MapReduce is a distributed computing framework for dealing with big data. It is inspired by the map and reduce functions found in Lisp and other functional programming languages: the map stage initially processes each item of data separately and then the reduce stage collects and aggregates related intermediate results. However, MapReduce has two crucial additional features : (i) the use of a hash as means to distribute intermediate results over different computers, so reducing the likelihood of Byzantine conditions; and (ii) means to monitor for failure of individual computers and recover from this, so making it overall more robust to failure.
.
| each data item | → | map | → | hash + processed data |
| all data for a hash | → | reduce | → | one or more agggregated calculations for the hashed data (possibly including fresh hash for further reduce steps) |
MapReduce was initially developed by engineers at Google, but has since become part of the open source Apache Hadoop project.
Used in Chap. 8: pages 110, 111, 112, 113, 114, 115, 116; Chap. 23: page 360
Used in glossary entries: Apache Hadoop, big data, Byzantine conditions, Lisp, map, reduce, robust to failure
Links:
 ACM Digital Library: MapReduce: simplified data processing on large clusters
ACM Digital Library: MapReduce: simplified data processing on large clusters- hadoop.apache.org: Apache Hadoop
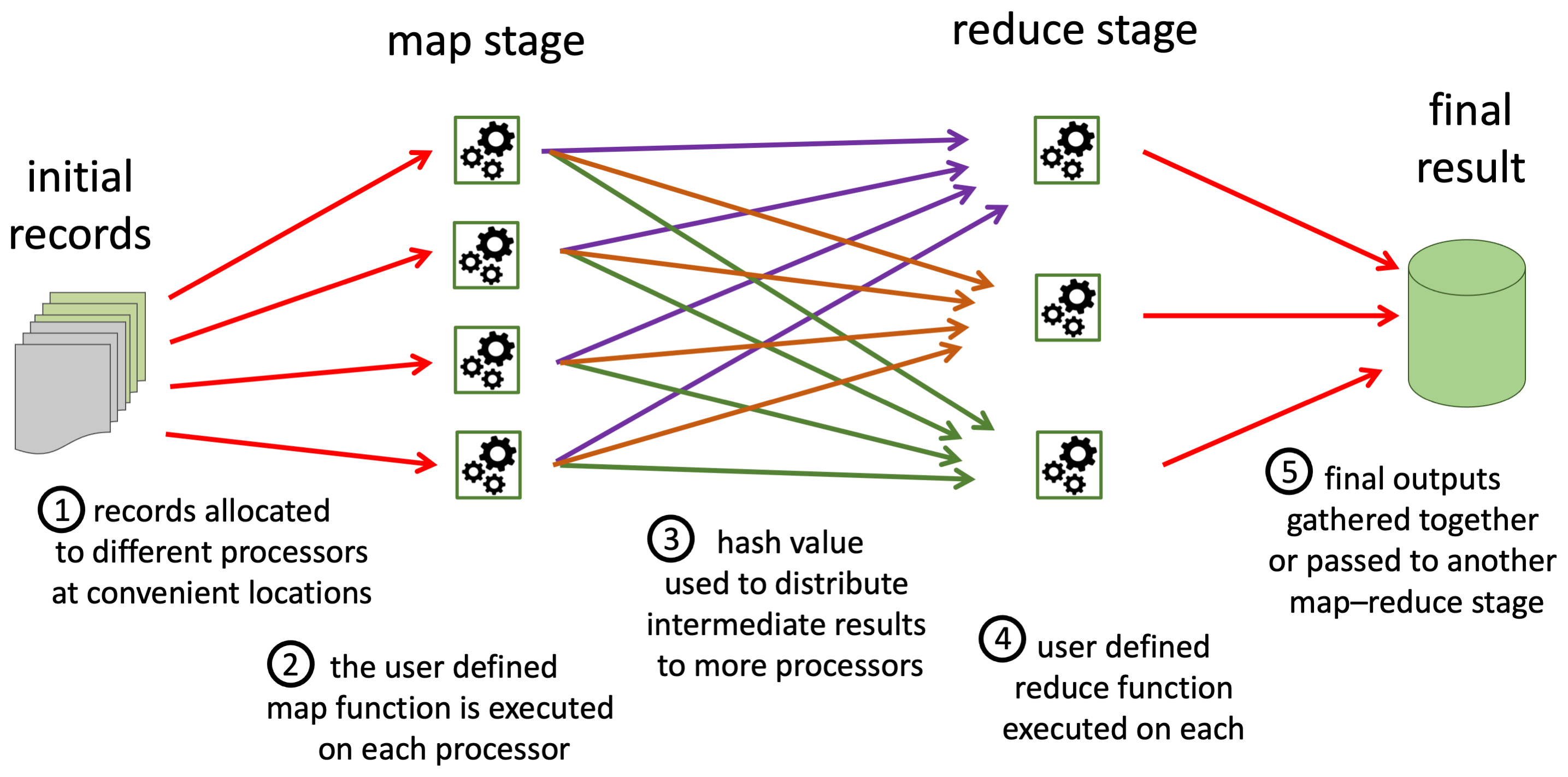
MapReduce distributed computation pipeline