from what happens to how and why – when quantitative and qualitative meet
It is important not just to know that something occurs, but how and why. Mechanism is about understanding the steps and processes, which buttons were pressed, what screens viewed, what information was looked at and how this all comes together to create a larger phenomenon.
Crucially understanding mechanism makes it possible to draw lessons and make predictions beyond the data available and the particular situations you have studied.
Typically quantitative data and statistical analysis helps you understand what happens as an end-to-end phenomenon and what is true of it as a whole. However, it often reveals little of the processes and mechanisms by which it occurs: what, but not how and why.
In contrast, qualitative methods such as rich observations, ethnography or post-experiment interviews are better suited to exploratory research (see “Why are you doing it?”) and answering these how and why questions. For example, one may determine the most common ways to achieve a task by content analysis of videos or key-stroke trace data.
Theoretical understanding may help here. This may include cognitive and psychological understanding, for example, if a user is selecting a small target with an on-screen pointer, then they have to be looking at it as human peripheral vision is not accurate enough for fine positioning tasks. Alternatively it may be related to unpacking device or application interaction characteristics, for example, if someone is choosing an item from a long menu, they need to decide if the item is in the visible portion, and if not scroll the menu, etc.
Once we have a model of how the user is behaving, we may be able to use that directly or we may use it to plan more in-depth analyses or investigations into each phase of activity.
When you have numerical empirical data one often attempts to interpolate between measured values. For example, if one found that reading speed was 10% faster with 12-point font than with 10-point font, then there is a good chance that 11-point font will sit in between, maybe of the order of 4%, to 6% faster. Even this may be problematic, for example, it just may be that 11-point font pixelates badly on the particular screen resolution of the devices you are experimenting with. However, it is a reasonable heuristic.
However, extrapolation is usually far harder: what about reading 8-point font or 32 point font or 3-point font?
However, if you understand the mechanism you can deconstruct the overall behaviour into arts that may be simple enough for you to be able to work out whether extrapolation is possible, or which can be put together in different ways to predict performance or behaviour in other contexts.
As an example, we will consider an early paper on font sizes on mobile devices, which included what appeared to have been a well conducted experiment, with statistically significant results, which concluded that a particular font size, let’s say 12 point, was best.
This sounds like a very useful piece fo design advice except for two things.
First, the result was almost certainly related to detailed device characteristics such as screen resolution: was this a 12-point font that was best, or a 12-pixel one, or simply one that did not render badly on the particular screen?
Second, the result will have been influenced by the particle task used. This involved finding items in a menu that could be paged (hence the earlier example). Would the result hold or other tasks?
In this case it was relatively easily to work out the mechanism, the detailed steps the user would need to perform in order to complete the menu selection task.
visual search of the screen to see if the target item appears
if not move to next screen and try step 1 again
when it is found select the target item
Looking through these it seem very likely that step 1 will be easier with larger fonts until the point at which item names get too long to fit on the screen. Step 2 however is likely to occur more frequently with larger font sizes, as there will be fewer lines and hence fewer items per screen-full, so for this step smaller fonts are bond to reduce the number of cycles. Finally, step 3 is again likely to have been easier and faster with larger font sizes, whether on a touch device (larger target) or cursor key-based one (less items to move cursor through)
In summary:
Step 1 – speed of visual search – large font better
Step 2 – number of pages to scroll through – small font better
Step 3 – speed of item selection – large font better
The optimal font size will have been a trade-off between these factors, and changes in the tasks would almost certainly have changed this figure. For example, if the search were within a very large menu, then it is likely that scrolling through pages of menu items would dominate and hence the optimal choice would be the smallest readable font. In contrast if the number of items was always small I larger be better to have larger items so longa s they all fitted within the first screen.
As well as being able to make predictions before experimentation starts, unpacking the mechanism in this way would have allowed the experimenters to produce better analyses. Indeed, they had used some form of low-level logs to produce their end-to-end times and break these down into empirical timings for steps 1 and 3. For step 3, the number of pages that needed to be scrolled through to find the target item can be calculated precisely with empirical data being used to determine the time taken to press the page down key.
Wit these more detailed timings, the authors could have replaced their misleading single ‘optimal’ figure and replace this with a formula, that given an average menu length told you the best font size.
Furthermore, other kinds of mobile task would involve steps that resemble those for the menu selection task, enabling predictions to me made in entirely new contexts.
It is easy, especially when promoting one’s own idea, to want to show that it is better than everyone else’s!
However, users and tasks differ from one another. Typically a system or design property may be useful for a particular purpose or group of users, but not for others. If you understand this, you are in a better position to improve your research or market your system.
In general, it is more important to know who or what something is good for.
Imagine you have run a head to head comparison between two potential systems designs A and B, with 40 users. The user error rates are:
system A 5.2%
system B 6.2%
In fact they are not that different, System A is marginally better as people have slightly less errors, but is that 1% difference going to change the world. Anyway, it is a difference, so you go ahead and deploy system A.
However, it just so happens that of the 40 users 10 are novices and 10 experts. Sure enough the novices have a lower error rate with system A, and indeed by a wide margin (half the error rate), but look at the expert error rates:
expert – system A 9.6%
expert – system B 2.7% !!!!
In fact, system A is considerably worse than system B for the experts.
If this were a research setting, then just looking at the averages means you have a fairly marginal result to report – yep, you might have a good p-value, but an effect size that will leave your readers yawning in their seats.
However, if you look at the way this differentially affects the different groups (a) you have larger effects to report; which are also (b) far more interesting. Why do you get the different behaviour for novices and experts? What further research does this prompt?
The issue is perhaps even more critical for the usability professional.
It is often easier to user test novices when dealing with systems for rather than professionals; for example, you might test a financial planning application with economics students, or a diagnostic system with medical students. Novices are easier to access, and their time less costly.
However, it is likely that when you deploy the larger user group are expert.
You deployed the wrong system … and it is worse by a large margin!
If instead of simply asking, “is my system better?”, you ask, “who is my system better for?”, then you are able to ensue that you deliver the right solution to the right people.
This is also true for tasks. Typically a system or interaction method is good for some purposes, but less good for others.
The slide shows some stills of the PieTree visualisation [OD06] . Like a TreeMap, the PieTeee is a constant area visualisation for hierarchical data, in that the area of each part reflects the number or size of the items it represents. A PiTree starts as a normal pie chart of the top level categories, but you can explode any segment showing the next level in each as smaller and smaller segments. At the top right is a fully expanded PieTree, whereas the image n the centre is unexpanded. In real use only some segments may be expanded at any particular time depending on where the user has drilled down. The screen shot in the middle has the PieTree on the left and classic file tree-style visualisation on the left.
In evaluating this several tasks were used. The tasks included extreme ones following the advice on careful choice of tasks from “Gaining Power – tasks“. One was focused on finding the largest items, and was deliberately designed to highlight the advantages of the PieTree between the file-tree style visualisation; there was an obvious strategy for the former starting by drilling down into the biggest segment. However there was also a task to find the smallest, where there was no obvious search heuristic and everything had to be opened. When it was it is actually easier to san the text version of the smallest number than it is trying to work out which of the slightly different shaped small elements was actually smallest.
The results were exactly as we expected, that is the PieTree visualisation was good for some kinds of tasks and the file-tree style for others. Having both available, as in the image in the centre, was never best for any task, but was always a good second best no matter which of the visualisations ‘won’.
In general, it is usually far more important to know who or what something is good for, than some overall averaged measure. For researchers knowing this is far more informative allowing you to start to ask further questions about why certain features or properties are better. For practitioners, this is crucial for targeting solutions at the right people and the right problems.
Reference
[OD06] R. O’Donnell, A. Dix and L. Ball (2006). Exploring the PieTree for Representing Numerical Hierarchical Data. Proceedings of Proceedings of HCI2006, People and Conputers XX – Engage. Springer. pp. 239-254. http://www.alandix.com/academic/papers/HCI2006-PieTree/
Statistics is largely about assessing and validating measured values, but what do they actually measure?
Thinking about the conditions – what have you really shown – some general result or simply that one system or group of users is better than another?
In an example we will look at how a paper published at a major ACM conference appeared to be demonstrating the value of a particular kind of interaction style for a particular problem, but may simply be that they chose a particularly bad system as one of their experimental conditions.
Imagine you have got good data and a gold standard p-value. You are about to rite in your conclusions that using reverse alphabetic menus leads to faster access times than other layouts. However, before you commit, ask yourself “what else might have cased this result”. Maybe the tasks you used tended to include a lot of items starting with x, y and z?
If you find alternative explanations you might be able to look at your data in a different way to tease out the difference between your original hypothesis and the alternatives. Can’t this would be an opportunity to plan a new experiment that exposes the difference.
It is easy to get confused between things that are true about your subjects and things that are true generally. Imagine you have a mobile phone app for amusement parks that offers games for families to play together while they wait in the queue for a ride. You give the app to four families who have new app and also have a small clicker device where they are asked at intervals whether or not they are happy. The families visit many rides during the day and you analyse the data to see whether they are more happy while waiting in queues that have a game compared with those that don’t. Again you get a gold standard p-value and feel you are ready to publish.
However, if you had a small number of families, and a lot of data per family, what your statistics have probably told you is that you can accurately say for those four families, that they are, on average, happier when they play the app games. However, this is a reliable result about a few families, not a general result about all families; for that you would need far more families and different statistical analysis.
Perhaps even harder to spot because it is so common is to confuse results about specific systems with results about the properties they embody.
To illustrate this we’ll look at a little story from a few years ago.
It was a major ACM conference and the presentation of, what appeared to be, a good empirical paper. The topic was tools to support a collaborative task which we’ll call ‘X’.
The researchers were interested in two main factors:
domain specific for task X vs more generic software
synchronous vs asynchronous collaboration
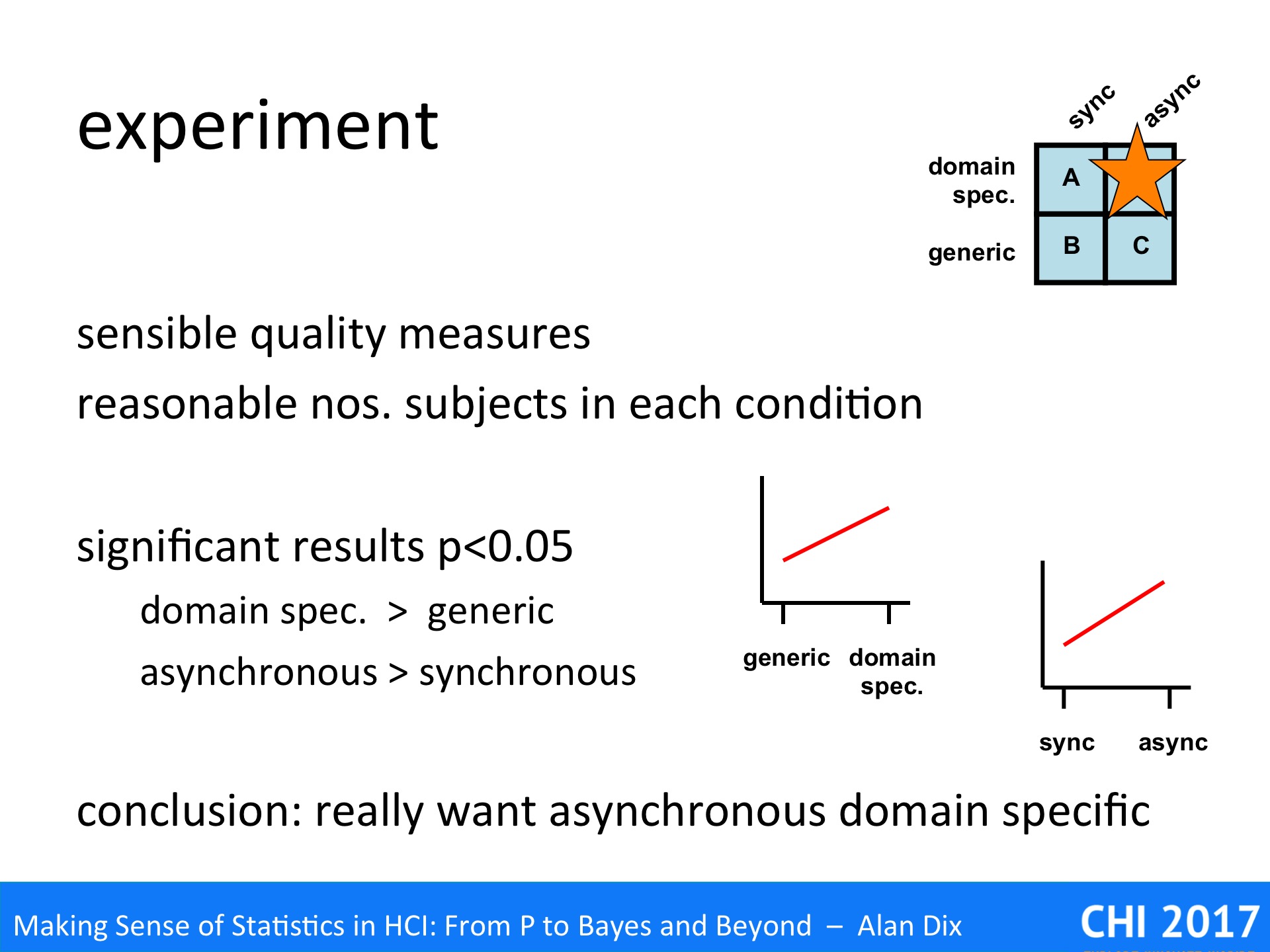
They found three pieces of existibg siftware that covered three of the four slots’ in the design space:
A – domain specific software, synchronous
B – generic software, synchronous
C – generic software, asynchronous
The experiment used sensible measures of quality for the task and had a reasonable number of subjects in each condition. Overall it seemed to be well conducted and, it had statistically significant results.
The results showed that:
domain specific was better than generic
asynchronous was better than synchronous
The authors concluded that what was really needed was the missing gap in the deisgn space, asynchronous domain specific software for X. One assume that in the next year’s conference they may have a paper on just such a piece of software,.
There are some problems with this due to interaction effects, there may be some aspect to the task that means that while domain specific synchronous software is was better than generic software and also asynchronous generic software was better for task X than than synchronous generic software, still it could be that asynchronous domain specific software is worse. However, this is still a good place to look.
Much more important is that if you blinked at the wrong moment in the presentation, you could easily miss that the whole research results are potentially completely wrong.
Although the presentation discussed the experiment mostly in terms of the properties, and certainly the paper’s conclusions did this. In fact these were not independently varied. Instead three systems were used that happened to embody the relevant properties,
Say system B just happened to be a badly designed piece of software, nothing to do with the articular properties. In comparisons System B was would be worse than system A, which would be interpreted as domain specific is better than generic. Similarly system B would be worse than system C, being interpreted as asynchronous is better than synchronous … bit really system B just happens to be bad!
Weirdly most experimenters would realise that this was an issue if there were only three users, but having a small number of pieces of software often goes unnoticed.
So, what went wrong?
The experiment as run with borrowed methods from psychology, where the controlled experiments typically have a single cause and are in highly controlled environments, so that only the particular aspect being studied is varied between trials. The task X experiment appears in the guise of just such a controlled experiment, varying a single quality: bespoke vs. generic, synchronous vs. asynchronous.
However, interaction, even in lab settings, needs some level of ecological validity and indeed the systems used in the experiment were real software, with all their complexities. However, the nature of such ecologically valid experiments is that there are always multiple causes and open situations. Indeed, Carroll and Rosson’s claims analysis [CR92] embraces the alterative and possibly multiple causes of the success (or failure!) of systems.
The obvious way to address this would be to have lots and lots of systems embodying each property, just as you have lots and lots of users. However, this is typically impractical, so that I have previous declared that:
the evaluation of generative artefacts is methodologically unsound [Dx08]
However, this does not mean that it is not possible to validate principles.
You can use rich data, for example, collecting logs or video, using think aloud protocols, or post-task interviews. This could be analysed looking for incidents that make it clear whether the poor performance of system B is due to the properties being studied or other factors (such as general poor design).
In general when you use any form of research methodology borrowed from another area, make sure you understand the assumptions behind it and modify it appropriately when you use it for yourself.
References
[CR92] John M. Carroll and Mary Beth Rosson. 1992. Getting around the task-artifact cycle: how to make claims and design by scenario. ACM Trans. Inf. Syst. 10, 2 (April 1992), 181-212. DOI=http://dx.doi.org/10.1145/146802.146834
[Dx08] A. Dix (2008). Theoretical analysis and theory creation, Chapter 9 in Research Methods for Human-Computer Interaction, P. Cairns and A. Cox (eds). Cambridge University Press, pp.175–195. ISBN-13: 9780521690317 http://www.alandix.com/academic/papers/theory-chapter-2008/
Visualisation is a powerful tool that can help you highlight the important features in your data, but is also dangerous and can be misleading.
Visualisation is a huge topic in its own right, but for initial eyeballing of raw data one is most often using quite simple scatter plots, line graphs or histograms, so here we will deal with two choices you make about these: the baseline and the basepoint.
The first, the baseline, is about where you start place the bottom of your graph at zero or some other value, a ‘false’ baselines. The second, the basepoint, is about the left-to-right start.
Mathematically speaking, the x and y axes are no different, you can graph data either way, but conventionally they are used differently. Typically the x (horizontal) axis shows the independent variable, the thing that you choose to vary experimentally (e.g. distance to target), or given by the world (e.g. date), the vertical, y, axis is usually the dependent variable, what you measure, for example response time or error rate.
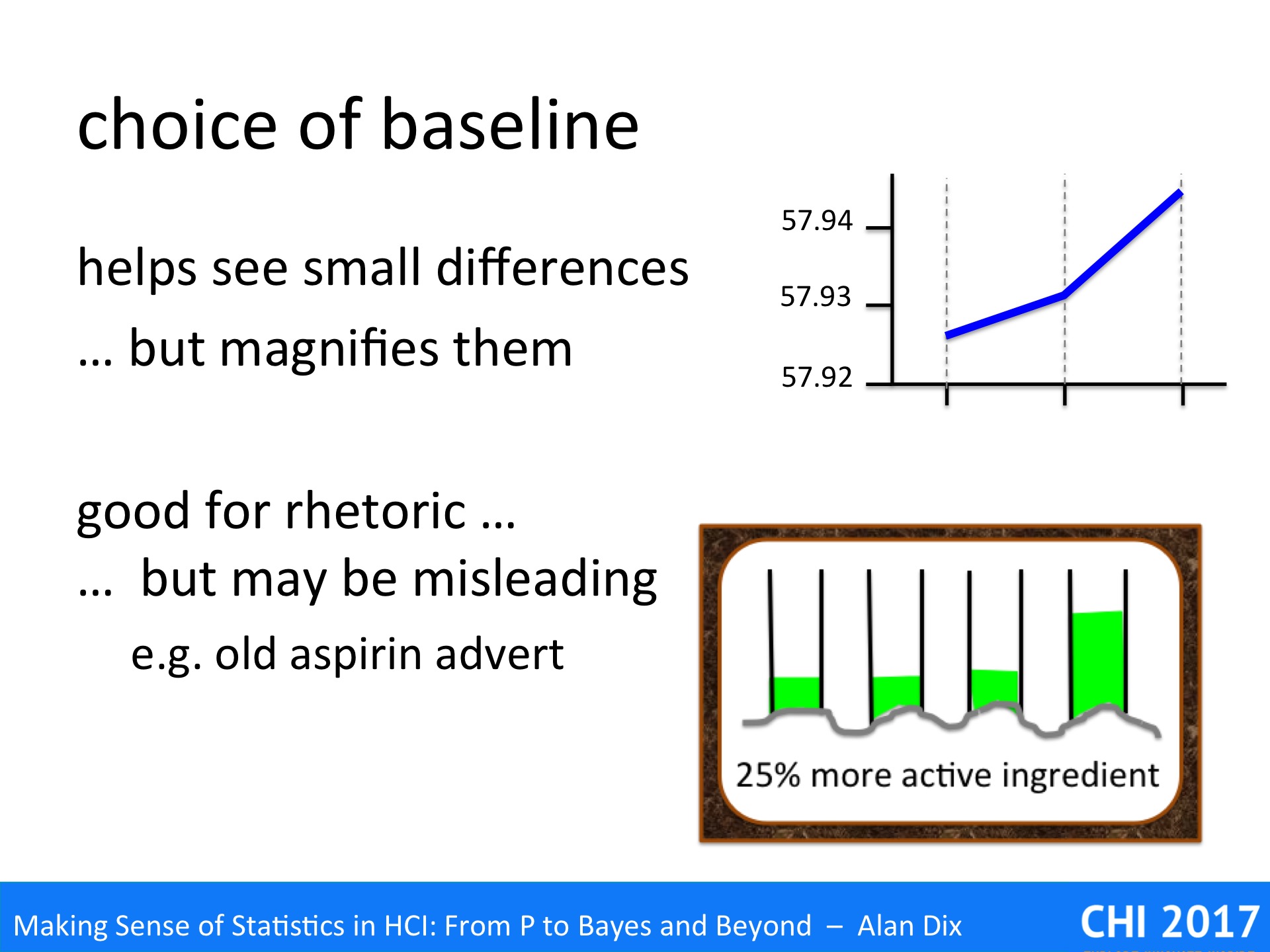
As noted, the baseline is about where you start, whether you place the bottom of your graph at zero or some other value: the former is arguably more ‘truthful’, but the latter can help reveal differences that might get lost of the base effect is already large – think of climbing ‘small’ peaks near the top of Everest.
In the graph on the top right there is a clear change of slope. However, look more carefully at the vertical scale (you may need to zoom in!). The scale starts at 57.92 and the total range of the values plotted is just 0.02. This is a false baseline, instead of starting the scale at zero, it has started at anther value (in this case 57.92).
The utility of this is clear. If the data had been plotted on a full scale of, say, 0-60, then even the slope would be hard to see, let alone the change in slope. Whether these small changes are important depends on the application.
Scientists use a Kelvin scale for temperature, starting at absolute zero (-273 C), but if you used this as a full scale for day-to-day measurements, even the difference between a hot summer’s day and midwinter would only be about 10%, the ‘false’ baseline of the centigrade and Fahrenheit scales are far more useful.
This is even more important in a hospital: the difference between normal temperature and high fever, would be imperceptible (less than 1%) on a Kelvin scale, and medical thermometers do not even show a full centigrade range, but instead range from mid 30s to low 40s.
Of course, a false baseline can also be misleading if the reader is not aware of it, making insignificant differences appear large. This may happen by accident, or may be deliberate!
Many years ago there used to be a TV advert for a brand of painkiller, let’s call it Aspradine. The TV advert showed a laboratory with impressive scientific figures in white lab coats. On the laboratory bench was a rack of four test-tubes, each part filled with white powder all at the same height. The camera zoomed into a view of the top portion of the test-tubes, and to the words “Aspradine has 25% more active ingredient than other brands”, additional powder was poured into one, which rose impressively.
Of course the words were perfectly accurate, and I’m sure they were careful to actually only add a quarter extra to the tube, but the impression given was of a much larger difference.
The photographs of President Trump’s inauguration are a high profile (and highly controversial!) example of this effect. Looking at photos from the front of the crowd, it is very hard to tell the difference between different inaugurations – all look full at the front, just like if the advert had just sown the bottom half of the test-tubes. However, the image from the back clearly shows the quite substantial, and not unexpected, differences between different inaugurations. The downside to this is that, just like the Aspradine advert’s image of the top of the test-tubes or the slope in the graph, it gave the impression that the 2017 crowd was in fact very small … and reported by at least one news outlet at only a quarter of a million, which then Trump heard, responded to in his CIA speech … and, as they say, the rest is history.
Hopefully your research will not be as controversial, but beware, whether or not this sort of rhetoric is acceptable in the marketing or political arena, be very careful in your academic publications!
The graph at the top of this slide shows UK public sector borrowing over a 20-year period. Imagine you want to quote a 10-year change figure. One choice might be to look at the lowest point in 2007 and compare to the highest point in 2017 (the green line). Alternatively you might choose the highest point in 2007 and compare with the lowest in 2017. The first would suggest that there had been a massive increase in public sector borrowing; the latter would suggest a massive decrease. Both would be misleading!
In this case the data is clearly seasonal, related, one assumes, to varying tax revenues through the year, and perhaps differing costs. Often such data is compared at like-time’s each year (say Jan-Jan), which would give a fairer comparison.
If the data simply varies a lot then some form of average is often better. The lower graph shows precisely the same UK public borrowing data, but averaged over 12 month periods. Now the long-term trends are far more clear, not least the huge hike at the start of the global recession when there were large-scale bank bailouts followed by a crash in tax revenues.
For a real example of this see my blog “the educational divide – do numbers matter?“.
Finally, you may think that unless one were deliberately intending to deceive, no-one could make the mistake of using either of the two initial lines as both are so clearly misleading. However, imagine you had never plotted the data and instead it was simply a large spreadsheet full of numbers. It would be easy to pick and arbitrary start and end dates not realising the choice was so critical.
It seems an obvious message, but so easy to forget when you have that huge spreadsheet and just want to throw it into SPSS or R and see whether all your hard work was worthwhile.
But before you jump to work out your T-test, regression analysis or ANOVA, just stop and look.
Eyeball the raw data, as numbers, but probably in a simple graph- but don’t just plot averages, initially do scatter plots of all the data points, so you can get a feel for the way it spreads. If the data is in several clumps what do they mean?
Are there anomalies, or extreme values?
If so these may be a sign of a fault in the experiment, maybe a sensor went wrong; or it might be something more interesting, a new or unusual phenomenon you haven’t thought about.
Does it match your model. If you are expecting linear data does it vaguely look like that? If you are expecting the variability to stay similar (an assumption of many tests, including regression and ANOVA).
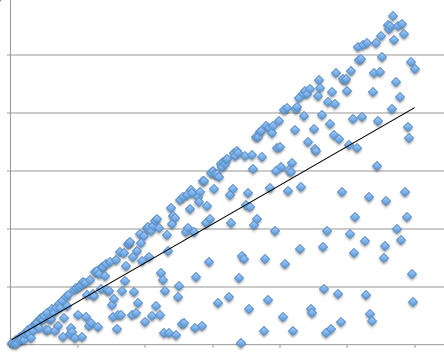
The graph above is based on one I once saw in a paper (recreated here), where the authors had fitted a regression line.
However, look at the data – it is not data scattered along a line, but rather data scattered below a line. The fitted line is below the max line, but the data clearly does not fit a standard model of linear fit data.
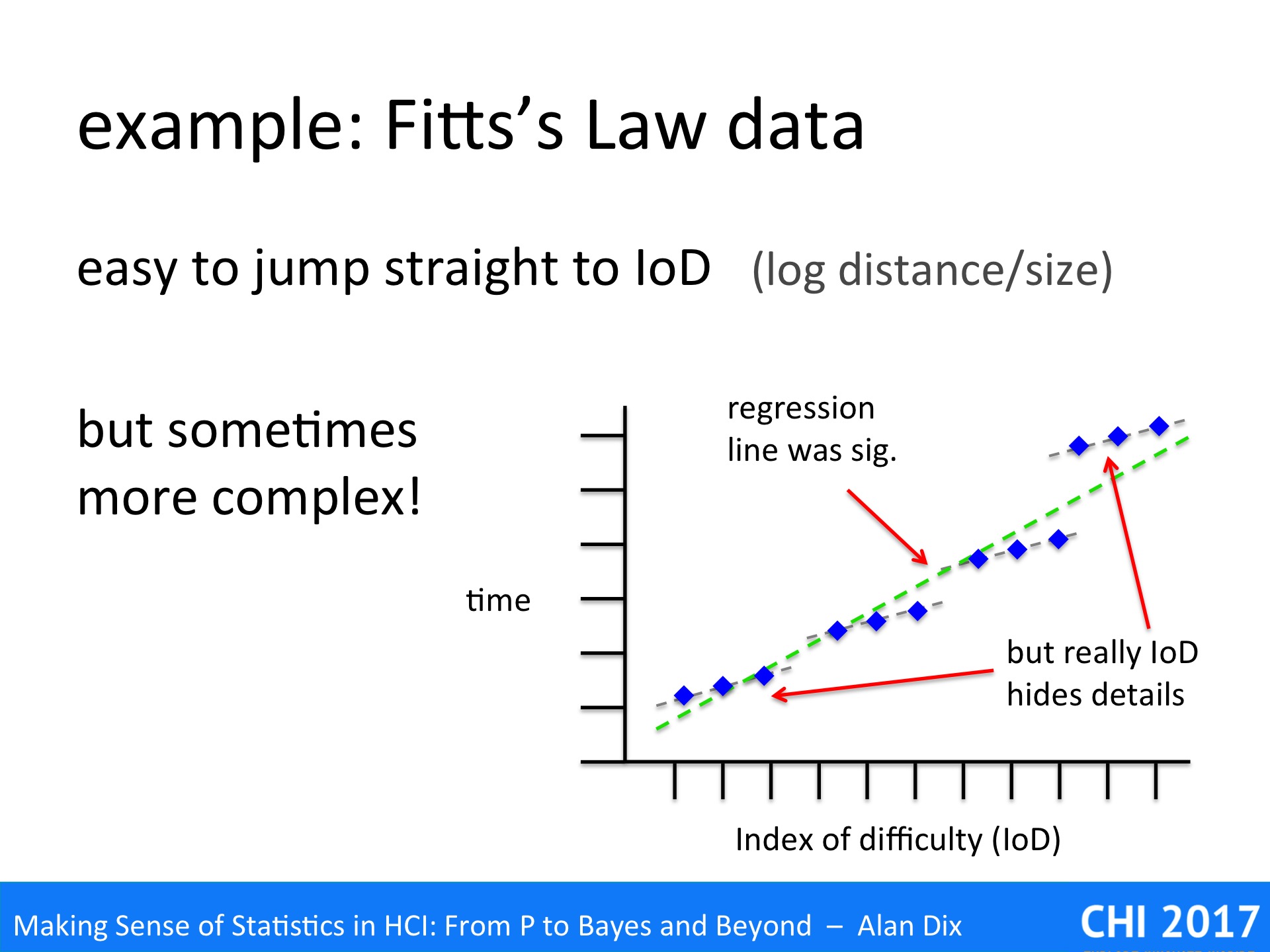
A particular example in the HCI literature where researchers often forget to eyeball the data is in Fitts’ Law experiments. Recall that in Fitts’ original work [Fi54] he found that the time taken to complete tasks was proportional to the Index of Difficulty (IoD), which is the logarithm of the distance to target divided by the target size (with various minor tweeks!):
IoD = log2 ( distance to target / target size )
Fitts’ law has been found to be true for many different kinds of pointing tasks, with a wide variety of devices, and even over multiple orders of magnitude. Given this, many performing Fitts’ Law related work do not bother to separately report distance and target size effects, but instead instantly jump to calculating the IoD assuming that Fitts’ Law holds. Often the assumption proves correct …but not always.
The graph above is based on a Fitts’ Law related paper I once read.
The paper was about the effects of adding noise to the pointer, as if you had a slightly dodgy mouse. Crucially the noise was of a fixed size (in pixels) not related to the speed or distance of mouse movement.
The dots on the graph show the averages of multiple trials on the same parameters: size, distance and the magnitude of the noise were varied. However, size and distance are not separately plotted, just the time to target against IoD.
If you understand the mechanism (that magic word again) of Fitts’ Law [Dx03,BB06], then you would expect anomalies’ to occur with fixed magnitude noise. In particular if the noise is bigger than the target size you would expect to have an initial Fitts Movement to the general vicinity of the target, but then a Monte Carlo (utterly random) period where the noise dominates and its pure chance when you manage to click the target.
Sure enough if you look at the graph you see small triads of points in roughly straight lines, but then the cluster of points following a slight curve. The regression line is drawn, but this is clearly not simply data scattered around the line.
In fact, given the understanding of mechanism, this is not surprising, but even without that knowledge the graph clearly shows something is wrong – and yet the authors never mentioned the problem.
One reason for this is probably because they had performed a regression analysis and it had come out statistically significant. That is they had jumped straight for the numbers (IoD + regression), and not properly looked at the data!
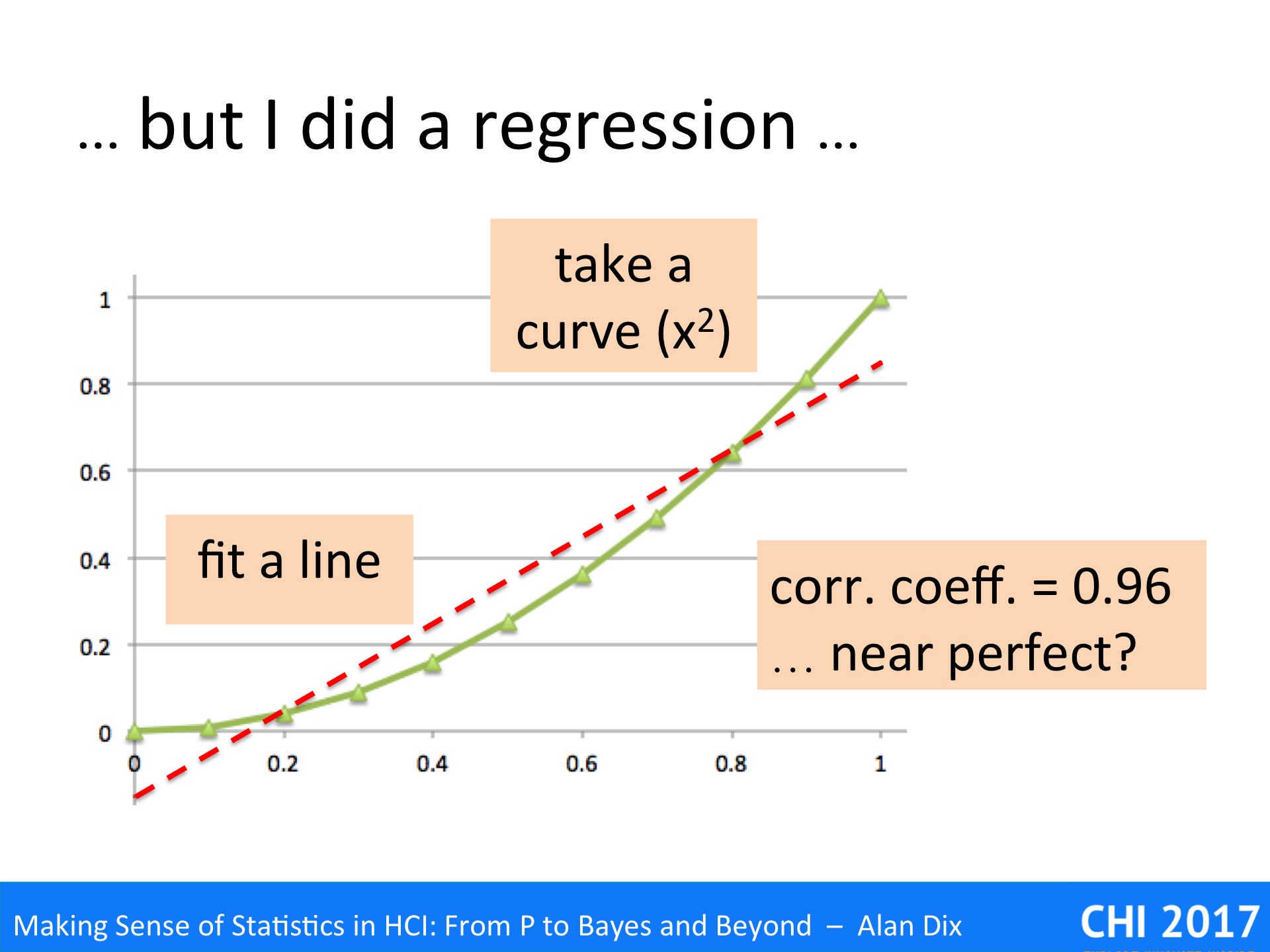
They will have reasoned that if the regression is significant and correlation coefficient strong, then the data is linear. In fact this is NOT what regression says.
To see why, look at the data above. This is not random simply an x squared curve. The straight line is a fitted regression line, which turns out to have a correlation coefficient of 0.96, which sounds near perfect.
There is a trend there, and the line does do a pretty good job of describing some of the change – indeed many algorithms depend on approximating curves with straight lines for precisely this reason. However, the underlying data is clearly not linear.
So next time you read about a correlation, or do one yourself, or indeed any other sort of statistical or algorithmic analysis, please, Please, remember to look at the data.
References
[BB06] Beamish, D., Bhatti, S. A., MacKenzie, I. S., & Wu, J. (2006). Fifty years later: a neurodynamic explanation of Fitts’ law. Journal of the Royal Society Interface, 3(10), 649–654. http://doi.org/10.1098/rsif.2006.0123
[Dx03] Dix, A. (2003/2005) A Cybernetic Understanding of Fitts’ Law. HCI book online! http://www.hcibook.com/e3/online/fitts-cybernetic/
[Fi54] Fitts, Paul M. (1954) The information capacity of the human motor system in controlling the amplitude of movement. Journal of Experimental Psychology, 47(6): 381-391, Jun 1954,. http://dx.doi.org/10.1037/h0055392
You have done your experiment or study and have your data, maybe you have even done some preliminary statistics – what next, how do you make sense of the results?
This part of will looks at a number of issues and questions:
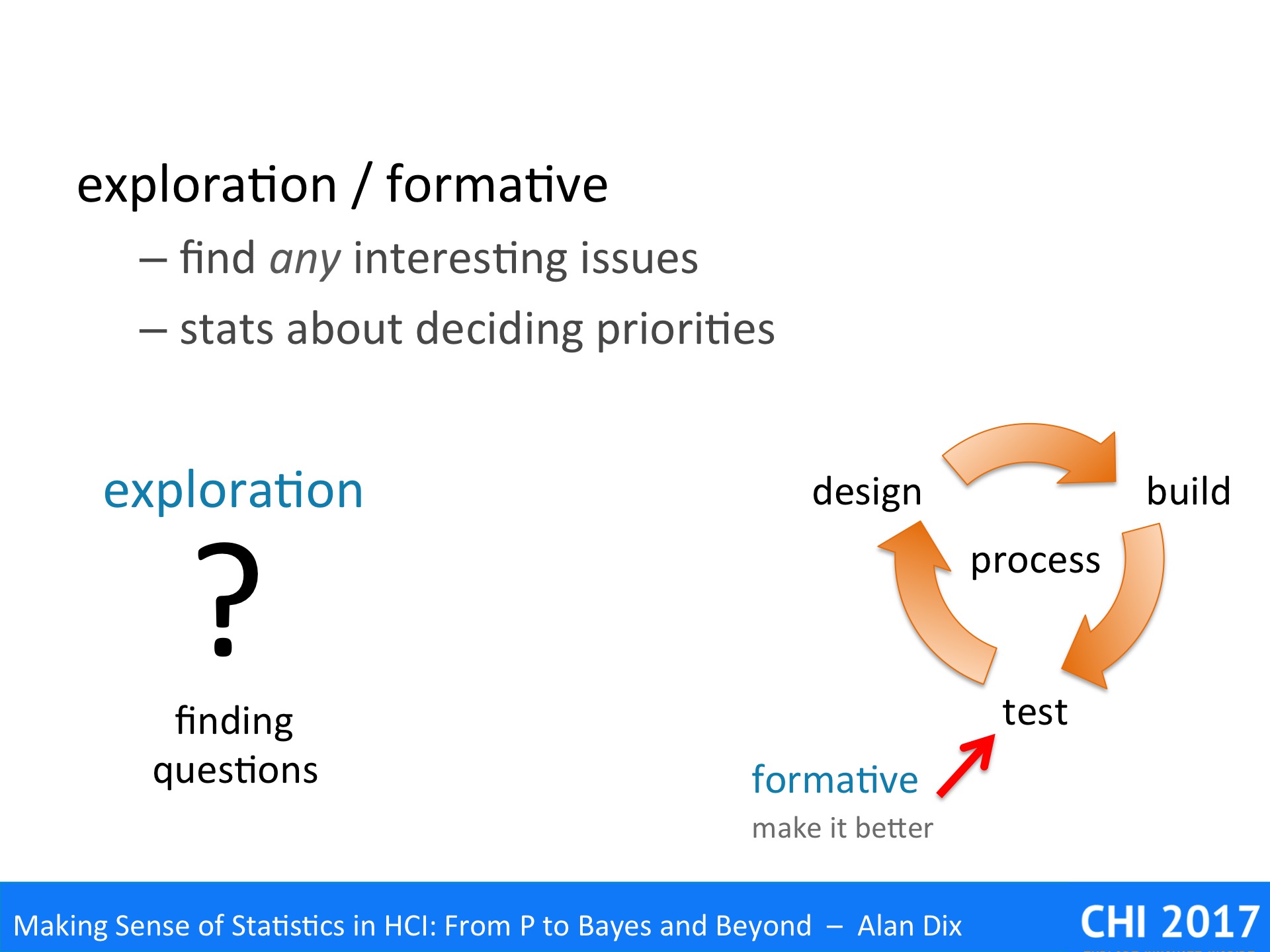
Why are you doing it the work in the first place? Is it research or development, exploratory work, or summative evaluation?
Eyeballing and visualising your data – finding odd cases, checking you model makes sense, and avoiding misleading diagrams.
Understanding what you have really found – is it a deep result, or merely an artefact of an experimental choice?
Accepting the diversity of people and purposes – trying to understand not whether your system or idea is good, but who or what it is good for.
Building for the future – ensuring your work builds the discipline, sharing data, allowing replication or meta-analysis.
Although these are questions you can ask when you are about to start data analysis, they are also ones you should consider far earlier. One of the best ways to design a study is to imagine this situation before you start!.
When you think you are ready to start recruiting participants, ask yourself, “if I have finished my study, and the results are as good as I can imagine, so what? What do I know?” – it is amazing how often this leads to a complete rewriting of a survey or experimental redesign.
Are you doing empirical work because you are an academic addressing a research question, or a practitioner trying to design a better system? Is your work intended to test an existing hypothesis (validation) or to find out what you should be looking for (exploration)? Is it a one-off study, or part of a process (e.g. ‘5 users’ for iterative development)?
These seem like obvious questions, but, in the midst of performing and analysing your study, it is surprisingly easy it is to lose track of your initial reasons for doing it. Indeed, it is common to read a research paper where the authors have performed evaluations that are more appropriate for user interface development, reporting issues such as wording on menus rather than addressing the principles that prompted their study.
This is partly because there are similarities, in the empirical methods used, and also parallels between stages of each. Furthermore, your goals may shift – you might be in the midst of work to verify a prior research hypothesis, and then notice and anomaly in the data, which suggests a new phenomenon to study or a potential idea for a product.
We’ll start out by looking at the research and software-development processes separately, and then explore the parallels.
There are three main uses of empirical work during research, which often relate to the stages of a research project:
exploration – This is principally about identifying the questions you want to ask. Techniques for exploration are often open-ended. They may be qualitative: ethnography, in-depth interviews, or detailed observation of behaviour whether in the lab or on the wild. However, this is also a stage that might involve (relatively) big data, for example, if you have deployed software with logging, or have conducted a large scale, but open ended, survey. Data analysis may then be used to uncover patterns, which may suggest research questions. Note, you may not need this as a stage of research if you come with an existing hypothesis, perhaps from previous phases of your own research, questions arising form other published work, or based on your own experiences.
validation – This is predominantly about answering questions or verifying hypotheses. This is often the stage that involves most quantitative work: including experiments or large-scale surveys. This is the stage that one most often publishes, especially in terms of statistical results, but that does not mean it is the most important. In order to validate, you must establish what you want to study (explorative) and what it means (explanation).
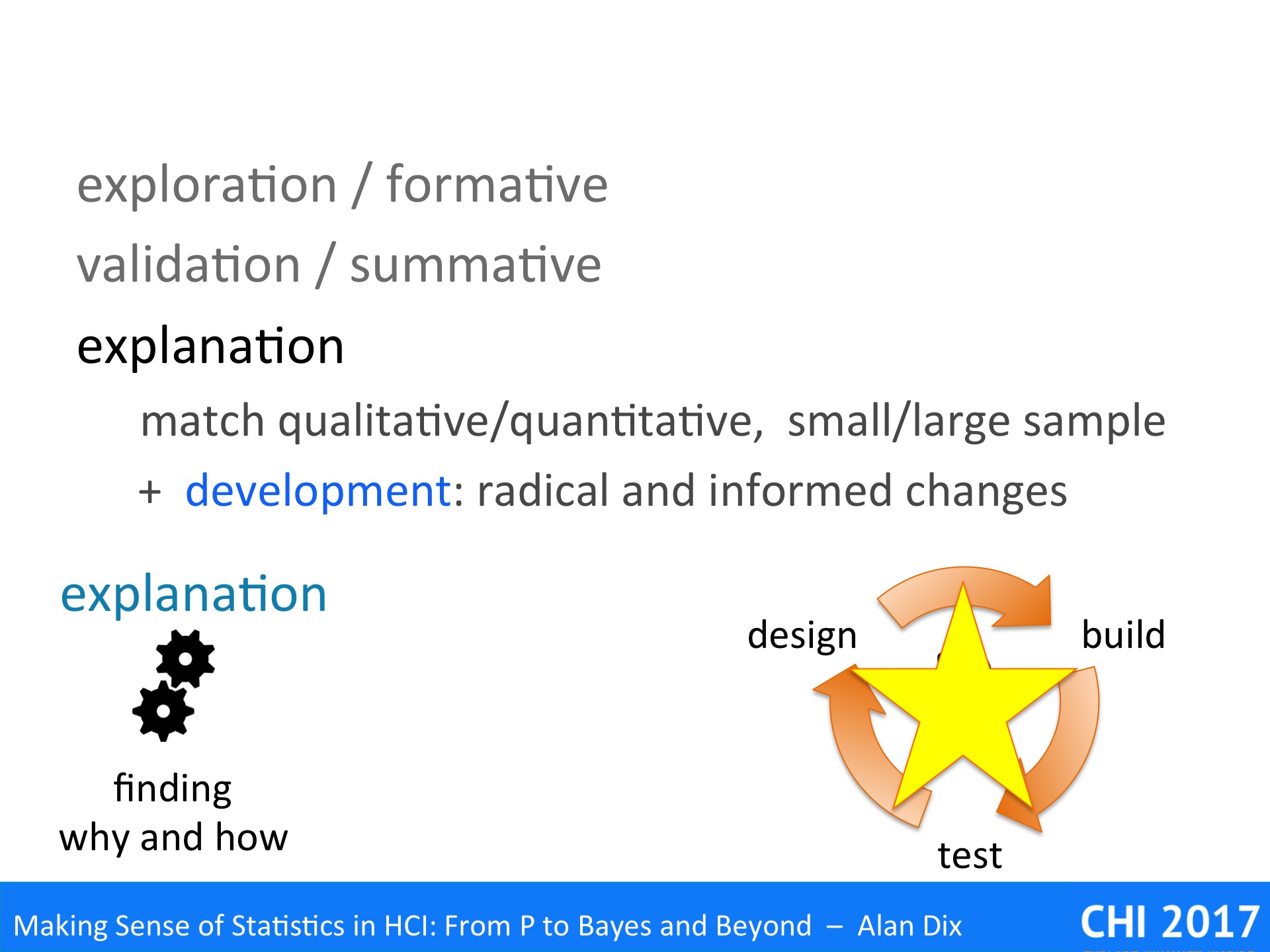
explanation – While the validation phase confirms that an observation is true, or a behaviour is prevalent, this stage is about working out why it is true, and how it happens in detail. Work at this stage often returns to more qualitative or observational methods, but with a tighter focus. However, it may also me more theory based, using existing models, or developing new ones in order to explain a phenomenon. Crucially it is about establishing mechanism, uncovering detailed step-by-step behaviours … a topic we shall return to later.
Of course these stages may often overlap and data gathered for one purpose may turn out to be useful for another. For example, work intended for validation or explanation may reveal anomalous behaviours that lead to fresh questions and new hypothesis. However, it is important to know which you were intending to do, and if you change when and why you are looking at the data differently … and if so whether this matters.
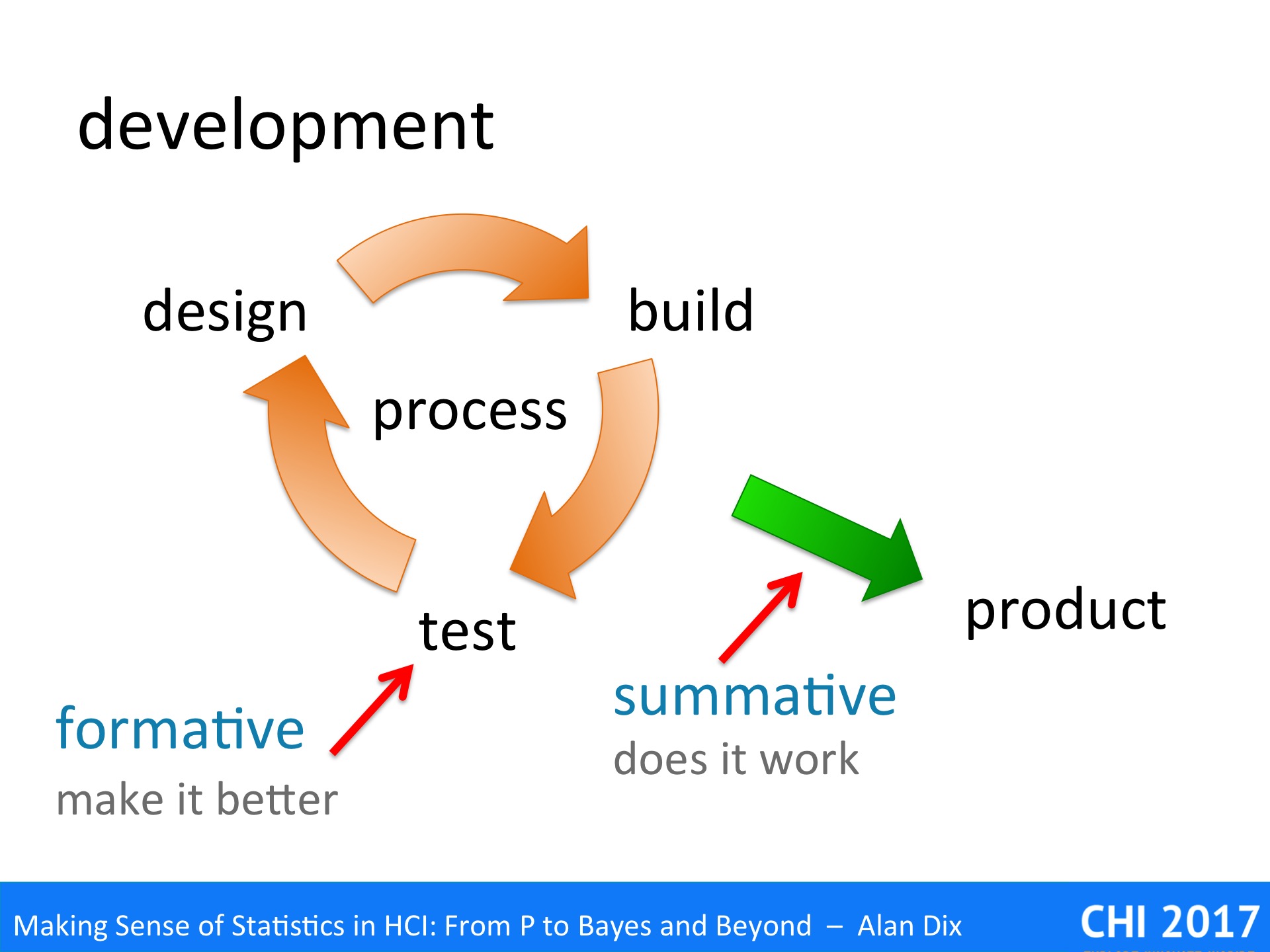
During iterative software development and user experience design, we are used to two different kinds of evaluation:
formative evaluation – This is about making the system better. This is performed on prototypes or experimental systems during the cycles of design–build–test. The primary purpose of formative evaluation is to uncover usability or experience problems for the next cycle.
summative evaluation – This is about checking that the systems works and is good enough. It is performed at the end of the software development process on a pre-release product. IT may be related to contractual obligations: “95% of users will be able to use the product for purpose X after 20 minutes training”; or may be comparative: “the new software outperforms competitor Y on both performance and user satisfaction”.
In web applications, the boundaries can become a little less clear as changes and testing may happen on the live system as part of perpetual-beta releases or A–B testing.
Although research and software development have different overall goals, we can see some obvious parallels between the two. There are clear links between explorative research and formative evaluations, and between validation and summative evaluations. Although, it is perhaps less clear immediately how explanatory research connects with development.
We will look at each in turn.
During the exploration stage of research or during formative evaluation of a product, you are interested in finding any interesting issue. For research this is about something that you may then go on to study in depth and, hopefully, publish papers about. In software development tis is about finding usability problems to fix or identifying opportunities for improvements or enhancements.
It does not matter whether you have fond the most important issue, or the most debilitating bug, so long as you have found sufficient for the next cycle of development.
Statistics are less important at this stage, but may help you establish priorities. If costs or time is short, you may need to decide out of the issues you have uncovered, which is most interesting to study further, or fix first.
One of the most well known (albeit misunderstood ) myths of interaction design is the idea that five users are enough.
The source of this was Nielsen and Landaur’s original paper [NL93], nearly twenty-five years ago. However, this was crucially about formative evaluation during iterative evaluation.
I emphasise it was NOT about either summative evaluation, not about sufficient numbers for statistics!
Nielsen and Landaur combined a simple theoretical model based on software bug detection with empirical data from a small number of substantial software projects to establish the optimum number of users to test per iteration.
Their notion of ‘optimum’ was based on cost-benefit analysis: each cycle of development cost a certain amount, each user test cost a certain amount. If you uncover too few user problems in each cycle you end up with lots of development cycles, which is expensive in terms of developer time. However, if you perform too many user tests you end up finding the same problems, thus wasting user-testing effort.
The optimum value depended on the size and complexity of the project, with the number higher for more complex projects, where redevelopment cycles were more costly, and the figure of five was a rough average.
Now-a-days, with better tool support, redevelopment cycles are far less expensive than any of the projects in the original study, and there are arguments that the optimal value now may even be just testing one user [MT05] – especially if it is obvious that the issues uncovered are ones that appear likely to be common.
However, whether one, five or twenty user, there will be more users on the next iteration – this is not about the total number of users tested during development. In particular, at later stages of development, when the most glaring problems have been sorted, it will become more important to ensure you have covered a sufficient range of the
For more on this see Jakob Neilsen’s more recent and nuanced advice [Ni12] and my own analyses of “Are five users enough?” [Dx11].
In both validation in research and summative evaluation during development, the focus is much more exhaustive: you want to find all problems, or issues (hopefully not many left during summative evaluation!).
The answers you need are definitive, you are not so much interested in new directions (although this may be an accidental outcome), but instead verifying that your precise hypothesis is true, or that the system works as intended. For this you may need statistical test, whether traditional (p value) or Baysian (odds ratio).
You may also be after numbers: how good is it (e.g., “nine out of ten owners say their cats prefer …”), how prevalent is an issue (e.g., “95% of users successfully use the auto-grow feature”). For this the size of effects are important, so you may me more interested in confidence intervals, or pretty graphs with error bars on them.
While validation establishes that a phenomenon occurs, what is true, explanation tries to work out why it happens and how it works – deep understanding.
As noted this will often involve more qualitative work on small samples of people, but often connecting with quantitative studies of large samples.
For example, you might have a small number of rich in-depth interviews, but match the participants against the demographics of large-scale surveys. Say that a particular pattern of response is evident in the large study. If your in-depth interviewee has a similar response, then it is often a reasonable assumption their their reasons will be similar to the large sample. Of course they could be just saying the same thing, but for completely different reasons, but often commons sense, or prior knowledge means that the reliability is evident. Of course, if you are uncertain f the reliability of the explanation, this could always drive targeted questions in a further round of large-scale survey.
Similarly, if you have noticed a particular behaviour in logging data from a deployed experimental application, and a user has the same behaviour during a think aloud session or eye-tracking session, then it is reasonable to assume that the deliberations, cognitive or perceptual behaviours may well be the same as in the users of the deployed application.
We noted that the parallel with software development was less obvious, however the last example, starts to point towards this.
During the development process, often user testing reveals many minor problems. It iterates towards a good-enough solution … but rarely makes large scale changes. Furthermore, at worst, the changes you perform at each cycle may create new problems. This is a common problem with software bugs, code becomes fragile, but also with user interfaces, where each change in the interface creates further confusion, and may not even solve the problem that gave rise to it. After a while you may lose track of why each feature is there at all.
Rich understanding the underlying human processes: perceptual, cognitive, social, can both make sure that ‘bug fixes’ actually solve the problem, Furthermore, it allows more radical, but informed redesign that may make whole rafts of problems simply disappear.
References
[Dx11] Dix, A. (2011) Are five users enough? HCIbook online! http://www.hcibook.com/e3/online/are-five-users-enough/
[NL93] Nielsen, J. and Landauer, T. (1993). A mathematical model of the finding of usability problems. INTERACT/CHI ’93. ACM, 206–213.
[Ni12] Nielsen, J (2012). How Many Test Users in a Usability Study? NN/g Norman–Nielsen Group, June 4, 2012. https://www.nngroup.com/articles/how-many-test-users/
Simple techniques can help, but even mathematicians can get it wrong.
It would be nice if there was a magic bullet and all of probability and statistics would get easy. Hopefully some of the videos I am producing will make statistics make more sense, but there will always be difficult cases – our brains are just not built for complex probabilities.
However, it may help to know that even experts can get it wrong!
In this video we’ll look at two complex issues in probability that even mathematicians sometimes find hard: the Monty Hall problem and DNA evidence. We’ll also see how a simple technique can help you tune your common sense for this kind of problem. This is NOT the magic bullet, but sometimes may help.
There was a quiz show in the 1950s where the star prize car. After battling their way through previous rounds the winning contestant had one final challenge. There were three doors, one of which was the prize car, but behind each of the other two was a goat.
The contestant chose a door, but to increase the drama of the moment, the quizmaster did not immediately open the chosen door, but instead opened one of the others. The quizmaster, who knew which was the winning door, would always open a door with a goat behind. The contestant was then given the chance to change their mind.
Should they stick with the original choice?
Should they swop to the remaining unopened door?
Or doesn’t it make any difference?
What do you think?
One argument is that the chance of the original door being a car was one in three, whether the chance of it being in the other door was 1 in 2, so you should change. However the astute may have noticed that this is a slightly flawed probabilistic argument as the probabilities don’t add up to one.
A counter argument is that at the end there are two doors, so the chances are even which ahs the car, so there is no advantage to swopping.
An information theoretic argument is similar – the doors equally hide the car before and after the other door has been opened, you have no more knowledge, so why change your mind.
Even mathematicians and statisticians can argue about this, and when they work it out by enumerating the cases, do not always believe the answer. It is one of those case where one’s common sense simple does not help … even for a mathematician!
Before revealing the correct answer, let’s have a thought experiment.
Imagine if instead of three doors there were a million doors. Behind 999,999 doors are goats, but behind the one lucky door there is a car.
I am the quizmaster and ask you to choose a door. Let’s say you choose door number 42.
Now I now open 999,998 of the remaining doors, being careful to only open doors hiding goats.
You are left with two doors, your original choice and the one door I have not opened.
Do you want to change your mind?
This time it is pretty obvious that you should. There was virtually no chance of you having chosen the right door to start with, so it was almost certainly (999,999 out of a million) one of the others – I have helpfully discarded all the rest so the remaining door I didn’t open is almost certainly it.
It is a bit like if before I opened the 999,998 goats doors I’d asked you, “do you want to change you mind, do you think the car is precisely behind door 42, or any of the others.”
In fact exactly the same reasoning holds for three doors. In this case there was a 2/3 chance that it was in one of the doors you did not choose, and as the quizmaster I discarded one that had a goat from these, it is twice as likely that it is behind the door did not open as your original choice. Regarding the information theoretic argument: the q opening the goat doors does add information, originally there were possible goat doors, after you know they are not.
Mind you it still feels a bit like smoke and mirrors with three doors, even though, the million are obvious.
Using the extreme case helps tune your common sense, often allowing you to see flaws in mistaken arguments, or work out the true explanation.
It is not and infallible heuristic, sometimes arguments do change with scale, but often helpful.
The Monty Hall problem has always been a bit of fun, albeit disappointing if you were the contestant who got it wrong. However, there are similar kinds of problem where the outcomes are deadly serious.
DNA evidence is just such an example.
Let’s imagine that DNA matching has an accuracy of on in 100,000.
There has been a murder, and remains fo DNA have been found on the scene.
Imagine now two scenarios:
Case 1: Shortly prior to the body being found, the victim had been known to have having a violent argument with a friend. The police match the DNA of the frend with that found at the murder scene. The friend is arrested and taken to court.
Case 2: The police look up the DNA in the national DNA database and find a positive match. The matched person is arrested and taken to court.
Similar cases have occurred and led to convictions based heavily on the DNA evidence. However, while in case 1 the DMA is strong corroborating evidence, in case 2 it is not. Yet courts, guided by ‘expert’ witnesses, have not understood the distinction and convicted people in situations like case 2. Belatedly the problem has been recognised and in the UK there have been a number of appeals where longstanding cases have been overturned, sadly not before people have spent considerable periods behind bars for crimes they did not commit. One can only hope that similar evidence has not been crucial in countries with a death penalty.
If you were the judge or jury in such a case would the difference be obvious to you?
If not we van use a similar trick to the Monty Hall problem, instead here lets make the numbers less extreme. Instead of a 1 in 100,000 chance of a false DNA match, let’s make it 1 in 100. While this is still useful, albeit not overwhelming, corroborative evidence in case 1, it is pretty obvious that of there are more than a few hundred people in the police database, the you are bound to find a match.
It is a bit like if a red Fiat Uno had been spotted outside the victim’s house. If the arguing friend’s car had been a red Fiat Uno it would have been good additional circumstantial evidence, but simply arresting any red Fiat Uno owner would clearly be silly.
If we return to the original 1 in 100,000 figure for a DNA match, it is the same. IF there are more than a few hundred thousand people in the database then you are almost bound to find a match. This might be a way to find people you might investigate looking for other evidence, indeed the way several cold cases have been solved over recent years, but the DNA evidence would not in itself be strong.
In summary, some diverting puzzles and also some very serious problems involving probability can be very hard to understand. Our common sense is not well tuned to probability. Even trained mathematicians can get it wrong, which is one of the reasons we turn to formulae and calculations. Changing the scale of numbers in a problem can sometimes help your common sense understand them.
In the end, if it is confusing, it is not your fault: probability is hard for the human mind; so. if in doubt, seek professional help.
As well as choosing who we ask to participate in our users studies, we can manipulate what we ask them to do, the experimental or study tasks.
We will look at four strategies
distractor tasks (increase effect)
targeted tasks (increase effect)
demonic interventions! (increase effect)
reduced vs wild (reduce noise)
Notably missing are strategies about increasing the number of tasks. While this is possible, and indeed often desirable, the normal reason for this is to increase the diversity of contexts under which you study a phenomenon. Often the differences between tasks are so great it is meaningless to in any way do aggregate statistics across tasks, instead comparisons are made within tasks, with only broad cross-tasks comparisons, for example, f they all lead to improvements in performance.
Typically too, if one does want to aggregate across tasks, the models you take have to be non-linear – if one task takes twice as long as another task, typically variations in it between subjects or trials are also twice as large, or at least substantially larger. This often entails multiplicative rather than additive models of each task’s impact.
One of the strategies for subjects was to choose a group, say novices, for whom you believe effects will be especially apparent; effects that are there for everyone, but often hidden.
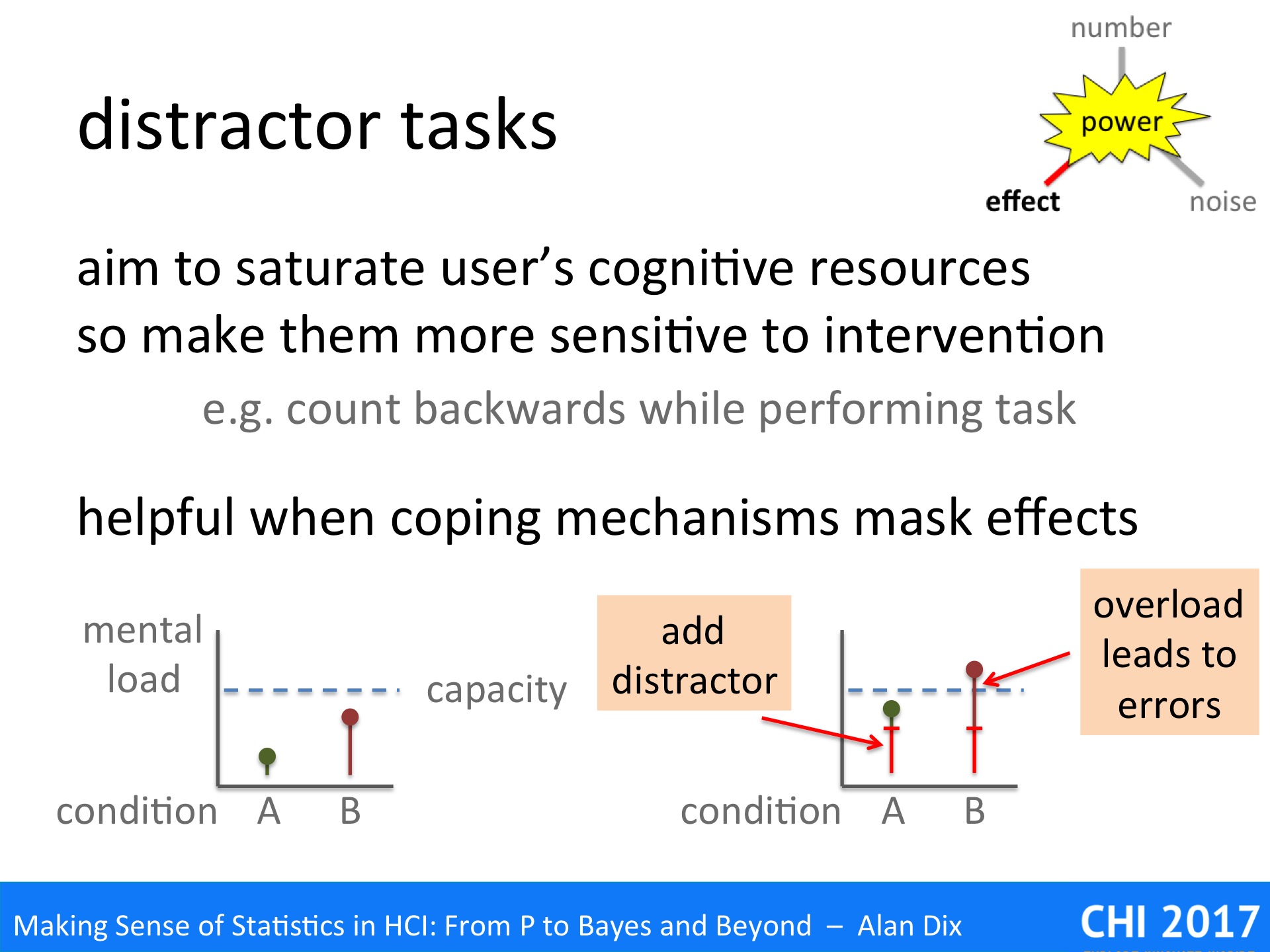
Distractor tasks perform a similar role, but by manipulating the user’s experimental task to make otherwise hidden differences obvious. They are commonly used in ergonomics, but less widely so in HCI or user experience studies; however, they offer substantial benefits.
A distractor task is an additional task given during an experimental situation, which has the aim of saturating some aspect of the user’s cognitive abilities, so that differences in load of the systems or conditions being studied become apparent.
A typical example for a usability study might be to ask a subject to count backwards whilst performing the primary task.
The small graphs show what is happening. Assume we are comparing two systems A and B. In the example the second system has a greater mental load (graph on the left), but this is not obvious as both are well within the user’s normal mental capacity.
However, if we add the distractor task (graph on the right) both tasks become more difficult, but system B plus the distractor now exceed the mental capacity leading to more errors, slower performance, or other signs of breakdown.
The distractor task can be arbitrary (like counting backwards), or ecologically meaningful.
I first came across distractor tasks when I worked in an agricultural research institute. There it was common when studying instruments and controls to be installed in a tractor cab to give the subjects a steering task, usually creating a straight plough furrow, whilst using the equipment. By increasing the load of the steering task (usually physically or in simulation driving faster), there would come a point when the driver would either fail to use one of the items of equipment properly, or produce wiggly furrows. This sweet spot, when the driver was just on the point of failure, meant that even small differences in the cognitive load of the equipment under trial became apparent.
A similar HCI example of an ecologically meaningful distractor task is in mobile interface design, when users are tested using an interface whilst walking and avoiding obstacles.
Distractor tasks are particular useful when people employ coping mechanisms. Humans are resilient and resourceful; when faced with a difficult task they, consciously or unconsciously, find ways to manage, to cope. Alternatively it may be that they have sufficient mental resources to deal with additional effort and never even notice.
Either way the additional load is typically having an effect, even when it is not obvious. However, this hidden effect is likely to surface when the user encounters some additional load in the environment; it may be an event such as an interruption, or more long-term such as periods of stress or external distractions. In a way, the distractor task makes these obvious in the more controlled setting of your user study.
Just as we can have targeted user groups, we can also choose targeted tasks that deliberately expose the effects of our interventions.
For example, if you have modified a word-processor to improve the menu layout and structure, then it makes sense to have a task that involves a lot of complex menu navigation rather than simply typing.
If you have a more naturalistic task, then you may try to instrument it so that you can make separate measurements and observations of the critical parts. For example, in the word-processor your logging software might identify when menu navigation occurs for different functions, log this, and then create response-time profiles for each so that the differences in, say, typing speed in the document itself do not drown out the impact of the menu differences.
Of course this kind of targeting, while informative, can also be misleading, especially in a head-to-head system comparison. In such cases it is worth also trying to administer tasks where the original system is expected perform better than your new, shiny favourite one. Although, it is worth explaining that you have done this, so that reviewers do not take this as evidence your new system is bad! (more on this in part 4 “so what?”)
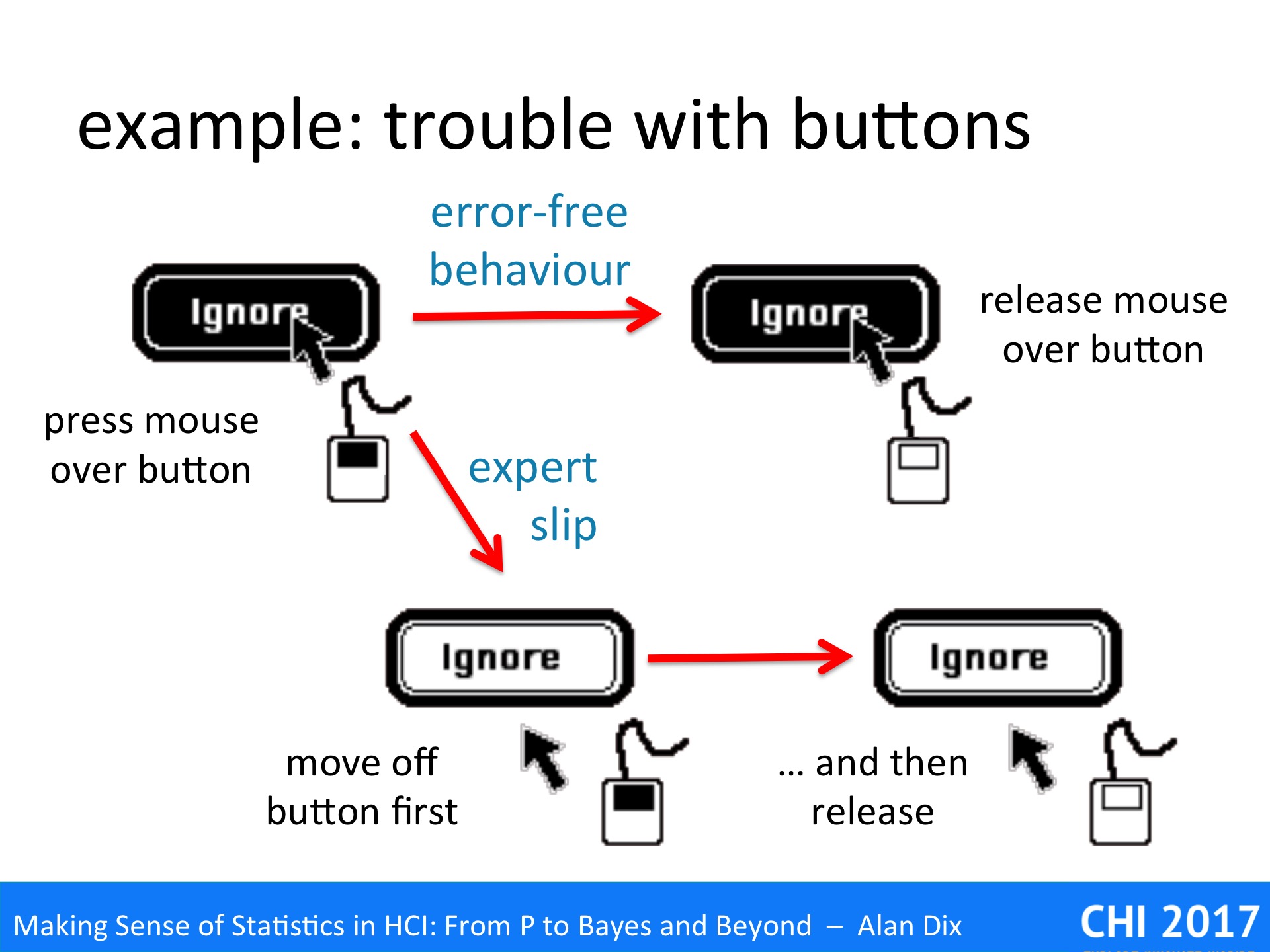
Some years ago I was involved in a very successful example of this principle. Steve Brewster (now Glasgow) was looking at possible sonic enhancement of buttons [DB94]. One problem he looked at was an expert slip, that is an error that experts make, but does not occur with novice use. In this case highly experienced users would occasionally think they had pressed a button to do something, not notice they had failed, and then only much later discover the impact. For example, if they had cut a large body of text and thought they had pasted it somewhere, but hadn’t, then the text would be lost.
Analysing this in detail, we realised that the expert user would almost certainly correctly move the mouse over the button and press it down. Most on-screen buttons allow you to cancel after this point by dragging your mouse off the button (different now with touch buttons). The expert slip appeared to be that the expert started to move the mouse button to quickly as they started to think of the next action.
Note a novice user would be less likely to have this error as they would be thinking more carefully about each action, whereas experts tend to think ahead to the next action. Also novices would be more likely to verify the semantic effect of their actions, so that, if they made the slip, they would notice straight away and fix the problem. The expert slip is not so much making the error, but failing to detect it.
Having understood the problem a sonic enhancement was considered (simulated click) that it was believed would solve or at east reduce the problem. However, the problem was that this was an expert slip; it was serious when it occurred, but was very infrequent, perhaps happening only once every month or so.
Attempts to recreate it in a short 10 minute controlled experiment initially failed dramatically. Not only was it too infrequent to occur, even experts behaved more like novices in the artificial environment of a lab experiments, being more careful about their actions and monitoring the results.
One option in the current days of mass web deployment and perpetual beta, would be to have tried both alternatives as an A-B test, but it would be hard to detect even with massive volume as it was such an infrequent problem.
Instead, we turned back to the analysis of the problem and then crafted a task that created the otherwise infrequent expert slip. The final task involved typing numbers using an on-screen keyboard, clicking a button to confirm the number, and then moving to a distant button to request the next number to type. The subjects were put under time pressure (another classic manipulation to increase load), thus maximising the chance that they would slip off the confirm button whilst starting to move the mouse towards the ‘next’ button.
With this new task we immediately got up to a dozen missed errors in every experiment – we had recreated the infrequent expert slip with high frequency and even with novices. When the sonic enhancement was added, slips still occurred, but they were always noticed immediately, by all subjects, every time.
In the extreme one can produce deliberately tasks that are plain nasty!
One example this was in work to to understand natural inverse actions [GD15]. If you reverse in a car using your mirrors it is sometimes hard to know initially which way to turn the steering wheel, but if you turn and it is the wrong direction, or if you over-steer, you simply turn it the opposite way.
We wanted to create such a situation using effectively a Fitts’ Law style target acquisition tasks, with various mappings between two joysticks (in left and right hand) and on-screen pointers. The trouble was that when you reach for something in the real world, you tend to undershoot as overshooting would risk damaging the thing or injuring yourself. This behaviour persists even with an on-screen mouse pointer. However, we needed overshoots to be able to see what remedial action the participants would take.
In order to engineer overshoots we added a substantial random noise to the on-screen movements, so that the pointer behaved in an unpredictable way. The participants really hated us, but we did get a lot of overshoots!
Of course, creating such extreme situations means there are, yet again, problem of generalisation. This is fine if you are trying to understand some basic cognitive or perceptual ability, but less so if you are concerned with issues closer to real use. There is no magic bullet here, generalisation is never simply hand-turning algorithms on data, it is always a matter of the head – an argument based on evidence, some statistical, some qualitative, some theoretical, some experiential.
One of the on-going discussions in HCI is the choice between ‘in-the-wild’ studies [RM17] or controlled laboratory experiments. Of course there are also many steps in between, from semi-realistic settings recreated in a usability labs, to heavily monitored use in the real world.
In general the more control one has over the study, the less uncontrolled variation there is and hence the noise is smaller. In a fully in the wild setting people typically select their own tasks, may be affected by other people around, weather, traffic, etc. Each of these introduces variability.
However, one can still exercise a degree of control, even when conducting research in the wild.
One way is to use reduced tasks. Your participants are in a real situation, their home, office, walking down the street, but instead of doing what they like, you give them a scripted task to perform. Even though you lose some realism in terms of the chosen task, at least you still a level of ecological validity in the environment. These controlled tasks can be interspersed with free use, although this will introduce its own potential for interference as with within subjects experiment.
Another approach is use a restricted device or system. For example, you might lock a mobile phone so that it can only use the app being tested. By cutting down the functionality of the device or application, you can ensure that free use is directed towards the aspects that you wish to study.
A few years ago, before phones all had GPS, one proposed mode of interaction involved taking a photograph and then having image recognition software use it to work out what you were looking at in order to offer location-specific services, such as historical information or geo-annotation [WT04].
Some colleagues of mine were interested in how the accuracy of the image recognition affected the user experience. In order to study this, they modified a version of their mobile tourist guide and added this as a method to enable location. The experimental system used Wizard of Oz prototyping: when the user took a photograph, this was sent to one of the research team who was able to match it against the actual buildings in the vicinity. This yielded a 100% accurate match, but the system then added varying amounts of random errors to emulate automated image recognition.
In order to ensure that the participants spent sufficient time using the image location part, the functionality of the mobile tourist guide was massively reduced, with most audio-visual materials removed and only basic textual information retained for each building or landmark. By doing this, the participants looked at many different landmarks, rather than spending a lot of time on a few, and thus ensured the maximum amount of data concerning the aspect of interest.
The rather concerning downside of this story is that many of the reviewers did not understand this scientific approach and could not understand why it did not use the most advanced media! Happily it was eventually published at mobileHCI [DC05].
[GD15] Masitah Ghazali, Alan Dix and Kiel Gilleade (2015). The relationship of physicality and its underlying mapping. In 4th International Conference on Research and Innovation in Information Systems 2015, 8-10 December 2015, Malacca (best paper award). Also published in ARPN Journal of Engineering and Applied Science, December 2015, Vol. 10 No. 2). https://alandix.com/academic/papers/ICRIIS-2015-physicality/
[RM17] Yvonne Rogers and Paul Marshall (2017). Research in the Wild. Synthesis Lectures on Human-Centered Informatics. Morgan Claypool. DOI: 10.2200/S00764ED1V01Y201703HCI037
[WT04] Wilhelm, A., Takhteyev, Y., Sarvas, R., Van House, N. and Davis. M.: Photo Annotation on a Camera Phone. Extended Abstracts of CHI 2004. Vienna, Austria. ACM Press, 1403-1406, 2004. DOI: 10.1145/985921.986075
One set of strategies for gaining power are about the way you choose and manage your participants.
We will see strategies that address all three aspects of the noise–effect–number triangle:
more subjects or trials (increase number)
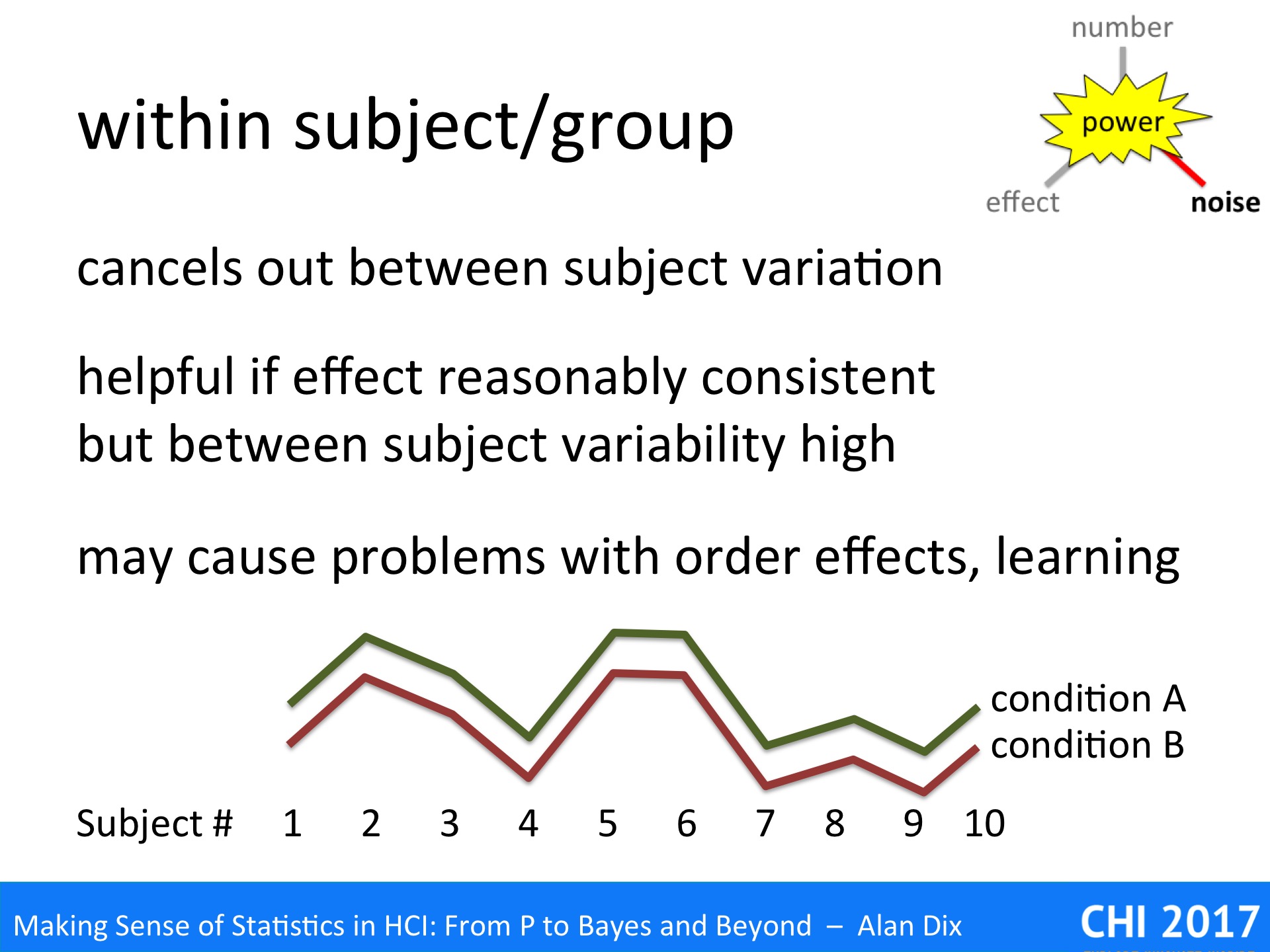
within subject/group (reduce noise)
matched users (reduce noise)
targeted user group (increase effect)
First of all is the most common approach: to increase either the number of subjects in your experiment or study, or the number of trials or measurements you make for each one.
Increasing the number of subjects helps average out any differences between subjects due to skill, knowledge, age, or simply the fact that all of us are individuals.
Increasing the number of trials (in a controlled experiment), or measurements, can help average out within subject variation. For example, in Fitts’ Law experiments, given the same target positions, distances and sizes, each time you would get a different response time, it is the average for an individual that is expected to obey Fitts’ Law.
Of course, whether increasing the number of trials or the number of subjects, the points, that we’ve discussed a few times already, remains — you have t increase the number a lot to make a small difference in power. Remember the square root in the formula. Typically to reduce the variation of the average by two you need to quadruple the number of subjects or trials; this sounds do-able. However, if you need to decrease the variability of the mean by a factor of then then you need one hundred times as many participants or trials.
In Paul Fitts’ original experiment back in 1954 [Fi54], he had each subject try 16 different conditions of target size and distance, as well as two different stylus weights. That is he was performing what is called a within subjects experiment.
An alternative experiment could have taken 32 times as many participants, but have each one perform for a single condition. With enough participants this probably would have worked, but the number would probably have needed to be enormous.
For low-level physiological behaviour, the expectation is that even if speed and accuracy differ between people, the overall pattern will be the same; that is we effectively assume between subject variation of parameters such as Fitts’ Law slope will be far less than within subject per-trial variation.
Imagine we are comparing two different experimental systems A and B, and have recorded users’ average satisfaction with each. The graph in the slide above has the results (idealised not real data). If you look at the difference for each system A is always above system B, there is clearly an effect. However, imagine jumbling them up, as if you had simply asked two completely different sets of subjects, one for system A and one for system B – the difference would probably not have shown up due to the large between subject differences.
The within subject design effectively cancels out these individual differences.
Individual differences are large enough between people, but are often even worse when performing studies involving groups of people collaborating. As well as the different people within the groups, there will be different social dynamics at work within each group. So, if possible within group studies perhaps even more important in this case.
However, as we have noted, increased power comes with cost, in the case of within subject designs the main problem is order effects.
For a within subjects/groups experiment, each person must take part in at least two conditions. Imagine this is a comparison between two interface layouts A and B, and you give each participant system A first and then system B. Suppose they perform better on system B, this could simply be that they got used to the underlying system functionality — a learning effect. Similarly, if system B was worse, this may simply be that users got used to the particular way that system A operated and so were confused by system B — an interference effect.
The normal way to address order effects, albeit partially, is to randomise or balance the orders; for example, you would do half the subjects in the order A–B and half in the order B–A. More complex designs might include replications of each condition such as ABBA, BAAB, ABAB, BABA.
Fitts’ original experiment did a more complex variation of this, with each participant being given the 16 conditions (of distance and size) in a random order and then repeating the task later on the same day in the opposite order.
These kinds of designs allow one to both cancel out simple learning/interference effects and even model how large they are. However, this only works if the order effects are symmetric; if system A interferes with system B more than vice versa, there will still be underlying effects. Furthermore, it is not so unusual that one of the alternatives is the existing one that users are used to in day-to-day systems.
There are more sophisticated methods, for example giving each subject a lot of exposure to each system and only using the later uses to try to avoid early learning periods. For example, ten trials with system A followed by ten with system B, or vice versa, but ignoring the first five trials for each.
For within-subjects designs it would be ideal if we could clone users so that there are no learning effects, but we can still compare the same user between conditions.
One way to achieve this (again partially!) is to have different user, but pair up users who are very similar, say in terms of gender, age, or skills.
This is common in educational experiments, where pre-scores or previous exam results are used to rank students, and then alternate students are assigned to each condition (perhaps two ways to teach the same material). This is effectively matching on current performance.
Of course, if you are interested in teaching mathematics, then prior mathematics skills are an obvious thing to match. However, in other areas it may be less clear, and if you try to match on too many attributes you get combinatorial explosion: so many different combinations of attributes you can’t find people that match on them all.
In a way matching subjects on an attribute is like measuring the attribute and fittings a model to it, except when you try to fit an attribute you usually need some model of how it will behave: for example, if you are looking at a teaching technique, you might assume that post-test scores may be linearly related to the students’ previous year exam results. However, if the relationship is not really linear, then you might end up thinking you have fond a result, which was in fact due to your poor model. Matching subjects makes your results far more robust requiring fewer assumptions.
A variation on matched users is to simply choose a very narrow user group. In some ways you are matching by making them all the same. For example, you may deliberately choose 20 year old college educated students … in fact you may do that by accident if you perform your experiments on psychology students! Looking back at Fitts original paper [Fi54] says, “Sixteen right-handed college men serves as Ss (Subjects)”, so there is good precident. By choosing participants of the same age and experience you get rid of a lot of the factors that might lead to individual differences. Of course there will still be personal differences due to the attributes you haven’t constrained, but still you will be reducing the overall noise level.
The downside of course, is that this then makes it hard to generalise. Fitts’ results were for right-handed college men; do his results also hold for college women, for left-handed people, for older or younger or less well educated men? Often it is assumed that these kinds of low level physiological experiments are similar in form across different groups of people, but this may not always be the case.
Henrich, Heine and Norenzayan [HH10] reviewed at a number of psychological results that looked as though they should be culturally independent. The vast majority of fundamental experiments were performed on what they called WEIRD people (Western, Educated, Industrialized, Rich, and Democratic), but where there were results form people of radically different cultural backgrounds, there were often substantial differences. This even extended to low-level perceptions.
You may have seen the Müller-Lyer illusion: the lower line looks longer, but in fact both lines are exactly the same length. It appears that this illusion is not innate, but due to being brought up in an environment where there are lots of walls and rectilinear buildings. When children and adults from tribes in jungle environments are tested, they do not perceive the illusions and see the lines as the same length.
We can go one step further and deliberately choose a group for whom we believe we will see the maximum effect. For example, imagine that you have designed a new menu system, which you believe has a lower short-term memory requirement. If you test it on university students who are typically young and have been honing their memory skills for years, you may not see any difference. However, short-term memory loss is common as people age, so if you chose more elderly users you would be more likely to see the improvements due to your system.
In different circumstances, you may deliberately choose to use novice users as experts may be so practiced on the existing system that nothing you do makes any improvement.
The choice of a critical group means that even small differences in your system’s performance have a big difference for the targeted group; that is you are increasing the effect size.
Just as with the choice of a narrow type of user, this may make generalisation difficult, only more so. With the narrow, but arbitrary group, you may argue that in fact the kind of user does not matter. However, the targeted choice of users is specifically because you think the criteria on which you are choosing them does matter and will lead to a more extreme effect.
Typically in such cases you will use a theoretical argument in order to generalise. For example, suppose your experiment on elderly users showed a statistically significant improvement with your new system design. You might then use a combination of qualitative interviews and detailed analysis of logs to argue that the effect was indeed due to the reduced short-term memory demand of your new system. You might then argue that this effect is likely to be there for any group of users, creating and additional load and that even though this is not usually enough to be apparent, it will be interfering with other tasks the user is attempting to do with the system.
Alternatively, you may not worry about generalisation, if the effect you have found is important for a particular group of users, then it will be helpful for them – you have found your market!
References
[Fi54] Fitts, Paul M. (1954) The information capacity of the human motor system in controlling the amplitude of movement. Journal of Experimental Psychology, 47(6): 381-391, Jun 1954,. http://dx.doi.org/10.1037/h0055392
[HH10] Henrich J, Heine S, Norenzayan A. (2010). The weirdest people in the world? Behav Brain Sci. 2010 Jun;33(2-3):61-83; discussion 83-135. doi: 10.1017/S0140525X0999152X. Epub 2010 Jun 15.
The heart of gaining power in your studies is understanding the noise–effect–number triangle. Power arises from a combination of the size of the effect you are trying to detect, the size of the study (number of trails/participants) and the size of the ‘noise’ (the random or uncontrolled factors). We can increase power by addressing any one of these.
Cast your mind back to your first statistics course, or when you first opened a book on statistics.
The standard deviation (sd) is one of the most common ways to measure of the variability of a data point. This is often due to ‘noise’, or the things you can’t control or measure.
For example, the average adult male height in the UK is about 5 foot 9 inches ( with a standard deviation of about 3 inches (7.5cm), most British men are between 5′ 6″ (165cm) and 6′ (180cm) tall.
However, if you take a random sample and look at the average (arithmetic mean), this varies less as typically your sample has some people higher than average, and some people shorter than average, and they tend to cancel out. The variability of this average is called the standard error of the mean (or just s.e.), and is often drawn as little ‘error bars’ on graphs or histograms, to give you some idea of the accuracy of the average measure.
You might also remember that, for many kinds of data the standard error of the mean is given by:
s.e. = σ / √n (or if σ is an estimate √n-1 )
For example, of you have one hundred people, the variability of the average height is one tenth the variability of a single person.
The question you then have to ask yourself is how big an effect do you want to detect? Imagine I am about to visit Denmark. I have pretty good idea that Danish men are taller than British men and would like to check this. If the average were a foot (30cm) I definitely want to know as I’ll end up with a sore neck looking up all the time, but if it is just half an inch (1.25cm) I probably don’t care.
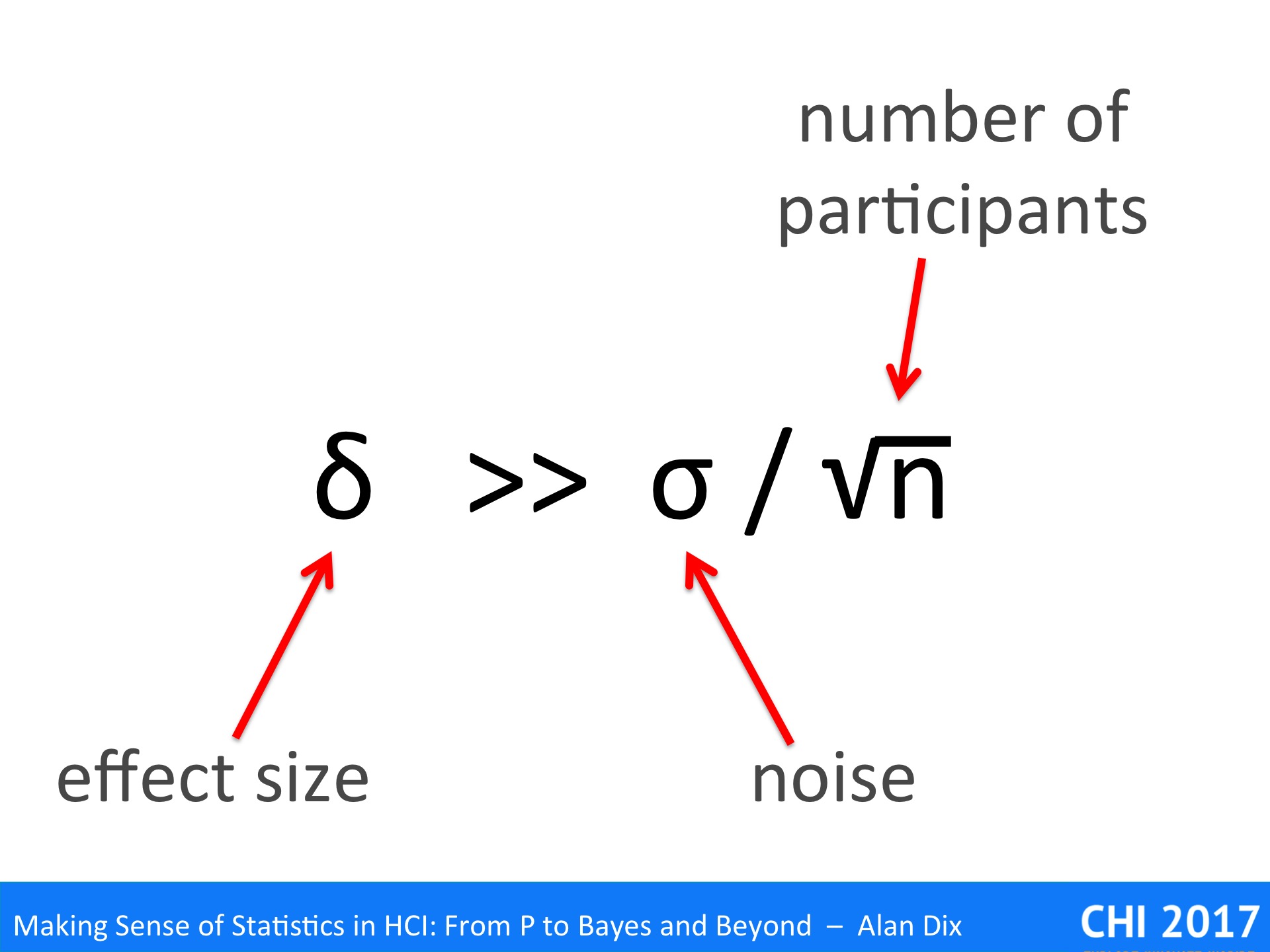
Let’s call this least difference that I care about δ (Greek letters, it’s a mathematician thing!), so in the example δ = 0.5 inch.
If I took a sample of 100 British men and 100 Danes, the standard error of the mean would be about 0.3 inch (~1cm) for each, so it would be touch and go if I’d be able to detect the difference. However, if I took a sample of 900 of each, then the s.e. of each average would be about 0.1 inch, so I’d probably be easily able to detect differences of 0.5 inch.
In general, we’d like the minimum difference we want to detect to be substantially bigger than the standard error of the mean in order to be able to detect the difference. That is:
δ >> σ / √n
Note the three elements here:
the effect size
the amount of noise or uncontrolled variation
the number of participants, groups or trials
Although the meanings of these vary between different kinds of data and different statistical methods, the basic triad is similar. This is even in data, such as network power-law, where the standard deviation is not well defined and other measures of spread or variation apply (Remember that this is a different use of the term ‘power’). In such data it is not the square root of participants that is the key factor, but still the general rule that you need a lot more participants to get greater accuracy in measures … only for power law data the ‘more’ is even greater than squaring!
Once we understand that statistical power is about the relationship between these three factors, it becomes obvious that while increasing the number of subjects is one way to address power, it is not the only way. We can attempt to effect any one of the three, or indeed several while designing our user studies or experiments.
Thinking of this we have three general strategies:
increase number – As mentioned several times, this is the standard approach, and the only one that many people think about. However, as we have seen, the square root means that we often need very lareg increase in the number of subjects or trials in order to reduce the variability of our results to acceptable level. Even when you have addressed other parts of the noise–effect–number triangle, you still have to ensure you have sufficient subjects, although hopefully less than you would need by a more naïve approach.
reduce noise – Noise is about variation due to actors that you do not control or know about; so, we can attempt to attack either of these. First we can control conditions reducing the variability in our study; this is the approach usually take in physics and other sciences, using very pure substances, with very precise instruments in controlled environments. Alternatively, we can measure other factors and fit or model the effect of these, for example, we might ask the participants’ age, prior experience, or other things we think may affect the results of our study.
increase effect size – Finally, we can attempt to manipulate the sensitivity of our study. A notable example of this is the photo from the back of the crowd at President Trump’s inauguration. It was very hard to assess differences in crowd size at different events from the photos taken from the front of the crowd, but photos at the back are a far more sensitive. Your studies will probably be less controversial, but you can use the same technique. Of course, there is a corresponding danger of false baselines, in that we may end up with a misleading idea of the size of effects — as noted previously with power comes the responsibility to report fairly and accurately.
In the following two posts, we will consider strategies that address the factors of the noise–effect–number triangle in different ways. We will concentrate first on the subjects, the users or participants in our studies, and then on the tasks we give them to perform.

 from what happens to how and why – when quantitative and qualitative meet
from what happens to how and why – when quantitative and qualitative meet