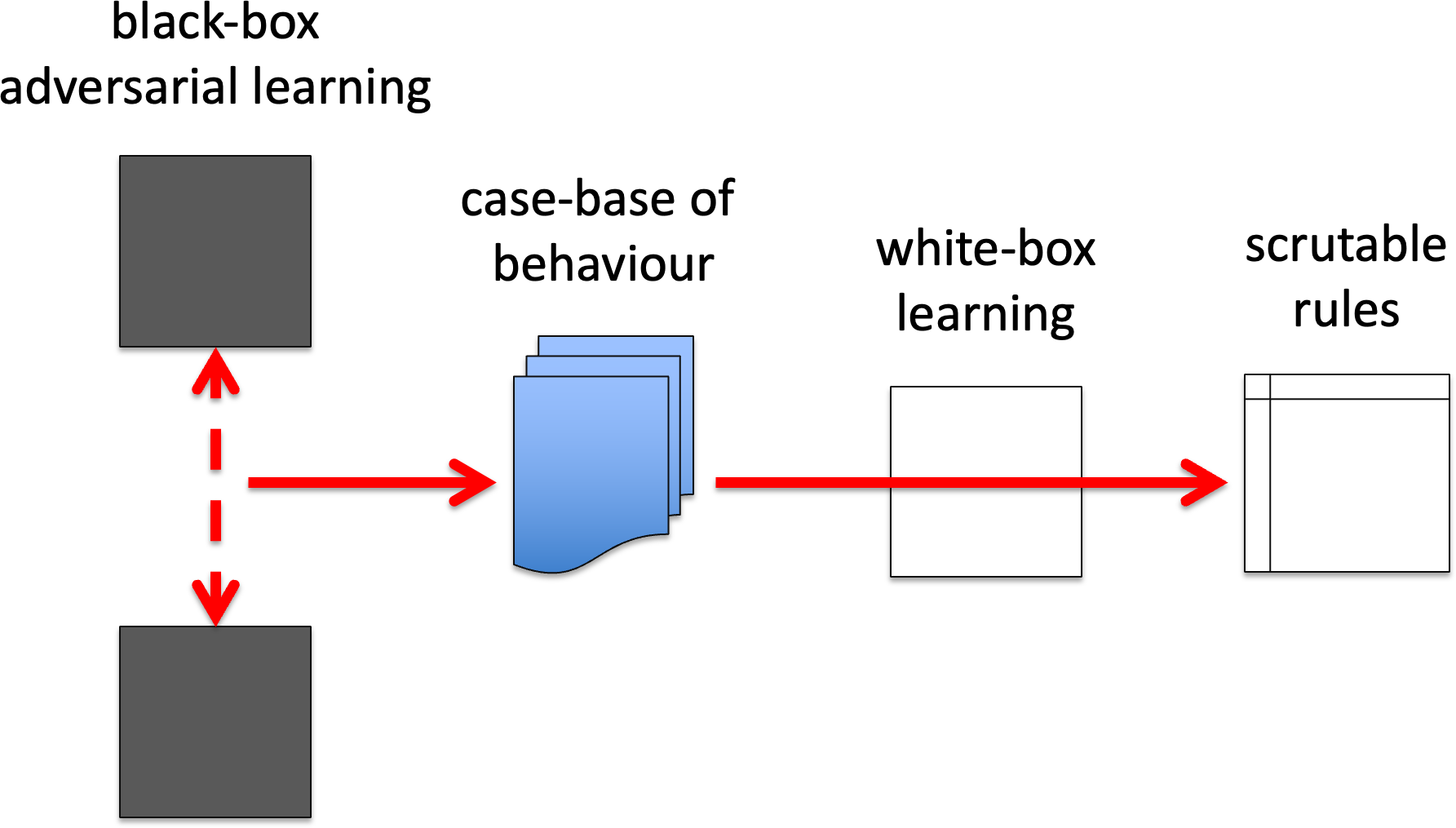
WB2. Adversarial examples for white-box learning.
Adversarial reinforcement learning (as used in AlphaGo) generates large case-base of examples. One of the problems with many knowledge rich ML techniques (especially ones that have a stochastic/uncertainty elements) were hamstrung as they often needed to work on small training sets, risking over-learning from repeated exposure to the same examples, and missing cases where there were none. Some classic techniques may well be able to be used more effectively on these large data sets, or variants created that were previously infeasible due to limited data. Hopefully a lot of the work for this is already in place because of big data; so in a way this is simply using the case base of behaviours generated from adversarial learning as a source of big data!
WB2. Adversarial examples for white-box learning
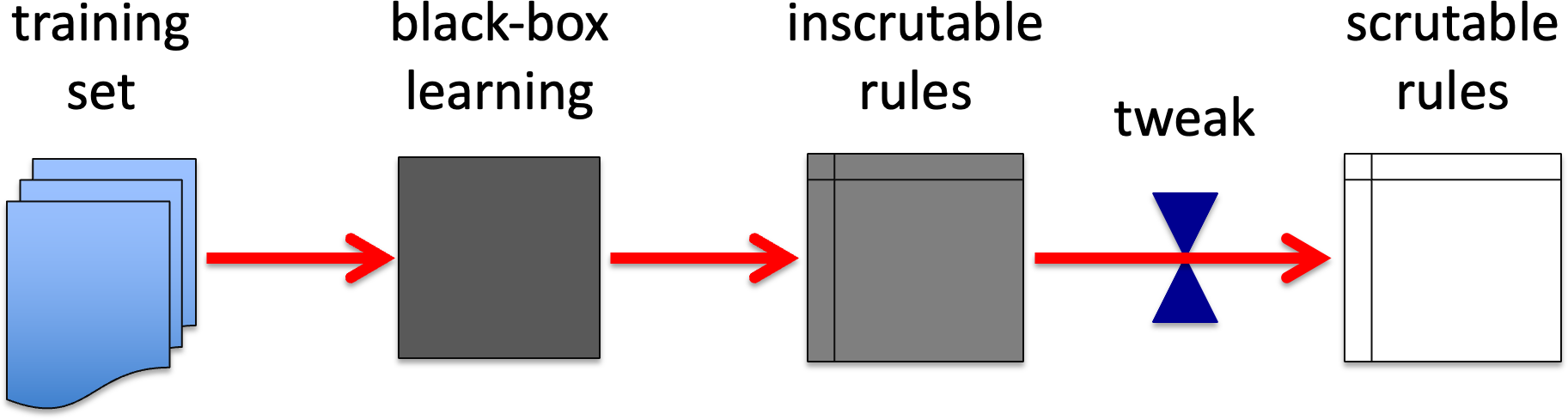
WB3. Simplification of rule set.
There was some early work on neural networks where the neurons were ‘hardened’ into binary networks after learning. The sigmoid activation function is necessary to ‘soften’ the network to allow back- propagation learning, but not needed for actual use (a standard heuristic of both human and computer learning is that it is often easier to learn continuous than discrete boundaries, so that you get an idea of ‘warmer’ rather than just right/wrong).
Note that sensitivity analysis, either using mathematical or algorithmic techniques can be used to help this process, for example, transforming sigmoids into either thresholds, linear scaling or more complex functions depending on ranges of (internal) inputs to the node on the training data. (See more later under grey-box techniques.)
WB3. Simplification of rule set