 Revisiting on an old paper on early email use and reflecting on scholarly communication now.
Revisiting on an old paper on early email use and reflecting on scholarly communication now.
About 30 years ago, I was at a meeting in London and heard a presentation about a study of early email use in Xerox and the Open University. At Xerox the use of email was already part of their normal culture, but it was still new at OU. I’d thought they had done a before and after study of one of the departments, but remembered clearly their conclusions: email acted in addition to other forms of communication (face to face, phone, paper), but did not substitute.
 It was one of those pieces of work that I could recall, but didn’t have a reference too. Facebook to the rescue! I posted about it and in no time had a series of helpful suggestions including Gilbert Cockton who nailed it, finding the meeting, the “IEE Colloquium on Human Factors in Electronic Mail and Conferencing Systems” (3 Feb 1989) and the precise paper:
It was one of those pieces of work that I could recall, but didn’t have a reference too. Facebook to the rescue! I posted about it and in no time had a series of helpful suggestions including Gilbert Cockton who nailed it, finding the meeting, the “IEE Colloquium on Human Factors in Electronic Mail and Conferencing Systems” (3 Feb 1989) and the precise paper:
Fung , T. O’Shea , S. Bly. Electronic mail viewed as a communications catalyst. IEE Colloquium on Human Factors in Electronic Mail and Conferencing Systems, , pp.1/1–1/3. INSPEC: 3381096 http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=197821
In some extraordinary investigative journalism, Gilbert also noted that the first author, Pat Fung, went on to fresh territory after retirement, qualifying as a scuba-diving instructor at the age of 75.
The details of the paper were not exactly as I remembered. Rather than a before and after study, it was a comparison of computing departments at Xerox (mature use of email) and OU’s (email less ingrained, but already well used). Maybe I had simply embroidered the memory over the years, or maybe they presented newer work at the colloquium, than was in the 3 page extended abstract. In those days this was common as researchers did not feel they needed to milk every last result in a formal ‘publication’. However, the conclusions were just as I remembered:
“An exciting finding is its indication that the use of sophisticated electronic communications media is not seen by users as replacing existing methods of communicating. On the contrary, the use of such media is seen as a way of establishing new interactions and collaboration whilst catalysing the role of more traditional methods of communication.”
As part of this process following various leads by other Facebook friends, I spent some time looking at early CSCW conference proceedings, some at Saul Greenburg’s early CSCW bibliography [1] and Ducheneaut and Watts (15 years on) review of email research [2] in the 2005 HCI special issue on ‘reinventing email’ [3] (both notably missing the Fung et al. paper). I downloaded and skimmed several early papers including Wendy McKay’s lovely early (1988) study [4] that exposed the wide variety of ways in which people used email over and above simple ‘communication’. So much to learn from this work when the field was still fresh,
This all led me to reflect both on the Fung et al. paper, the process of finding it, and the lessons for email and other ‘communication’ media today.
Communication for new purposes
A key finding was that “the use of such media is seen as a way of establishing new interactions and collaboration“. Of course, the authors and their subjects could not have envisaged current social media, but the finding if this paper was exactly an example of this. In 1989 if I had been trying to find a paper, I would have scoured my own filing cabinet and bookshelves, those of my colleagues, and perhaps asked people when I met them. Nowadays I pop the question into Facebook and within minutes the advice starts to appear, and not long after I have a scanned copy of the paper I was after.
Communication as a good thing
In the paper abstract, the authors say that an “exciting finding” of the paper is that “the use of sophisticated electronic communications media is not seen by users as replacing existing methods of communicating.” Within paper, this is phrased even more strongly:
“The majority of subjects (nineteen) also saw no likelihood of a decrease in personal interactions due to an increase in sophisticated technological communications support and many felt that such a shift in communication patterns would be undesirable.”
Effectively, email was seen as potentially damaging if it replaced other more human means of communication, and the good outcome of this report was that this did not appear to be happening (or strictly subjects believed it was not happening).
However, by the mid-1990s, papers discussing ’email overload’ started to appear [5].
I recall a morning radio discussion of email overload about ten years ago. The presenter asked someone else in the studio if they thought this was a problem. Quite un-ironically, they answered, “no, I only spend a couple of hours a day”. I have found my own pattern of email change when I switched from highly structured Eudora (with over 2000 email folders), to Gmail (mail is like a Facebook feed, if it isn’t on the first page it doesn’t exist). I was recently talking to another academic who explained that two years ago he had deliberately taken “email as stream” as a policy to control unmanageable volumes.
If only they had known …
Communication as substitute
While Fung et al.’s respondents reported that they did not foresee a reduction in other forms of non-electronic communication, in fact even in the paper the signs of this shift to digital are evident.
Here are the graphs of communication frequency for the Open University (30 people, more recent use of email) and Xerox (36 people, more established use) respectively.
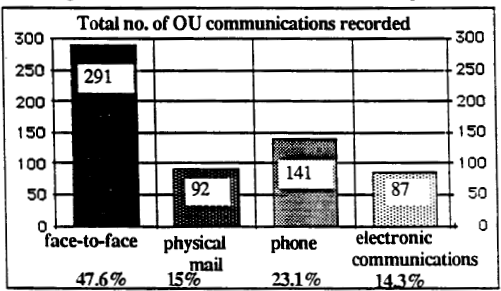
( from Fung et al., 1989)
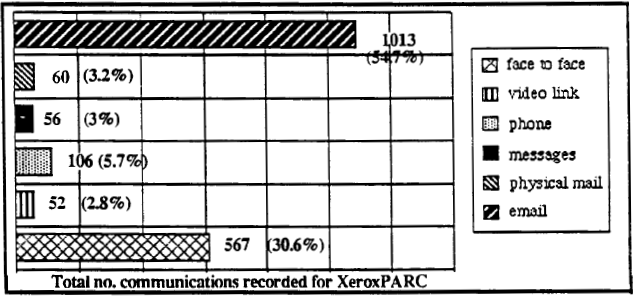
( from Fung et al., 1989)
It is hard to draw exact comparisons as it appears there may have been a higher overall volume of communication at Xerox (because of email?). Certainly, at that point, face-to-face communication remains strong at Xerox, but it appears that not only the proportion, but total volume of non-digital non-face-to-face communications is lower than at OU. That is sub substitution has already happened.
Again, this is obvious nowadays, although the volume of electronic communications would have been untenable in paper (I’ve sometimes imagined printing out a day’s email and trying to cram it in a pigeon-hole), the volume of paper communications has diminished markedly. A report in 2013 for Royal Mail recorded 3-6% pa reduction in letters over recent years and projected a further 4% pa for the foreseeable future [6].
academic communication and national meetungs
However, this also made me think about the IEE Colloquium itself. Back in the late 1980s and 1990s it was common to attend small national or local meetings to meet with others and present work, often early stage, for discussion. In other fields this still happens, but in HCI it has all but disappeared. Maybe I have is a little nostalgia, but this does seem a real loss as it was a great way for new PhD students to present their work and meet with the leaders in their field. Of course, this can happen if you get your CHI paper accepted, but the barriers are higher, particularly for those in smaller and less well-resourced departments.
Some of this is because international travel is cheaper and faster, and so national meetings have reduced in importance – everyone goes to the big global (largely US) conferences. Many years ago research on day-to-day time use suggested that we have a travel ‘time budget’ reactively constant across counties and across different kinds of areas within the same country [7]. The same is clearly true of academic travel time; we have a certain budget and if we travel more internationally then we do correspondingly less nationally.
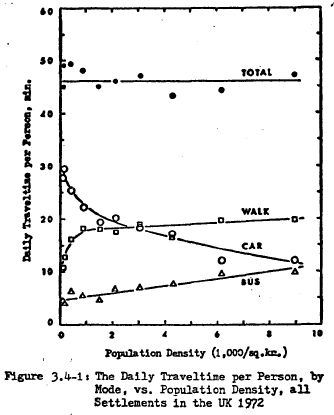
(from Zahavi, 1979)
However, I wonder if digital communication also had a part to play. I knew about the Fung et al. paper, even though it was not in the large reviews of CSCW and email, because I had been there. Indeed, the reason that the Fung et al.paper was not cited in relevant reviews would have been because it was in a small venue and only available as paper copy, and only if you know it existed. Indeed, it was presumably also below the digital radar until it was, I assume, scanned by IEE archivists and deposited in IEEE digital library.
However, despite the advantages of this easy access to one another and scholarly communication, I wonder if we have also lost something.
In the 1980s, physical presence and co-presence at an event was crucial for academic communication. Proceedings were paper and precious, I would at least skim read all of the proceedings of any event I had been to, even those of large conferences, because they were rare and because they were available. Reference lists at the end of my papers were shorter than now, but possibly more diverse and more in-depth, as compared to more directed ‘search for the relevant terms’ literature reviews of the digital age.
And looking back at some of those early papers, in days when publish-or-perish was not so extreme, when cardiac failure was not an occupational hazard for academics (except maybe due to the Cambridge sherry allowance), at the way this crucial piece of early research was not dressed up with an extra 6000 words of window dressing to make a ‘high impact’ publication, but simply shared. Were things more fun?
[1] Saul Greenberg (1991) “An annotated bibliography of computer supported cooperative work.” ACM SIGCHI Bulletin, 23(3), pp. 29-62. July. Reprinted in Greenberg, S. ed. (1991) “Computer Supported Cooperative Work and Groupware”, pp. 359-413, Academic Press. DOI: http://dx.doi.org/10.1145/126505.126508
https://pdfs.semanticscholar.org/52b4/d0bb76fcd628c00c71e0dfbf511505ae8a30.pdf
[2] Nicolas Ducheneaut and Leon A. Watts (2005). In search of coherence: a review of e-mail research. Hum.-Comput. Interact. 20, 1 (June 2005), 11-48. DOI= 10.1080/07370024.2005.9667360
http://www2.parc.com/csl/members/nicolas/documents/HCIJ-Coherence.pdf
[3] Steve Whittaker, Victoria Bellotti, and Paul Moody (2005). Introduction to this special issue on revisiting and reinventing e-mail. Hum.-Comput. Interact. 20, 1 (June 2005), 1-9.
http://www.tandfonline.com/doi/abs/10.1080/07370024.2005.9667359
[4] Wendy E. Mackay. 1988. More than just a communication system: diversity in the use of electronic mail. In Proceedings of the 1988 ACM conference on Computer-supported cooperative work (CSCW ’88). ACM, New York, NY, USA, 344-353. DOI=http://dx.doi.org/10.1145/62266.62293
https://www.lri.fr/~mackay/pdffiles/TOIS88.Diversity.pdf
[5] Steve Whittaker and Candace Sidner (1996). Email overload: exploring personal information management of email. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’96), Michael J. Tauber (Ed.). ACM, New York, NY, USA, 276-283. DOI=http://dx.doi.org/10.1145/238386.238530
https://www.ischool.utexas.edu/~i385q/readings/Whittaker_Sidner-1996-Email.pdf
[6] The outlook for UK mail volumes to 2023. PwC prepared for Royal Mail Group, 15 July 2013
http://www.royalmailgroup.com/sites/default/files/ The%20outlook%20for%20UK%20mail%20volumes%20to%202023.pdf
[7] Yacov Zahavi (1979). The ‘UMOT’ Project. Prepared For U.S. Department Of Transportation Ministry Of Transport and Fed. Rep. Of Germany.
http://www.surveyarchive.org/Zahavi/UMOT_79.pdf
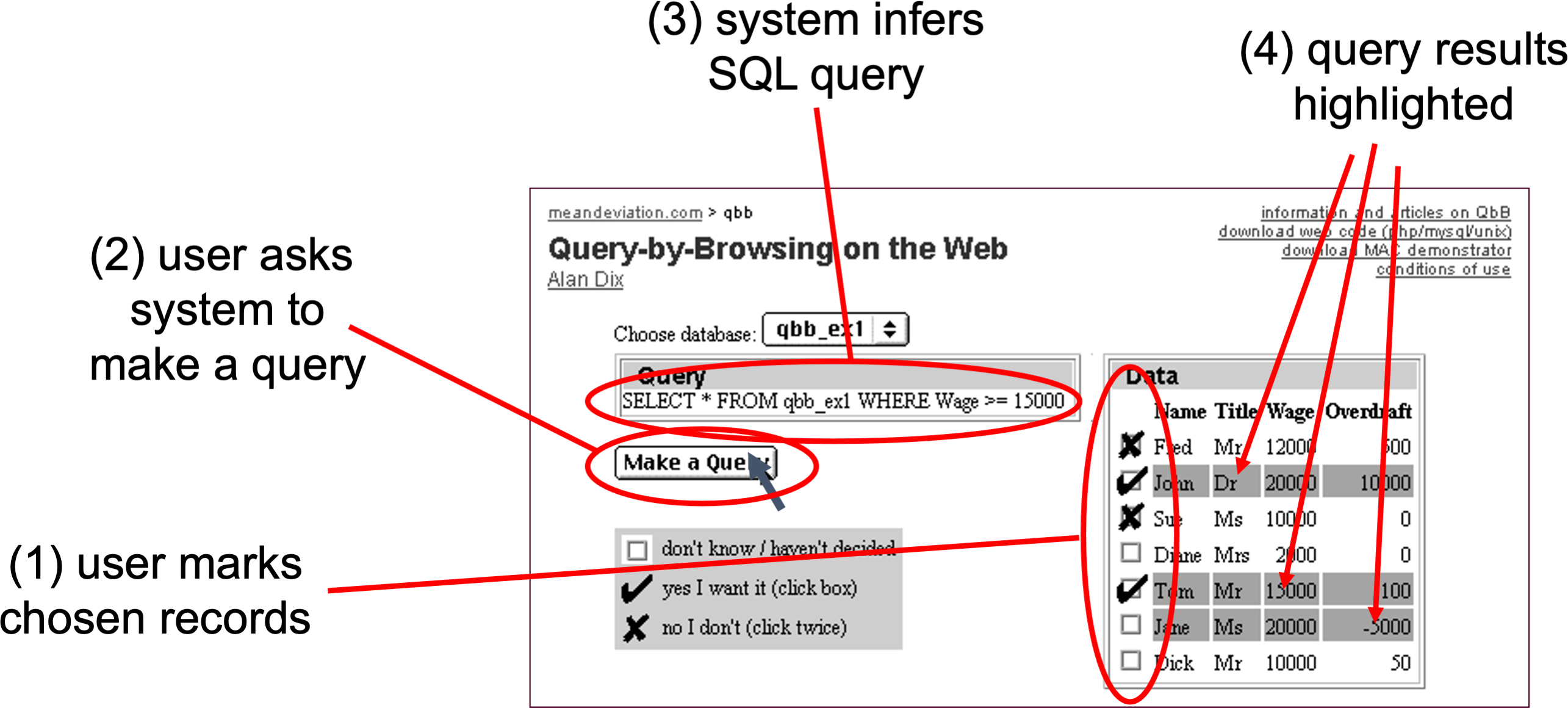
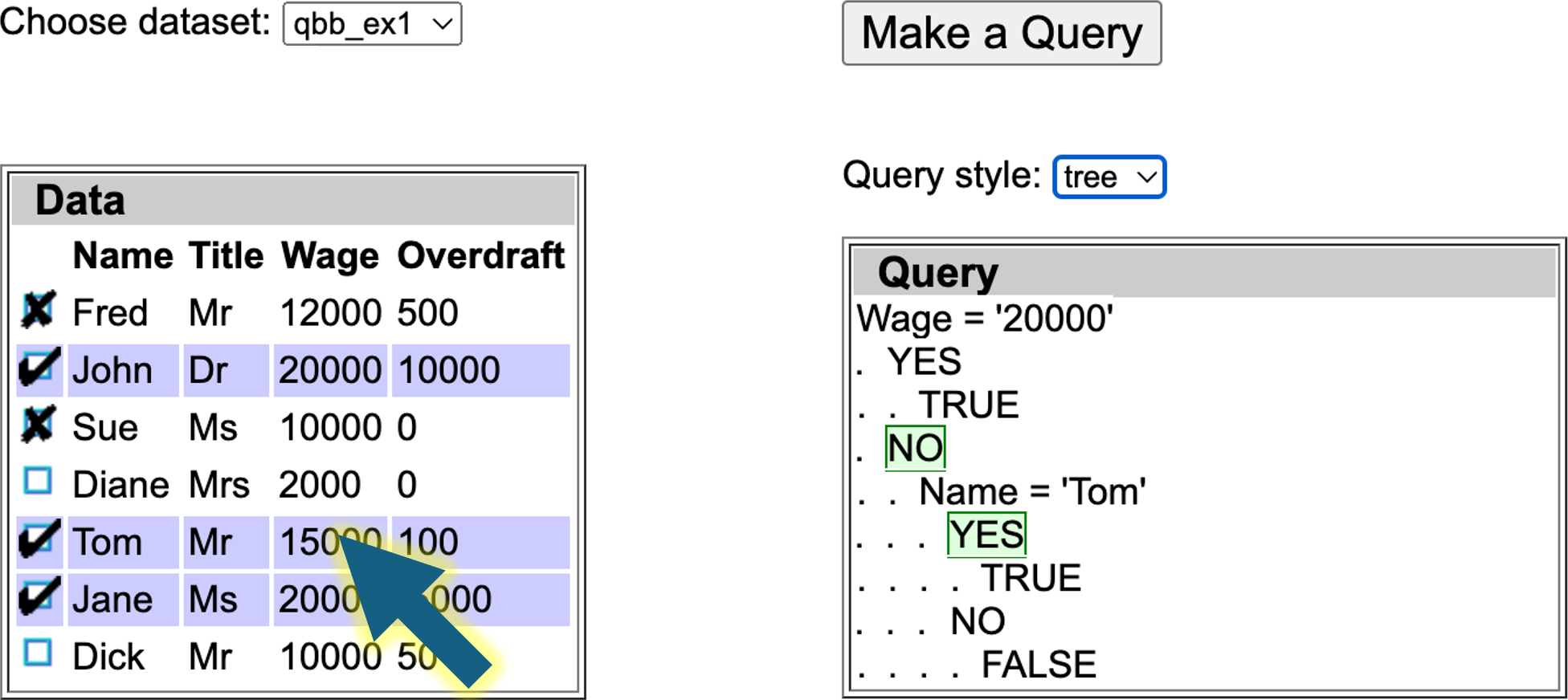
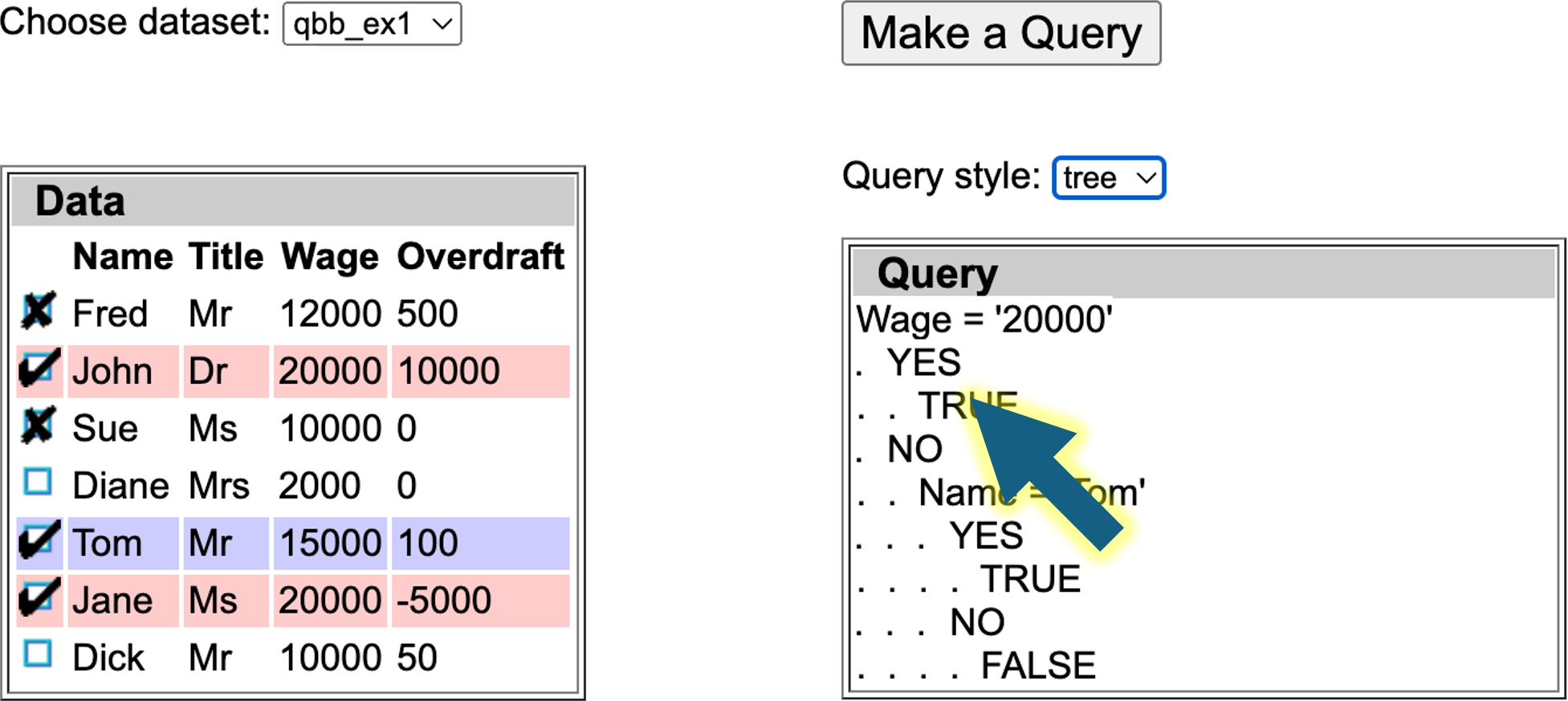
 For those who don’t remember
For those who don’t remember 







 While at Lancaster Jo Finney and I developed tiny intelligent lights. After more than ten years these are coming into commercial production.
While at Lancaster Jo Finney and I developed tiny intelligent lights. After more than ten years these are coming into commercial production. We have, I believe, the worlds first internet-enabled shop open sign. When the café is open, the sign is on, this is broadcast to a web service, which can then be displayed in various ways. It is very important in a rural area to know what is open, as you might have to drive many miles to get to a café or shop.
We have, I believe, the worlds first internet-enabled shop open sign. When the café is open, the sign is on, this is broadcast to a web service, which can then be displayed in various ways. It is very important in a rural area to know what is open, as you might have to drive many miles to get to a café or shop.