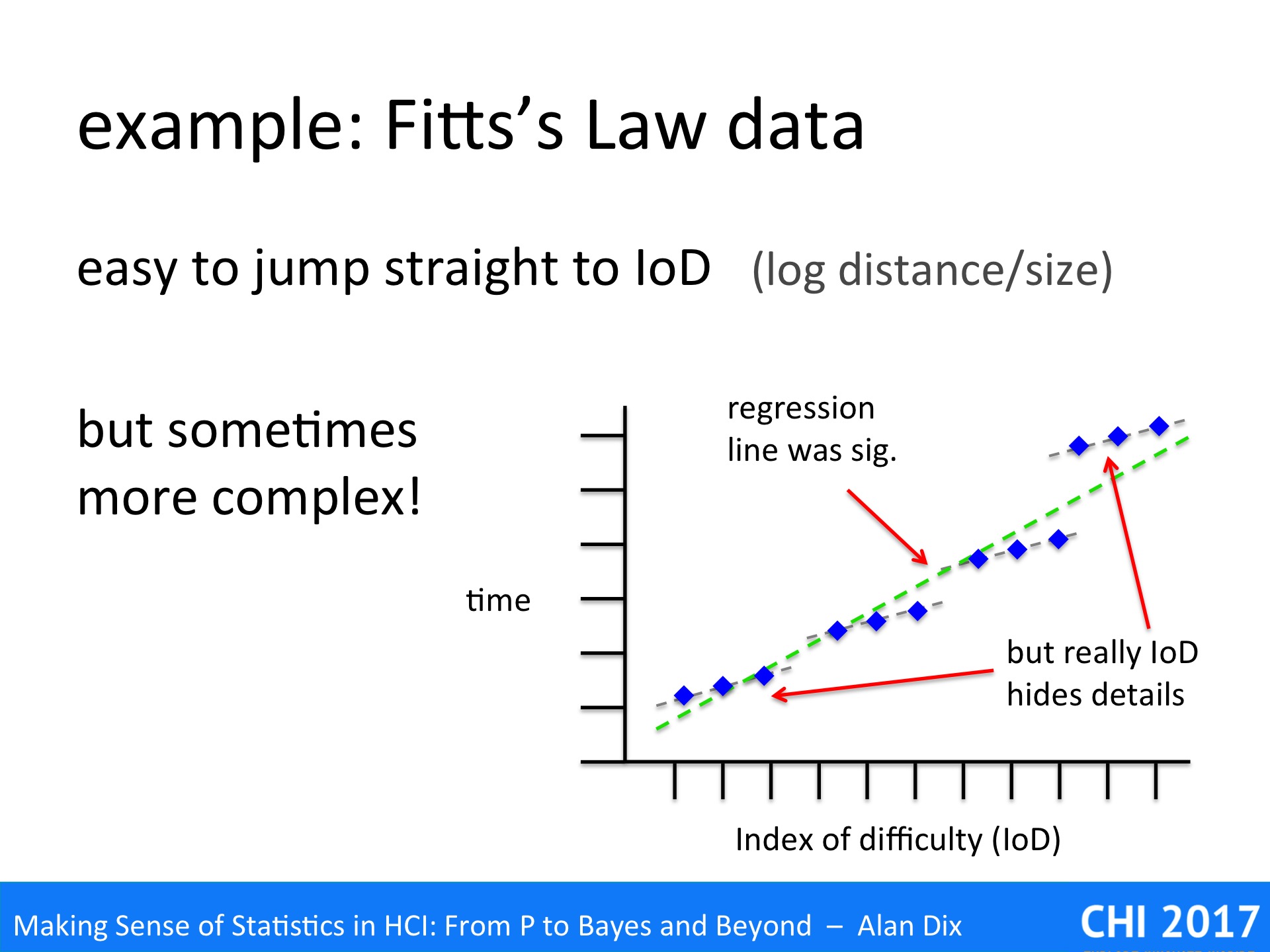
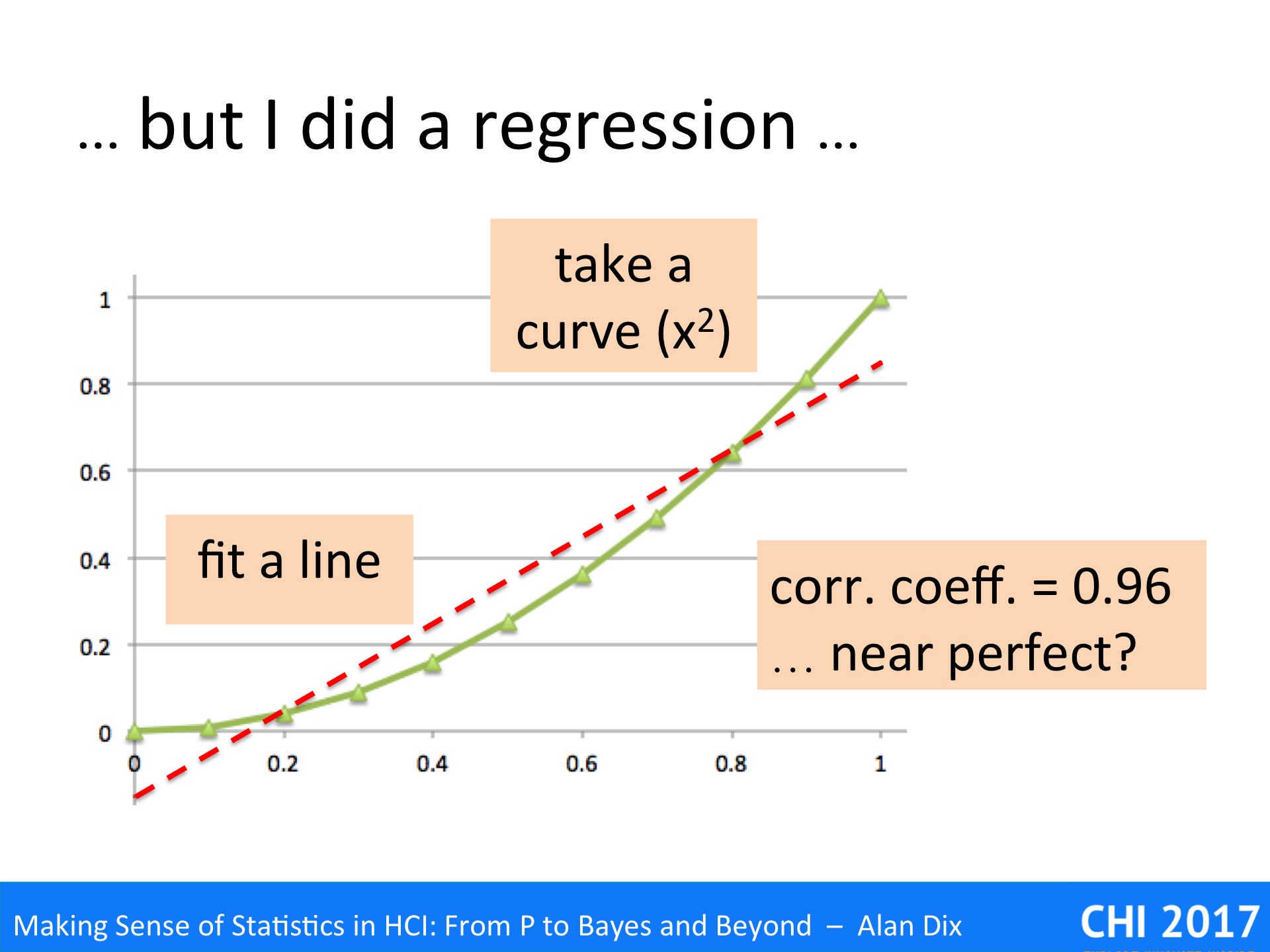
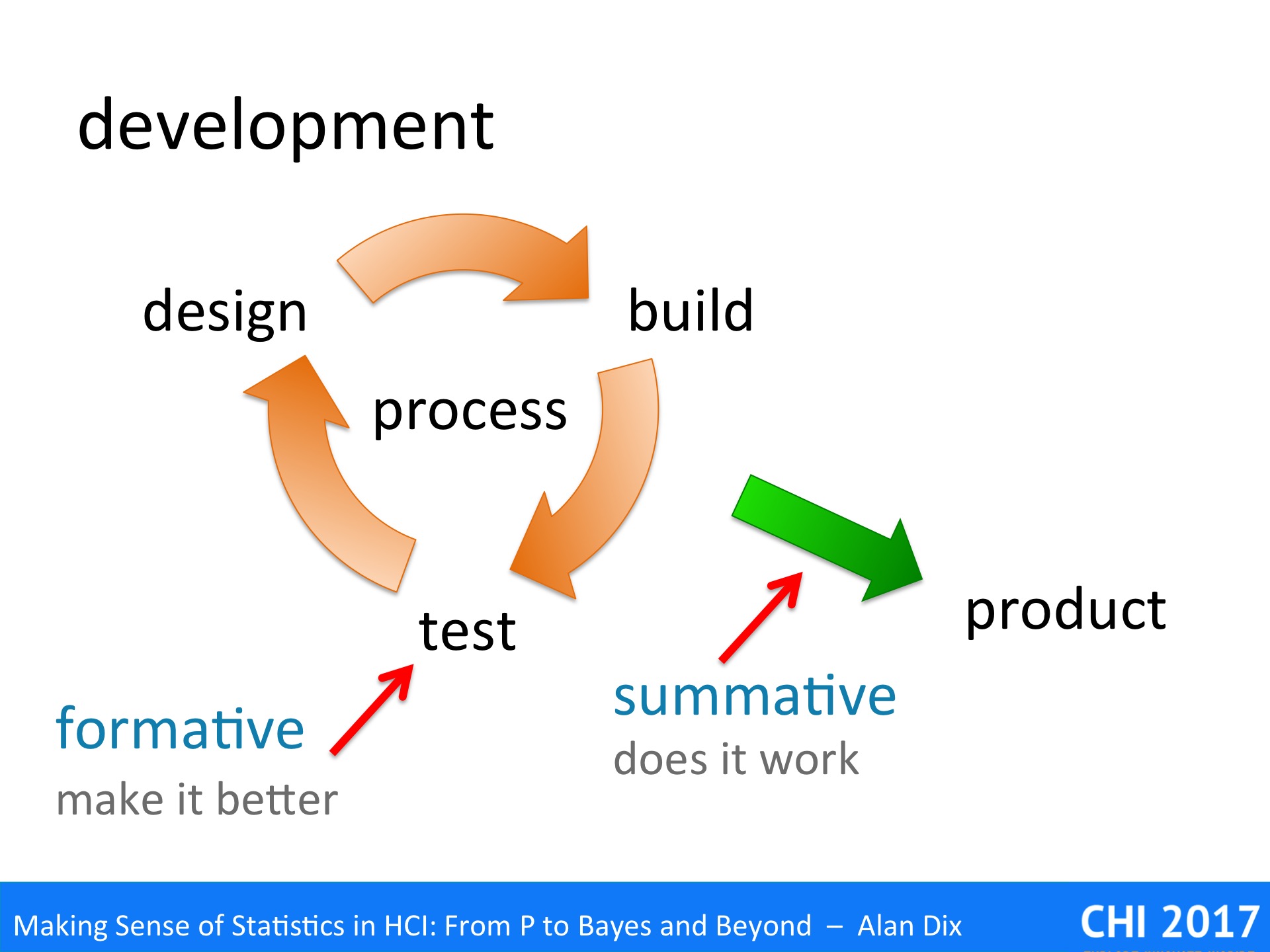
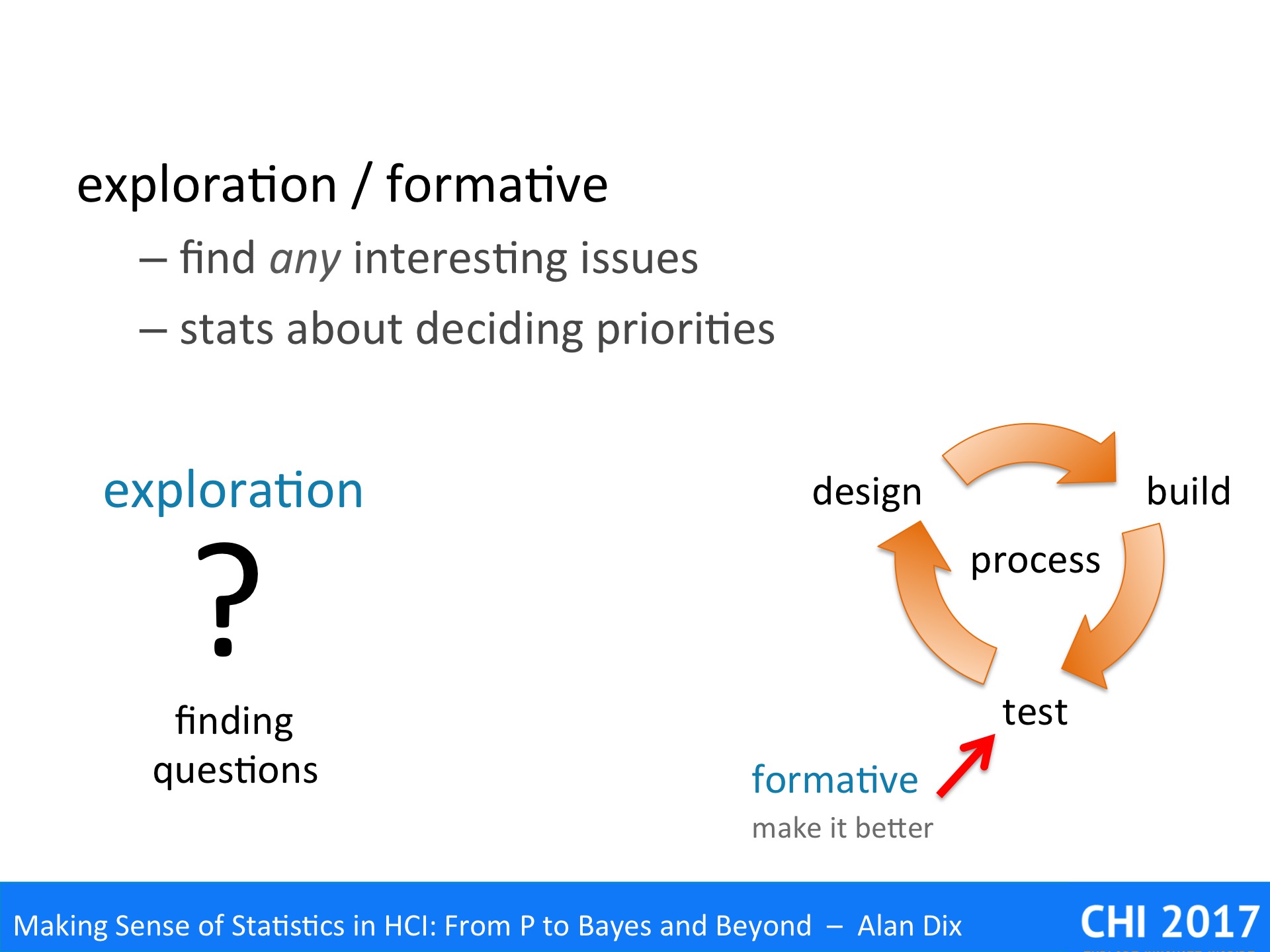
Statistics is largely about assessing and validating measured values, but what do they actually measure?
Statistics is largely about assessing and validating measured values, but what do they actually measure?
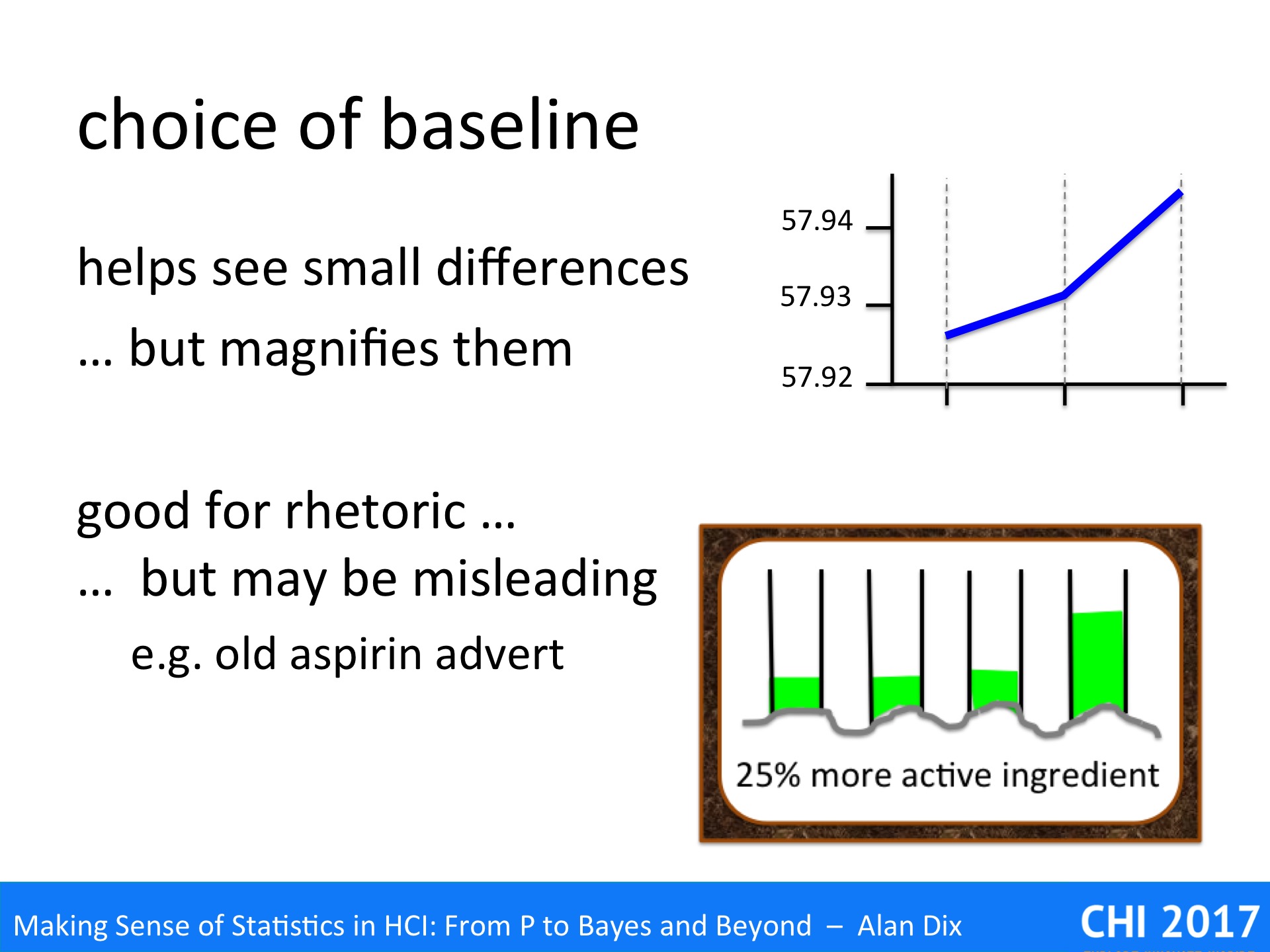
Thinking about the conditions – what have you really shown – some general result or simply that one system or group of users is better than another?
In an example we will look at how a paper published at a major ACM conference appeared to be demonstrating the value of a particular kind of interaction style for a particular problem, but may simply be that they chose a particularly bad system as one of their experimental conditions.

Imagine you have got good data and a gold standard p-value. You are about to rite in your conclusions that using reverse alphabetic menus leads to faster access times than other layouts. However, before you commit, ask yourself “what else might have cased this result”. Maybe the tasks you used tended to include a lot of items starting with x, y and z?
If you find alternative explanations you might be able to look at your data in a different way to tease out the difference between your original hypothesis and the alternatives. Can’t this would be an opportunity to plan a new experiment that exposes the difference.
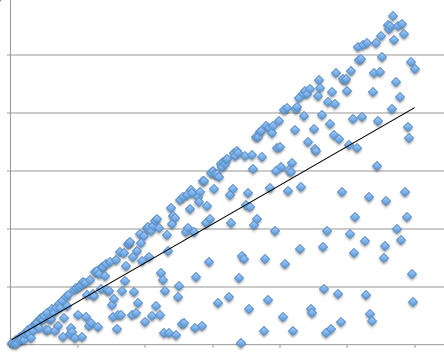
It is easy to get confused between things that are true about your subjects and things that are true generally. Imagine you have a mobile phone app for amusement parks that offers games for families to play together while they wait in the queue for a ride. You give the app to four families who have new app and also have a small clicker device where they are asked at intervals whether or not they are happy. The families visit many rides during the day and you analyse the data to see whether they are more happy while waiting in queues that have a game compared with those that don’t. Again you get a gold standard p-value and feel you are ready to publish.
However, if you had a small number of families, and a lot of data per family, what your statistics have probably told you is that you can accurately say for those four families, that they are, on average, happier when they play the app games. However, this is a reliable result about a few families, not a general result about all families; for that you would need far more families and different statistical analysis.
Perhaps even harder to spot because it is so common is to confuse results about specific systems with results about the properties they embody.

To illustrate this we’ll look at a little story from a few years ago.
It was a major ACM conference and the presentation of, what appeared to be, a good empirical paper. The topic was tools to support a collaborative task which we’ll call ‘X’.
The researchers were interested in two main factors:
- domain specific for task X vs more generic software
- synchronous vs asynchronous collaboration
They found three pieces of existibg siftware that covered three of the four slots’ in the design space:
- A – domain specific software, synchronous
- B – generic software, synchronous
- C – generic software, asynchronous
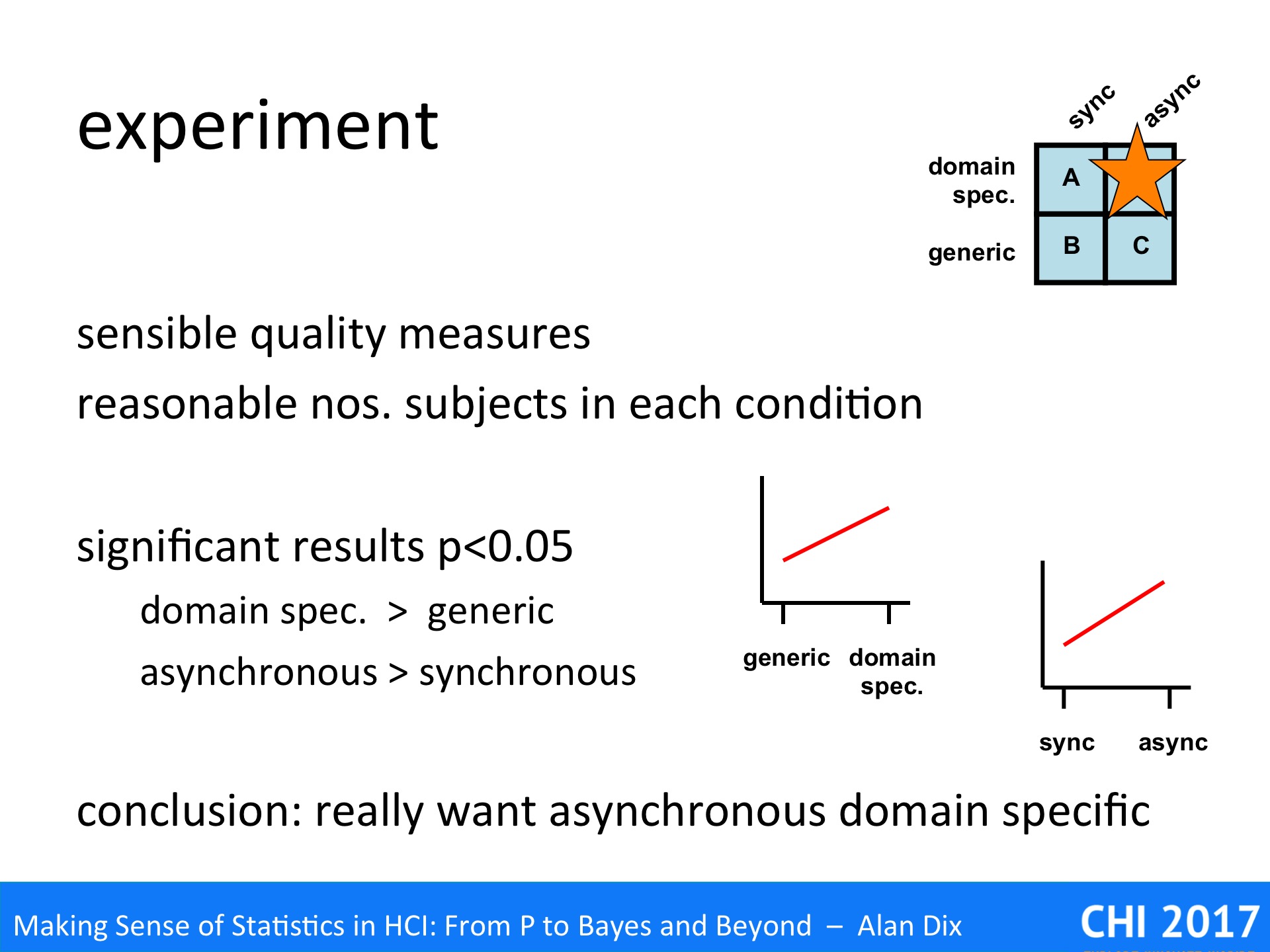
The experiment used sensible measures of quality for the task and had a reasonable number of subjects in each condition. Overall it seemed to be well conducted and, it had statistically significant results.
The results showed that:
- domain specific was better than generic
- asynchronous was better than synchronous
The authors concluded that what was really needed was the missing gap in the deisgn space, asynchronous domain specific software for X. One assume that in the next year’s conference they may have a paper on just such a piece of software,.

There are some problems with this due to interaction effects, there may be some aspect to the task that means that while domain specific synchronous software is was better than generic software and also asynchronous generic software was better for task X than than synchronous generic software, still it could be that asynchronous domain specific software is worse. However, this is still a good place to look.
Much more important is that if you blinked at the wrong moment in the presentation, you could easily miss that the whole research results are potentially completely wrong.
Although the presentation discussed the experiment mostly in terms of the properties, and certainly the paper’s conclusions did this. In fact these were not independently varied. Instead three systems were used that happened to embody the relevant properties,
Say system B just happened to be a badly designed piece of software, nothing to do with the articular properties. In comparisons System B was would be worse than system A, which would be interpreted as domain specific is better than generic. Similarly system B would be worse than system C, being interpreted as asynchronous is better than synchronous … bit really system B just happens to be bad!
Weirdly most experimenters would realise that this was an issue if there were only three users, but having a small number of pieces of software often goes unnoticed.

So, what went wrong?
The experiment as run with borrowed methods from psychology, where the controlled experiments typically have a single cause and are in highly controlled environments, so that only the particular aspect being studied is varied between trials. The task X experiment appears in the guise of just such a controlled experiment, varying a single quality: bespoke vs. generic, synchronous vs. asynchronous.
However, interaction, even in lab settings, needs some level of ecological validity and indeed the systems used in the experiment were real software, with all their complexities. However, the nature of such ecologically valid experiments is that there are always multiple causes and open situations. Indeed, Carroll and Rosson’s claims analysis [CR92] embraces the alterative and possibly multiple causes of the success (or failure!) of systems.
The obvious way to address this would be to have lots and lots of systems embodying each property, just as you have lots and lots of users. However, this is typically impractical, so that I have previous declared that:
the evaluation of generative artefacts is methodologically unsound [Dx08]
However, this does not mean that it is not possible to validate principles.
You can use rich data, for example, collecting logs or video, using think aloud protocols, or post-task interviews. This could be analysed looking for incidents that make it clear whether the poor performance of system B is due to the properties being studied or other factors (such as general poor design).
In general when you use any form of research methodology borrowed from another area, make sure you understand the assumptions behind it and modify it appropriately when you use it for yourself.
References
[CR92] John M. Carroll and Mary Beth Rosson. 1992. Getting around the task-artifact cycle: how to make claims and design by scenario. ACM Trans. Inf. Syst. 10, 2 (April 1992), 181-212. DOI=http://dx.doi.org/10.1145/146802.146834
[Dx08] A. Dix (2008). Theoretical analysis and theory creation, Chapter 9 in Research Methods for Human-Computer Interaction, P. Cairns and A. Cox (eds). Cambridge University Press, pp.175–195. ISBN-13: 9780521690317 http://www.alandix.com/academic/papers/theory-chapter-2008/