
 As well as choosing who we ask to participate in our users studies, we can manipulate what we ask them to do, the experimental or study tasks.
As well as choosing who we ask to participate in our users studies, we can manipulate what we ask them to do, the experimental or study tasks.
We will look at four strategies
- distractor tasks (increase effect)
- targeted tasks (increase effect)
- demonic interventions! (increase effect)
- reduced vs wild (reduce noise)
Notably missing are strategies about increasing the number of tasks. While this is possible, and indeed often desirable, the normal reason for this is to increase the diversity of contexts under which you study a phenomenon. Often the differences between tasks are so great it is meaningless to in any way do aggregate statistics across tasks, instead comparisons are made within tasks, with only broad cross-tasks comparisons, for example, f they all lead to improvements in performance.
Typically too, if one does want to aggregate across tasks, the models you take have to be non-linear – if one task takes twice as long as another task, typically variations in it between subjects or trials are also twice as large, or at least substantially larger. This often entails multiplicative rather than additive models of each task’s impact.
One of the strategies for subjects was to choose a group, say novices, for whom you believe effects will be especially apparent; effects that are there for everyone, but often hidden.
Distractor tasks perform a similar role, but by manipulating the user’s experimental task to make otherwise hidden differences obvious. They are commonly used in ergonomics, but less widely so in HCI or user experience studies; however, they offer substantial benefits.
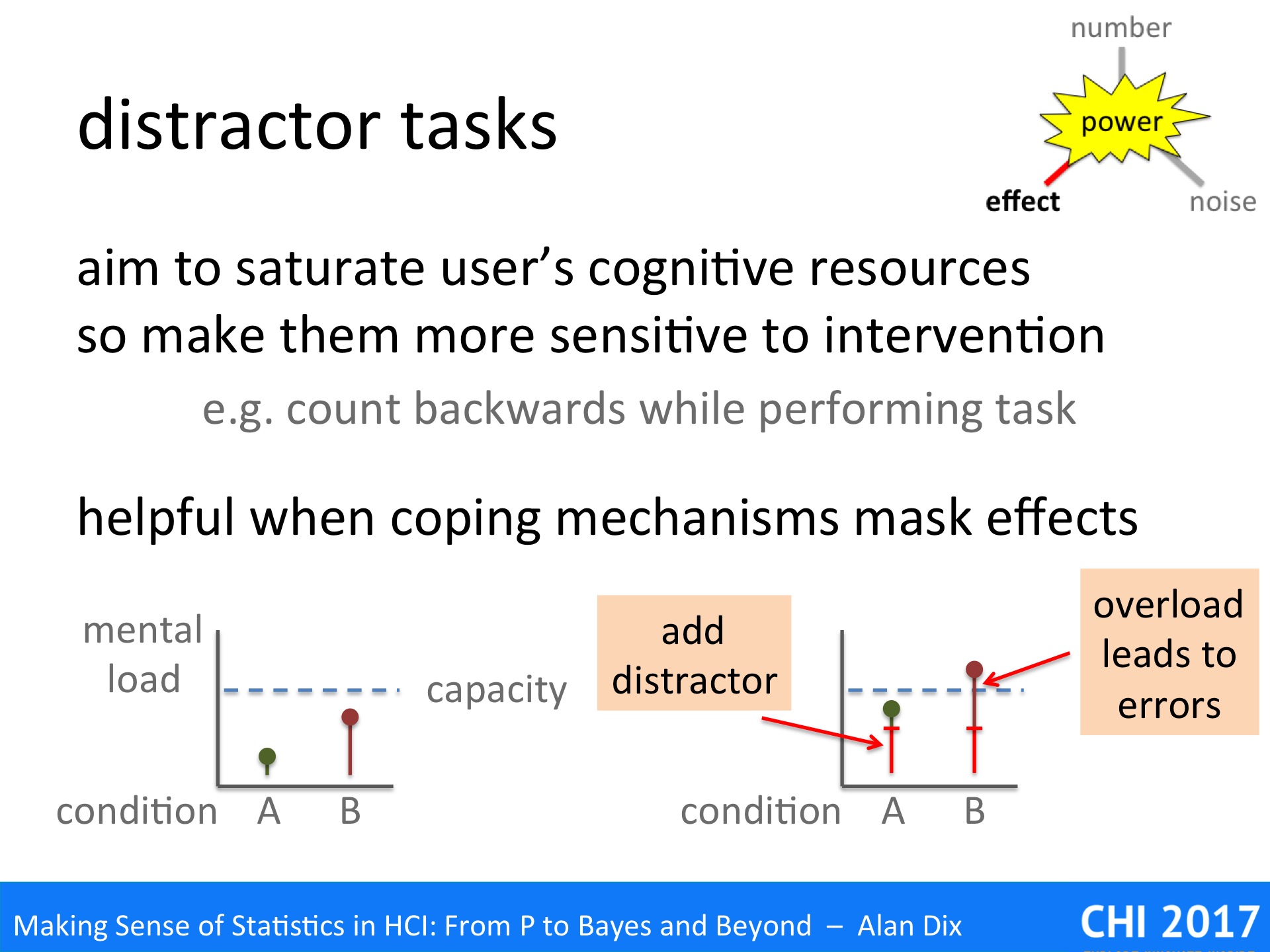
A distractor task is an additional task given during an experimental situation, which has the aim of saturating some aspect of the user’s cognitive abilities, so that differences in load of the systems or conditions being studied become apparent.
A typical example for a usability study might be to ask a subject to count backwards whilst performing the primary task.
The small graphs show what is happening. Assume we are comparing two systems A and B. In the example the second system has a greater mental load (graph on the left), but this is not obvious as both are well within the user’s normal mental capacity.
However, if we add the distractor task (graph on the right) both tasks become more difficult, but system B plus the distractor now exceed the mental capacity leading to more errors, slower performance, or other signs of breakdown.
The distractor task can be arbitrary (like counting backwards), or ecologically meaningful.
I first came across distractor tasks when I worked in an agricultural research institute. There it was common when studying instruments and controls to be installed in a tractor cab to give the subjects a steering task, usually creating a straight plough furrow, whilst using the equipment. By increasing the load of the steering task (usually physically or in simulation driving faster), there would come a point when the driver would either fail to use one of the items of equipment properly, or produce wiggly furrows. This sweet spot, when the driver was just on the point of failure, meant that even small differences in the cognitive load of the equipment under trial became apparent.
A similar HCI example of an ecologically meaningful distractor task is in mobile interface design, when users are tested using an interface whilst walking and avoiding obstacles.
Distractor tasks are particular useful when people employ coping mechanisms. Humans are resilient and resourceful; when faced with a difficult task they, consciously or unconsciously, find ways to manage, to cope. Alternatively it may be that they have sufficient mental resources to deal with additional effort and never even notice.
Either way the additional load is typically having an effect, even when it is not obvious. However, this hidden effect is likely to surface when the user encounters some additional load in the environment; it may be an event such as an interruption, or more long-term such as periods of stress or external distractions. In a way, the distractor task makes these obvious in the more controlled setting of your user study.

Just as we can have targeted user groups, we can also choose targeted tasks that deliberately expose the effects of our interventions.
For example, if you have modified a word-processor to improve the menu layout and structure, then it makes sense to have a task that involves a lot of complex menu navigation rather than simply typing.
If you have a more naturalistic task, then you may try to instrument it so that you can make separate measurements and observations of the critical parts. For example, in the word-processor your logging software might identify when menu navigation occurs for different functions, log this, and then create response-time profiles for each so that the differences in, say, typing speed in the document itself do not drown out the impact of the menu differences.
Of course this kind of targeting, while informative, can also be misleading, especially in a head-to-head system comparison. In such cases it is worth also trying to administer tasks where the original system is expected perform better than your new, shiny favourite one. Although, it is worth explaining that you have done this, so that reviewers do not take this as evidence your new system is bad! (more on this in part 4 “so what?”)
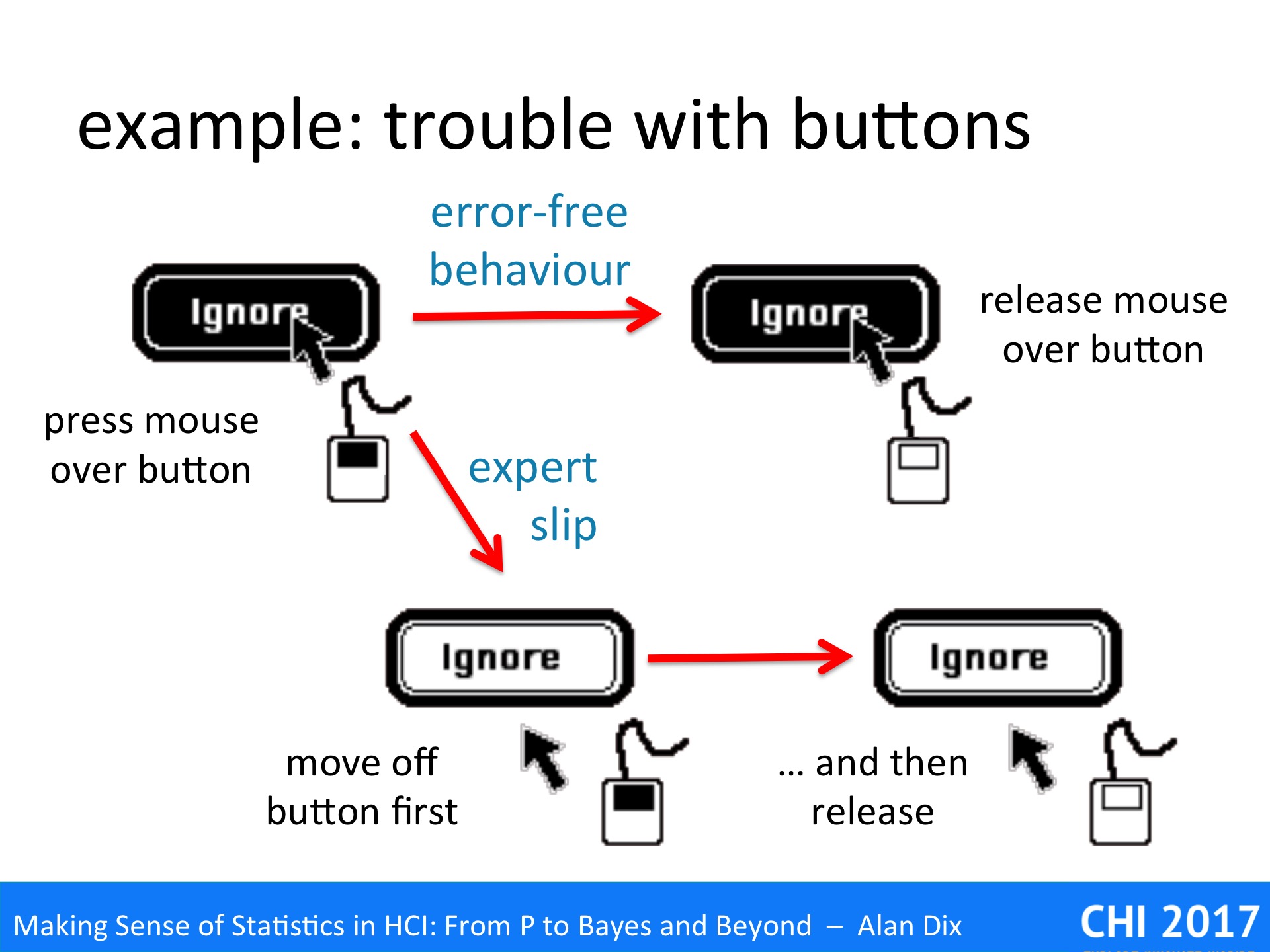
Some years ago I was involved in a very successful example of this principle. Steve Brewster (now Glasgow) was looking at possible sonic enhancement of buttons [DB94]. One problem he looked at was an expert slip, that is an error that experts make, but does not occur with novice use. In this case highly experienced users would occasionally think they had pressed a button to do something, not notice they had failed, and then only much later discover the impact. For example, if they had cut a large body of text and thought they had pasted it somewhere, but hadn’t, then the text would be lost.
Analysing this in detail, we realised that the expert user would almost certainly correctly move the mouse over the button and press it down. Most on-screen buttons allow you to cancel after this point by dragging your mouse off the button (different now with touch buttons). The expert slip appeared to be that the expert started to move the mouse button to quickly as they started to think of the next action.

Note a novice user would be less likely to have this error as they would be thinking more carefully about each action, whereas experts tend to think ahead to the next action. Also novices would be more likely to verify the semantic effect of their actions, so that, if they made the slip, they would notice straight away and fix the problem. The expert slip is not so much making the error, but failing to detect it.
Having understood the problem a sonic enhancement was considered (simulated click) that it was believed would solve or at east reduce the problem. However, the problem was that this was an expert slip; it was serious when it occurred, but was very infrequent, perhaps happening only once every month or so.
Attempts to recreate it in a short 10 minute controlled experiment initially failed dramatically. Not only was it too infrequent to occur, even experts behaved more like novices in the artificial environment of a lab experiments, being more careful about their actions and monitoring the results.
One option in the current days of mass web deployment and perpetual beta, would be to have tried both alternatives as an A-B test, but it would be hard to detect even with massive volume as it was such an infrequent problem.
Instead, we turned back to the analysis of the problem and then crafted a task that created the otherwise infrequent expert slip. The final task involved typing numbers using an on-screen keyboard, clicking a button to confirm the number, and then moving to a distant button to request the next number to type. The subjects were put under time pressure (another classic manipulation to increase load), thus maximising the chance that they would slip off the confirm button whilst starting to move the mouse towards the ‘next’ button.
With this new task we immediately got up to a dozen missed errors in every experiment – we had recreated the infrequent expert slip with high frequency and even with novices. When the sonic enhancement was added, slips still occurred, but they were always noticed immediately, by all subjects, every time.

In the extreme one can produce deliberately tasks that are plain nasty!
One example this was in work to to understand natural inverse actions [GD15]. If you reverse in a car using your mirrors it is sometimes hard to know initially which way to turn the steering wheel, but if you turn and it is the wrong direction, or if you over-steer, you simply turn it the opposite way.
We wanted to create such a situation using effectively a Fitts’ Law style target acquisition tasks, with various mappings between two joysticks (in left and right hand) and on-screen pointers. The trouble was that when you reach for something in the real world, you tend to undershoot as overshooting would risk damaging the thing or injuring yourself. This behaviour persists even with an on-screen mouse pointer. However, we needed overshoots to be able to see what remedial action the participants would take.
In order to engineer overshoots we added a substantial random noise to the on-screen movements, so that the pointer behaved in an unpredictable way. The participants really hated us, but we did get a lot of overshoots!
Of course, creating such extreme situations means there are, yet again, problem of generalisation. This is fine if you are trying to understand some basic cognitive or perceptual ability, but less so if you are concerned with issues closer to real use. There is no magic bullet here, generalisation is never simply hand-turning algorithms on data, it is always a matter of the head – an argument based on evidence, some statistical, some qualitative, some theoretical, some experiential.

One of the on-going discussions in HCI is the choice between ‘in-the-wild’ studies [RM17] or controlled laboratory experiments. Of course there are also many steps in between, from semi-realistic settings recreated in a usability labs, to heavily monitored use in the real world.
In general the more control one has over the study, the less uncontrolled variation there is and hence the noise is smaller. In a fully in the wild setting people typically select their own tasks, may be affected by other people around, weather, traffic, etc. Each of these introduces variability.
However, one can still exercise a degree of control, even when conducting research in the wild.
One way is to use reduced tasks. Your participants are in a real situation, their home, office, walking down the street, but instead of doing what they like, you give them a scripted task to perform. Even though you lose some realism in terms of the chosen task, at least you still a level of ecological validity in the environment. These controlled tasks can be interspersed with free use, although this will introduce its own potential for interference as with within subjects experiment.
Another approach is use a restricted device or system. For example, you might lock a mobile phone so that it can only use the app being tested. By cutting down the functionality of the device or application, you can ensure that free use is directed towards the aspects that you wish to study.
A few years ago, before phones all had GPS, one proposed mode of interaction involved taking a photograph and then having image recognition software use it to work out what you were looking at in order to offer location-specific services, such as historical information or geo-annotation [WT04].
Some colleagues of mine were interested in how the accuracy of the image recognition affected the user experience. In order to study this, they modified a version of their mobile tourist guide and added this as a method to enable location. The experimental system used Wizard of Oz prototyping: when the user took a photograph, this was sent to one of the research team who was able to match it against the actual buildings in the vicinity. This yielded a 100% accurate match, but the system then added varying amounts of random errors to emulate automated image recognition.
In order to ensure that the participants spent sufficient time using the image location part, the functionality of the mobile tourist guide was massively reduced, with most audio-visual materials removed and only basic textual information retained for each building or landmark. By doing this, the participants looked at many different landmarks, rather than spending a lot of time on a few, and thus ensured the maximum amount of data concerning the aspect of interest.
The rather concerning downside of this story is that many of the reviewers did not understand this scientific approach and could not understand why it did not use the most advanced media! Happily it was eventually published at mobileHCI [DC05].
References
[DC05] N. Davies, K. Cheverst, A. Dix and A. Hesse (2005). Understanding the Role of Image Recognition in Mobile Tour Guides Proceedings of MobileHCI’2005. ACM Press, pp 191-198 https://alandix.com/academic/papers/MobileHCI2005-camera/
[DB94] A. Dix and S. A. Brewster (1994). Causing Trouble with Buttons. Ancilliary Proceedings of HCI’94, Glasgow, Scotland. Ed. D. England. https://alandix.com/academic/papers/buttons94/
[GD15] Masitah Ghazali, Alan Dix and Kiel Gilleade (2015). The relationship of physicality and its underlying mapping. In 4th International Conference on Research and Innovation in Information Systems 2015, 8-10 December 2015, Malacca (best paper award). Also published in ARPN Journal of Engineering and Applied Science, December 2015, Vol. 10 No. 2). https://alandix.com/academic/papers/ICRIIS-2015-physicality/
[RM17] Yvonne Rogers and Paul Marshall (2017). Research in the Wild. Synthesis Lectures on Human-Centered Informatics. Morgan Claypool. DOI: 10.2200/S00764ED1V01Y201703HCI037
[WT04] Wilhelm, A., Takhteyev, Y., Sarvas, R., Van House, N. and Davis. M.: Photo Annotation on a Camera Phone. Extended Abstracts of CHI 2004. Vienna, Austria. ACM Press, 1403-1406, 2004. DOI: 10.1145/985921.986075