I’ve been at home for the last week after six weeks travelling around the UK and elsewhere. I’ve not kept up while on the road so doing a retrospective post on it all and need to try to catch on other half written posts.
As well as time at Talis offices in B’ham and at Lancs (including exam board week), travels have taken me to Pisa for a workshop on ‘Supportive User Interfaces’, to Koblenz for Web Science conference giving a talk on embodiment issues and a poster on web-scale reasoning , to Newcastle for British HCI conference doing a talk on fridge, to Nottingham to give a talk on extended episodic experience, and back to Lancs for a session on creativity! Why can’t I be like sensible folks and talk on one topic!
Supportive User Interfaces
 Monday 13th June I attended a workshop in Pisa on “Supportive User Interfaces“, which includes interfaces that adapt in various ways to users. The majority of people there were involved in various forms of model-based user interfaces in which various models of the task, application and interaction are used to generate user interfaces on the fly. W3C have had a previous group in this area; Dave Raggett from w3c was at the workshop and it sounds like there will be a new working group soon. This clearly has strong links to various forms of ‘meta-level’ representations of data, tasks, etc.. My own contribution started the day, framing the area, focusing partly on reasons for having more ‘meta-level’ interfaces including social empowerment, and partly on the principles/techniques that need to be considered at a human level.
Monday 13th June I attended a workshop in Pisa on “Supportive User Interfaces“, which includes interfaces that adapt in various ways to users. The majority of people there were involved in various forms of model-based user interfaces in which various models of the task, application and interaction are used to generate user interfaces on the fly. W3C have had a previous group in this area; Dave Raggett from w3c was at the workshop and it sounds like there will be a new working group soon. This clearly has strong links to various forms of ‘meta-level’ representations of data, tasks, etc.. My own contribution started the day, framing the area, focusing partly on reasons for having more ‘meta-level’ interfaces including social empowerment, and partly on the principles/techniques that need to be considered at a human level.
Also on Monday was a meeting of IFIP Working Group 2.7/13.4. IFIP is the UNESCO founded pan-national agency that national computer societies such as as the BCS in the UK and ACM and IEEE Computer in the US belong to. Working Group 2.7/13.4 is focused on the engineering of user interfaces. I had been actively involved in the past, but have had many years’ lapse. However, this seemed a good thing to re-engage with with my new Talis hat on!
SUI: paper:
Web Science Conference in Koblenz
Jaime Teevan from Microsoft gave the opening keynote at WebSci 2011. I know her from her earlier work on personal information management, but her recent work and keynote was about work on analysing and visualising changes in web pages. Web page changes are also analysed alongside users re-visitation patterns; by looking at the frequency of re-visitation Jaime and her colleagues are able to identify the parts of pages that change with similar frequency, helping them, inter alia, to improve search ranking.
Had many great conversations, some with people I know previously (e.g. the Southampton folks), but also new, including the group at Troy that do lots of work with data.gov. I was particularly interested in some work using content matching to look for links between otherwise unlinked (or only partly inter-linked) datasets. Also lots of good presentations including one on trust prediction and a fantastic talk by Mark Bernstein from Eastgate, which he delivered in blank verse!
 My own contribution included the poster that Dave@Talis prepared, which was on the web-scale spreading activation work in collaboration with Univ. Athens. Quite a niche area in a multi-disciplinary conference, so didn’t elicit quite the interest of the social networking posters, but did lead to a small number of in depth discussions.
My own contribution included the poster that Dave@Talis prepared, which was on the web-scale spreading activation work in collaboration with Univ. Athens. Quite a niche area in a multi-disciplinary conference, so didn’t elicit quite the interest of the social networking posters, but did lead to a small number of in depth discussions.
In addition I gave talk on the more cognitive/philosophical issues when we start to use the web as an external extension to / replacement of memory, including its impact on education. Got some good feedback from this.
Closing keynote was from Barry Wellman, the guy who started social network analysis way before they were on computers. At one point he challenged the Dunbar number. I wondered whether this was due to cognitive extension with address books etc., but he didn’t seem to think so; there is evidence that some large circles predate web (although maybe not physical address books). Made me wonder about itinerant tradesmen, tinkers, etc., even with no prostheses. Maybe the numbers sort of apply to any single content, but are repeated for each new context?
WebSci papers:
The HCI Conference – Newcastle
I attended the British HCI conference in Newcastle. This was the 25th conference, and as my very first academic paper in computing was at the first BHCI in 1984, I was pleased to be there at this anniversary. The paper I was presenting was a retrospective on vfridge, a social networking site dating back to 1999/2000, it seemed an historic occasion!

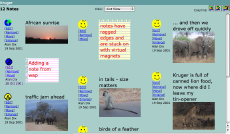
As is always the case presentations were all interesting. Strictly BHCI is a ‘second tier’ conference compared with CHI, but why is it that the papers are always more interesting, that I learn more? It is likely that a fair number of papers were CHI rejects, so it should be the other way round – is it that selectivity and ‘quality’ inevitably become conservative and boring?
Gregory Abowd gave the closing keynote. It was great to see Gregory again, we meet too rarely. The main focus of his keynote was on three aspects of research: novelty, value and reliability and how his own work had moved within this space over the years. In particular having two autistic sons has led him in directions he would never have considered, and this immediately valuable work has also created highly novel research. Novelty and value can coexist.
Gregory also reflected on the BHCI conference as it was his early academic ‘home’ when he did his PhD and postdoctoral here in the late 1980’s. He thought that it could be rather than, as with many conferences, a second best to getting a CHI paper, instead a place for (not getting the quote quite perfect) “papers that should get into CHI”, by which he meant a proving ground for new ideas that would then go on to be in CHI.
 However I initially read the quote differently. BHCI always had a broader concept of HCI compare with CHI’s quite limited scope. That is BHCI as a place that points the way for the future of HCI, just as it was the early nurturing place of MobileHCI. However CHI has now become much broader in it’s own conception, so maybe this is no longer necessary. Indeed at the althci session the organisers said that their only complaint was that the papers were not ‘alt’ enough – that maybe ‘alt’ had become mainstream. This prompted Russell Beale to suggest that maybe althci should now be real science such as replication!
However I initially read the quote differently. BHCI always had a broader concept of HCI compare with CHI’s quite limited scope. That is BHCI as a place that points the way for the future of HCI, just as it was the early nurturing place of MobileHCI. However CHI has now become much broader in it’s own conception, so maybe this is no longer necessary. Indeed at the althci session the organisers said that their only complaint was that the papers were not ‘alt’ enough – that maybe ‘alt’ had become mainstream. This prompted Russell Beale to suggest that maybe althci should now be real science such as replication!
Gregory also noted the power of the conference as a meeting ground. It has always been proud of the breadth of international attendance, but perhaps it is UK saturation that should be it’s real measure of success. Of course the conference agenda has become so full and international travel so much cheaper than it was, so there is a tendency to go to the more topic specific international conferences and neglect the UK scene. This is compounded by the relative dearth of small UK day workshops that used to be so useful in nurturing new researchers.
 I feel a little guilty here as this was the first BHCI I had been to since it was in Lancaster in 2007 … as Tom McEwan pointed out I always apologise but never come! However, to be fair I have also only been twice to CHI in the last 10 years, and then when it was in Vienna and Florence. I have just felt too busy, so avoiding conferences that I did not absolutely have to attend.
I feel a little guilty here as this was the first BHCI I had been to since it was in Lancaster in 2007 … as Tom McEwan pointed out I always apologise but never come! However, to be fair I have also only been twice to CHI in the last 10 years, and then when it was in Vienna and Florence. I have just felt too busy, so avoiding conferences that I did not absolutely have to attend.
In response to Gregory’s comments, someone, maybe Tom, mentioned that in days of metrics-based research assessment there was a tendency to submit one’s best work to those venues likely to achieve highest impact, hence the draw of CHI. However, I have hardly ever published in CHI and I think only once in TOCHI, yet, according to Microsoft Research, I am currently the most highly cited HCI researcher over the last 5 years … So you don’t have to publish in CHI to get impact!
And incidentally, the vfridge paper had NOT been submitted to CHI, but was specially written for BHCI as it seemed the fitting place to discuss a thoroughly British product 🙂
vfridge paper:
Nottingham MRL
I was at Mixed Reality Lab in Nottingham for Joel Fischer‘s PhD viva and while there did a seminar the afternoon on “extended episodic experience” based on Haliyana Khalid‘s PhD work and ideas that arose from it. Basically, whereas ‘user experience’ has become a big issue most of the work is focused on individual ‘experiences’ whereas much of life consists of ongoing series of experiences (episodes) which together make up the whole experience of interacting with a person or place, following a band, etc.
I had obviously not done a good enough job at wearing Joel down with difficult questions in the PhD viva in the morning as he was there in the afternoon to ask difficult questions back of his own 😉
Docfest – Digital Economy Summer School
 The last major event was Docfest, which brought together the PhD students from the digital economy centres from around the country. Not sure of the exact count but just short of 150 participants I think. They come from a wide variety of backgrounds, business, design, computing, engineering, and many are mature students with years of professional experience behind them.
The last major event was Docfest, which brought together the PhD students from the digital economy centres from around the country. Not sure of the exact count but just short of 150 participants I think. They come from a wide variety of backgrounds, business, design, computing, engineering, and many are mature students with years of professional experience behind them.
 This looked like being a super event, unfortunately I was only able to attend for a day 🙁 However, I had a great evening at the welcome event talking with many of the students and even got to ride in Steve Forshaw‘s Sinclair C5!
This looked like being a super event, unfortunately I was only able to attend for a day 🙁 However, I had a great evening at the welcome event talking with many of the students and even got to ride in Steve Forshaw‘s Sinclair C5!
My contribution to the event was running the first morning session on ‘creativity’. Surprise, surprise this started with a bad ideas session, but new for me too as the largest group I’ve run in the past has been around 30. There were a number of local Highwire students acting as facilitators for the groups, so I had only to set them off and observe results :-). At the end of the morning I gave some the theoretical background to bad ideas as a method and in understanding (aspects of) creativity more widely.
Other speakers at the event included Jane Prophet, Chris Csikszentmihalyi and Chris Bonnington, so was sad to miss them; although I did get a fascinating chat with Jane over breakfast in the hotel hearing about her new projects on arts and neural imaging, and on how repetitious writing induces temporary psychosis … That is why the teachers give lines, to send the pupils bonkers!
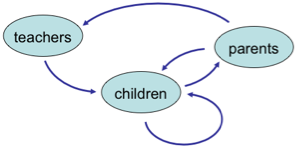


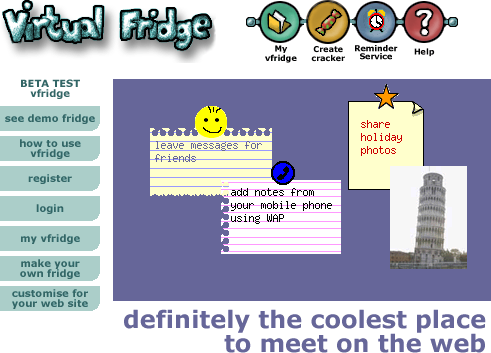
 The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door.
The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door. Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “
Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “
