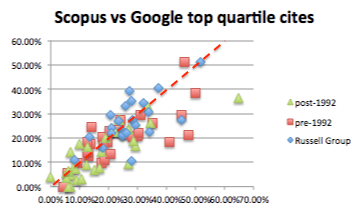
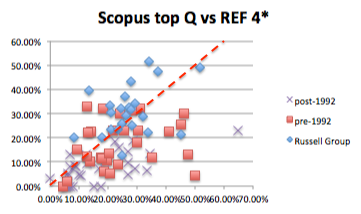
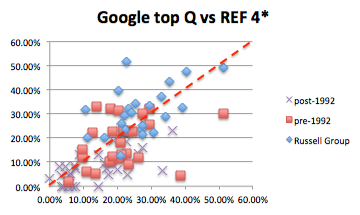
I was recently asked to clarify the difference between usability principles and guidelines. Having written a page-full of answer, I thought it was worth popping on the blog.
As with many things the boundary between the two is not absolute … and also the term ‘guidelines’ tends to get used differently at different times!
However, as a general rule of thumb:
- Principles tend to be very general and would apply pretty much across different technologies and systems.
- Guidelines tend to be more specific to a device or system.
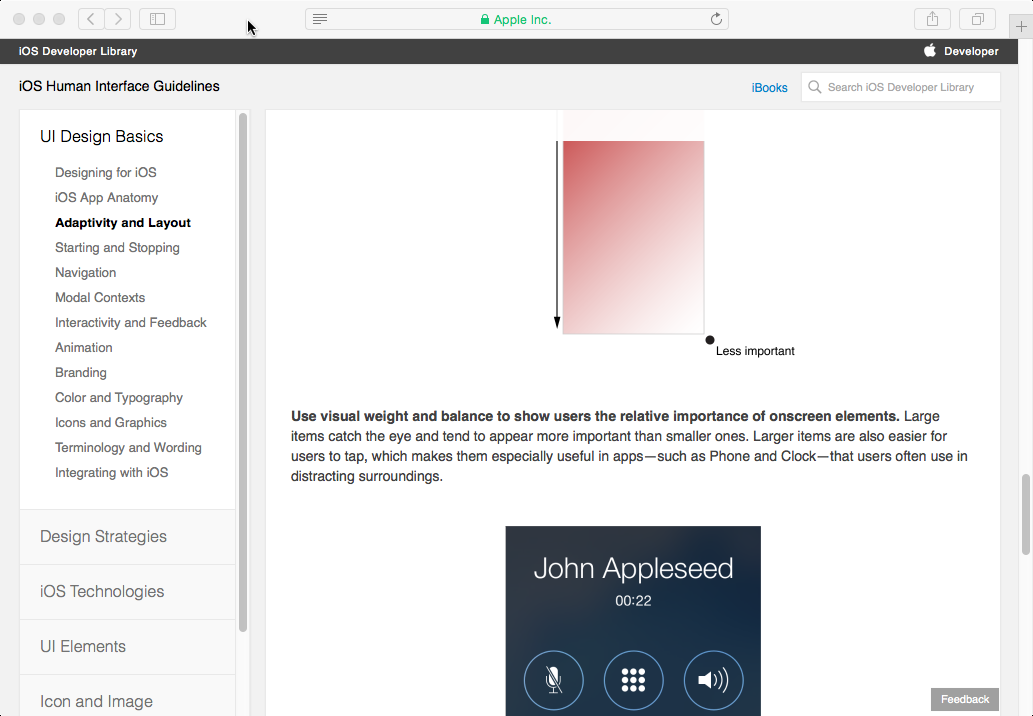
As an example of the latter, look at the iOS Human Interface Guidelines on “Adaptivity and Layout” It starts with a general principle:
“People generally want to use their favorite apps on all their devices and in multiple contexts”,
but then rapidly turns that into more mobile specific, and then iOS specific guidelines, talking first about different screen orientations, and then about specific iOS screen size classes.
I note that the definition on page 259 of Chapter 7 of the HCI textbook is slightly ambiguous. When it says that guidelines are less authoritative and more general in application, it means in comparison to standards … although I’d now add a few caveats for the latter too!
Basically in terms of ‘authority’, from low to high:
| lowest | principles | agreed by community, but not mandated |
|---|---|---|
| guidelines | proposed by manufacture, but rarely enforced | |
| highest | standards | mandated by standards authority |
In terms of general applicability, high to low:
| highest | principles | very broad e.g. ‘observability’ |
|---|---|---|
| guidelines | more specific, but still allowing interpretation | |
| lowest | standards | very tight |
This ‘generality of application’ dimension is a little more complex as guidelines are often manufacturer specific so arguably less ‘generally applicable’ than standards, but the range of situations that standard apply to is usually much tighter.
On the whole the more specific the rules, the easier they are to apply. For example, the general principle of observability requires that the designer think about how it applies in each new application and situation. In contrast, a more specific rule that says, “always show the current editing state in the top right of the screen” is easy to apply, but tells you nothing about other aspects of system state.