5. Problems, alternatives and future developments
As we said in the introduction,
there are two reasons for producing a prototype of Query-by-Browsing.
First we think Query-by-Browsing is a potentially powerful technique
for naïve database users.
However, we also want to investigate the potential problems
outlined in (Dix 1992) concerning the interaction between human users
and 'intelligent' systems.
The problems we have encountered are thus as valuable as the successes!
The discussion of these problems and potential future directions
is divided into those principally concerned with the learning algorithms
and those concerned with the user interaction.
However, the reader will notice that the separation is not perfect
and indeed, one would expect that the design of an effective system would
involve an intimate connection between the interface and the 'intelligent'
engine within.
Types of decision
We saw in the example above
how the naïve application of inductive learning
could come up with a spurious decision tree based on the title of the customer.
Note that this is not a wrong answer, it does explain the examples.
In general, there can be several different decision trees to explain
the same example set.
In the context of an interactive session this is not critical
as the user can always add more examples.
However, if the initial decisions are really obscure this can be both
confusing for the user and reduce the user's confidence in the system.
Even experiments using more knowledge rich learning algorithms have found that
automatically generated classification criteria are both different from
human criteria and hard for the human reader to comprehend (Hanson 1990).
This is a very difficult problem, but some of the very worst cases
can be addressed.
One reason for the production of obscure trees is that the number of examples
from browsing is relatively small compared with those generally expected
by inductive learning systems.
Indeed, one of Quinlan's papers includes the phrase
''large collections of examples'' in its title (Quinlan 1979)!
The small number of examples means that by the time one gets to the leaves of a
complex tree there may be only one or two records in each class on which
to base the learning.
Obviously these may be distinguished by virtually anything.
One solution to this is for the system to refrain from presenting a query
until it has a certain level of confidence in its solution.
A more interactive solution is for the system to assign confidence to
each leaf of a tree.
A possible measure to use for this is the 'gain ratio' as described in
(Quinlan 1988).
The system can then specifically mark those records (say with a question mark)
indicating to the user which records it would be useful for the user to
classify.
Alternatively, it could specifically ask the user 'do you want this record'.
Hopefully a small number of records classified in the uncertain areas of the
tree will serve to build a confidence and generate a robust query.
This sounds in fact very close to the interaction
of a user consulting a database expert who was constructing the query.
The expert would explicitly probe the boundaries of the query in order to
check that it was as required.
In order to make the query more 'human', the inductive learning
algorithm can be biased towards certain types of query.
For example, some of Quinlan's work on ID3 has investigated the biasing
of the algorithm towards degenerate trees - that is effectively conjunctive
queries and other forms of more comprehensible query (Quinlan 1986b).
ID3 is derived originally from the Concept Learning System and there
have been other algorithms developed in this area which learn different
sorts of rules, often including more complex domains.
This includes purely conjunctive and disjunctive formulas and
formulas based on 'internal disjunctive concepts' (Haussler 1990)
- that is, rules which are conjunctions of terms of the type:
'department = Accounts or Computing'.
Whereas ID3 will return any tree which separates the classes,
some algorithms will give the most specific rule to specify the
positive examples.
That is a rule which includes everything which is true about all of
the examples.
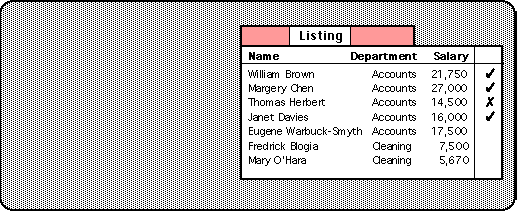
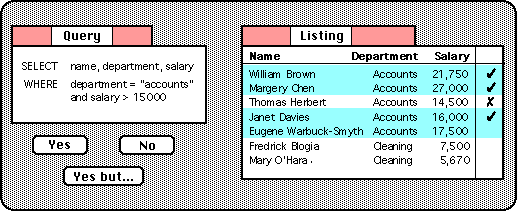
The query shown in Figure 2 is of this form.
The examples shown can be classified by the criterion 'salary > 1500',
but the most specific rule also includes the fact that all the positive
examples are also in the accounts department:
'department = Accounts and salary > 1500'
In order to make ID3 give this query
negative examples had to be given in other departments (not shown
on the screen shot).
In principle, a system using most specific criteria can learn mainly from
positive examples, which would probably lead to a more natural interaction
style for the user.
In addition, we may want to add some knowledge to the learning process.
For example, in a banking system we may bias the system to favour queries
dependent on monetary fields over those using personal attributes such as title
or address.
In (Dix 1992) it was argued that inadvertent discrimination
was a danger of the use of example based approaches.
QbB clearly portrays what decisions are being made which reduces
(but does not eliminate) this problem.
Despite these dangers, it is likely that knowledge should be in the form of
a bias rather than a prohibition.
For example, a bank's market research may have shown that its male
middle-earning customers are likely to purchase redundancy insurance and
so it may want to send insurance brochures to that group. (Whether
such direct mailing is socially acceptable is, of course,
questionable in itself.)
There has been little work on such hybrid learning systems which employ a
combination of rich knowledge with relatively 'blind' techniques such as
inductive learning (Michalski and Kodratoff 1990).
However, fairly simple techniques should be sufficient to improve the
performance of QbB.
In fact, the current implementation does employ some minimal general knowledge
in that when making integer comparisons it chooses nice numbers.
For example, in Figure 2, the examples have a ticked
record with salary Ł1600 and a crossed one of Ł1450.
Rather than choosing the midpoint of these Ł1525 the algorithm
instead chooses the round number Ł1500.
Finally, in this area it is worth emphasising the unsuitability of
neural networks as the primary mechanism for QbB.
Although they can be highly effective as classifiers, the nature of
their decision making is such that they must be regarded as 'black box'
methods.
It would be virtually impossible to generate a readable query from standard
networks, thus ruling out a dual representation.
That is, they are possibly acceptable in imprecise domains, but not where
the user needs confidence that the classification performed by the system
is exactly as required.
Complex interaction
The difficulties with interaction come when the system gets the wrong
query.
The 'no' button is particularly problematical as it gives no indication
of what is wrong.
Such an answer would be rather rude if delivered to a human expert, but perhaps
one of the advantages of a computer assistant is that one can be as rude as one
likes!
At present the 'no' answer means that the system never displays that precise
query again.
However, this might involve a long period of inactivity as the additional examples
that the user enters may all agree with the incorrect query.
As the inductive learning algorithm is deterministic the system will keep on
coming up with the same tree until an example is given which disagrees with it.
There are two ways out of this impasse.
The user can be encouraged to select helpful records by continuing to show
the highlighting of the incorrect query.
This will suggest marking which of the highlighted records aren't wanted and
which of the unhighlighted ones are wanted.
The other option is to alter the algorithm so that it finds a different tree
to explain the examples.
One way to achieve this is to make the algorithm slightly random, so that
repeated invocations are likely to give different trees.
Although deliberately making the interface non-deterministic sounds rather
extreme, there are situations when it can be extremely effective
(Dix 1991).
QbB is an example of a
system where autonomous intelligent agents interact with the user.
General interface guidelines for such systems are given in (Dix, Finlay et al. 1994).
In particular, it is important that it is clear which interface objects
(windows, buttons, etc.)
are under the control of the user, which belong to the agents, and which
are under shared control.
We can apply this analysis to the present QbB system.
The listing window is a shared object where the user controls
the marking and the agent (inductive learning component) controls the
highlighting.
The labelled buttons are a communication medium from the user to the agent
and the query window is a form of communication from the agent to the user
(not to forget that the shared listing window is also a medium of
communication).
However, if we want to allow continuity between the novice, example based
interface and an expert, query based interface, it suggests that the
query window should also be shared and that the user ought to be able to
make contributions there as well as to the listing.
For example, imagine the query generated in Figure 2 was correct
except that the criterion the user was really after was those with salary
over Ł1550.
Rather than trying to find examples to force the system to the correct
value, the user might find it easier to simply edit the query.
However, in such cases the system would have to remember which bits of the
query had been generated by the user and which by the system so that
subsequent work by the inductive learning agent does not overwrite the user's
work.
This could be achieved by marking some of the tree's nodes as fixed.
6. Summary
We have described Query-by-Browsing a novel database query mechanism
where the system generates the query.
As opposed to traditional Query-by-Example, QbB really does work by example.
The dual representation of the system's query by highlighting the selected
records and by textual representation ensures that the user understands both
the specific and general implications of the query.
In addition, dual representation may serve an important tutoring rôle for
the naïve user.
The current prototype exposes various shortcomings, several of which had been
predicted in previous work.
It serves as an exemplar of the general design problems where interfaces
include autonomous intelligent agents.
The prototype demonstrates the care and attention to detail which is needed
in the design of such systems.
In particular, it emphasises the close connection between the nature of the
underlying algorithms and the details of user interaction.
We believe that Query-by-Browsing is a promising
method which we hope will one day be included in many database systems alongside
QBE and SQL queries.
7. References
- A. Dix (1992). Human issues in the use of pattern recognition techniques. In Neural Networks and Pattern Recognition in Human Computer Interaction, Eds. R. Beale and J. Finlay. Ellis Horwood. pp. 429-451.
- A. Dix, J. Finlay and J. Hassell (1994). Environments for cooperating agents: Designing the interface as medium. In CSCW and Artificial Intelligence, Eds. J. Connolly and E. Edmonds. Springer Verlag. pp. 23-37.
- A. J. Dix (1991). Formal Methods for Interactive Systems. Academic Press.
- P. W. Foltz (1990). Using latent semantic indexing for information filters. Proceedings of the Conference on Office Information Systems, . pp. 40-47.
- S. J. Hanson (1990). Conceptual clustering and categorisation: Bridging the gap between induction and causal models. In Machine Learning: An Artificial Intelligence Approach, . Morgan Kaufmann. pp. 235-268.
- D. Haussler (1990). Applying Valient's learning framework to AI concept-learning problems. In Machine Learning: An Artificial Intelligence Approach, . Morgan Kaufmann. pp. 641-669.
- R. S. Michalski and Y. Kodratoff (1990). Research in machine learning: recent progress, classification of methods, and future directions. In Machine Learning: An Artificial Intelligence Approach, . Morgan Kaufmann. pp. 3-30.
- J. R. Quinlan (1979). Discovering rules by induction from large collections of examples. In Expert Systems in the Micro-Electronic Age, Ed. D. Michie. Edinburgh University Press. pp. 168-201.
- J. R. Quinlan (1986a). Induction of decision trees. Machine Learning, 1(1) pp.
- J. R. Quinlan (1986b). Simplifying decision trees. International Journal of Man-Machine Studies, 27(4) pp. 221-234.
- J. R. Quinlan (1988). Decision trees and multi-valued attributes. In Machine Intelligence 11, . Oxford University
Press. pp. 305-318.
- A. Sharif Heger and B. V. Koen (1991). Knowbot: An adaptive database interface. Nuclear Science and Engineering, 107 pp. 142-157.
- M. M. Zloof (1975). Query by example. Proc. AFIPS National Computer Conf. 44, . AFIPS Press, New Jersey. pp. 431-438.