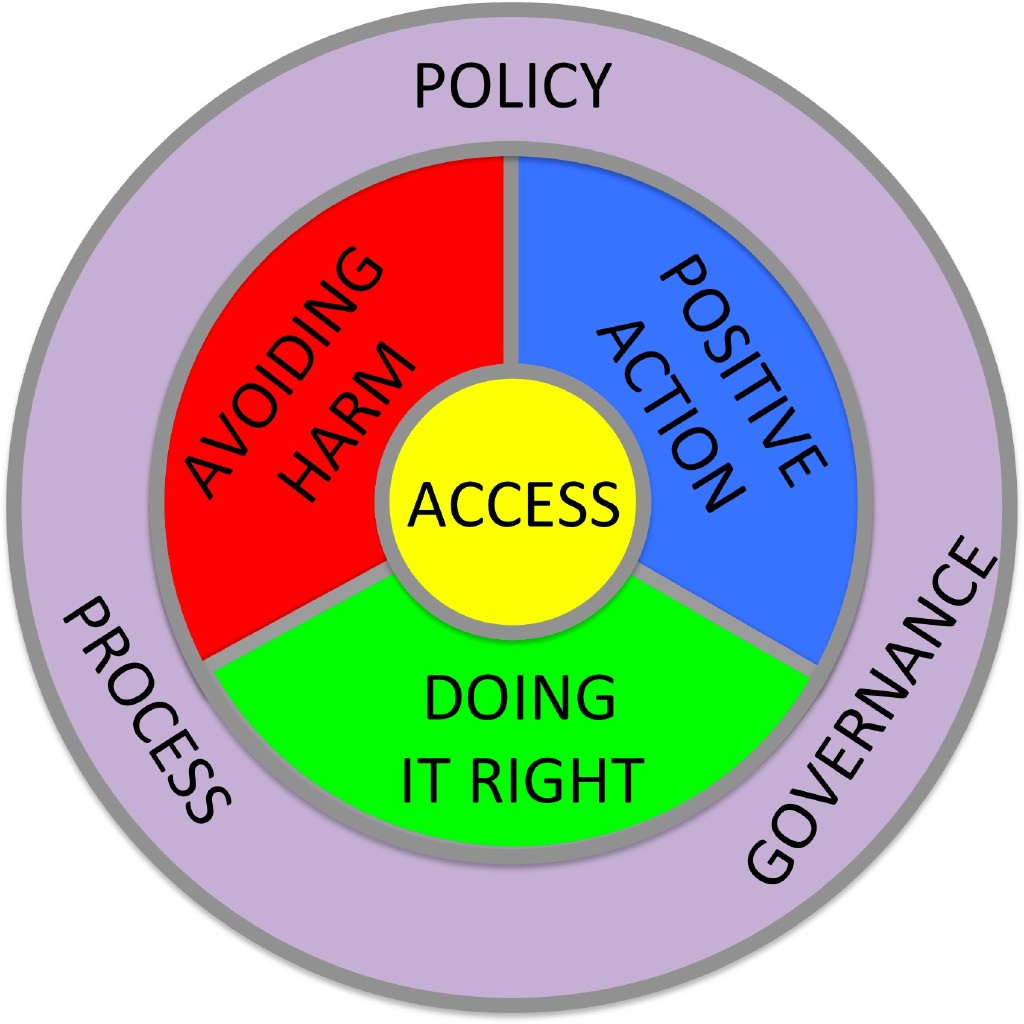
It all seems too big, requiring national and international responses. But we can make a difference using appropriately chosen small AI (including none). Plus, this good use of AI is good for business too.
This is the seventh of a series of blogs based on my keynote “The abomination of AI” at ICoSCI 2026. Each has an accompanying segment of the video and slides from the talk as well as detailed notes and references. Section numbers refer to the full report which will be released in the final blog. The slide thumbnails in the text correspond to the slides in the navigation panel below. The presentation can be played below, or opened full screen. The full length video, complete slides and further information can be found at: https://alandix.com/academic/talks/ICOSCI-2026-abomination-of-AI/
Previously …
§1. Every industry is driven by profits and power, but there is something about the nature of AI itself, which interacts with the nature of market forces in the world that is problematic and is different from other technologies.
§2. Can any technology be neutral? AI can be used for good purposes, such as advances in healthcare. It can also have bad outcomes such as bias in the criminal justice system or online exploitative pornography. Perhaps most often it is creating the frivolous or even ugly.
§3. The obvious impact of AI is in the things it does directly. Some technologies also change the very nature of society, affecting even those who do not use them. Cars are an obvious example. AI is also such a technology.
§4. Doomsayers worry about the point when AI becomes sentient, outgrowing its creators. The real danger is more insidious: the massive financial and human impacts of AI seem almost obscene.
§5. Network externalities, the way one person’s use of AI and digital tech changes its value for others, creates positive feedback loops, leading to runaway growth and emergent monopolies, the nemesis of free markets. This the very nature of digital technology and AI breaks free markets leading to runaway inequality, even with the best intentions of industry … but some tech companies further exploit these effects.
§6. Runaway growth of AI is not painless – opportunity costs of investment and human costs of lost jobs. Gains may be transitory – buy-now-pay-later tech risk tying users into spiralling costs.
7. What can we do?

These issues all seem too big, frighteningly so. So what can you do?
You might be a policy maker, or on a government committee that’s advising governments. If so, you might be in position to make changes at that scale. Most do not have such high-level influence, but there are changes you can make within your own spheres to help ameliorate some of these potential dangers. I’ll focus on the UX designer or AI developer, but some of the ideas are ones you might be able to adopt in your own personal use or within an organisation.
7.1 No AI

One option is to simply, say “no” to AI.
If you are a designer, ask, “do I need AI at all in my project?” Of course, everybody now expects every product to say ‘AI powered’, so you may not be able to avoid AI altogether, but it could be very simple AI. But do ask whether you need it at all, if you don’t, why are you feeling you need to use it?
7.2 Small AI

If you do decide to use AI, you can opt for small AI.
If you are using language models or other generative AI, you might use smaller models, the kind that have been deliberately designed to be able to run on less powerful hardware. There are many good reasons to do this. Indeed, Apple have been encouraging smaller AI because they want the AI to run on people’s personal devices, not just in the cloud. This is because privacy is a strong part of the company brand.
Where it is appropriate you could use traditional AI, which is usually much smaller in terms of memory and computation.

Purely from a technical perspective, there are some really interesting research challenges in this area, both in terms of human computer interaction (see my 2024 talk on ‘Patient Interaction’ [Dx24]) and also pure technical AI.

Images: [Di22,Sa23,Dx25,DS25]
You’ll have seen some of the modifications of algorithms that are transforming this landscape including open LLaMa [ZD22,TH23], LORA [HS22] and LiGO [WP23]. DeepSeek [DS24,DS25] made waves when US export restrictions on NVIDIA chips forced Chinese innovators to adopt a far leaner and smarter approach to LLM development [LF24]. Debatably DeepSeek’s learning might have piggybacked off some of the other LLMs [We25b], but certainly at execution time it used far less resources than other LLMs at time. Now other LLMs have adopted lessons from DeepSeek, and all are looking to perform more efficiently, so there is small shift in thinking away from a simplistic ‘bigger is better’ approach [Hi20].
7.3 When to use AI

There is also a choice about when to use AI.

The most obvious use of AI is at execution time in a user interface or delivered application as part of the service provided. This can of course be small AI or no AI at all even.
But you can also use AI at design time. You might use big AI to create small AI for the delivered system, for example using techniques to compress the model. You can also use AI as part of the UX process to critique a user interface, create rapid prototypes, or propose design ideas [Dx26b]. In addition, AI-based coding tools can create AI-free (or low-AI) systems.
Crucially, if you use big AI to help create a (smaller) product, it effectively gets reused again and again and again and again. So it’s less expensive – both moneywise expensive to a company, but also less expensive in terms of its impact on the environment and society.
In fact, this is really powerful use of AI. For instance, one of the things I argue elsewhere is that AI critiques of UIs will be far better for accessibility than even the best designers. This is in part because it is really hard for us to think about even obvious diversity such as what’s it like to be blind or deaf, or have a physical disability, an automated design tool can check a concept or prototype against vast numbers of different types of perceptual and physical abilities as well as combinations. Even more important, it is almost impossible for us to imagine what it’s like to be somebody who thinks differently, for example somewhere distant from ourselves in a neurodivergent space . I don’t think AI will be good at this, but I think it will be better than we are.
7.4 How to use AI

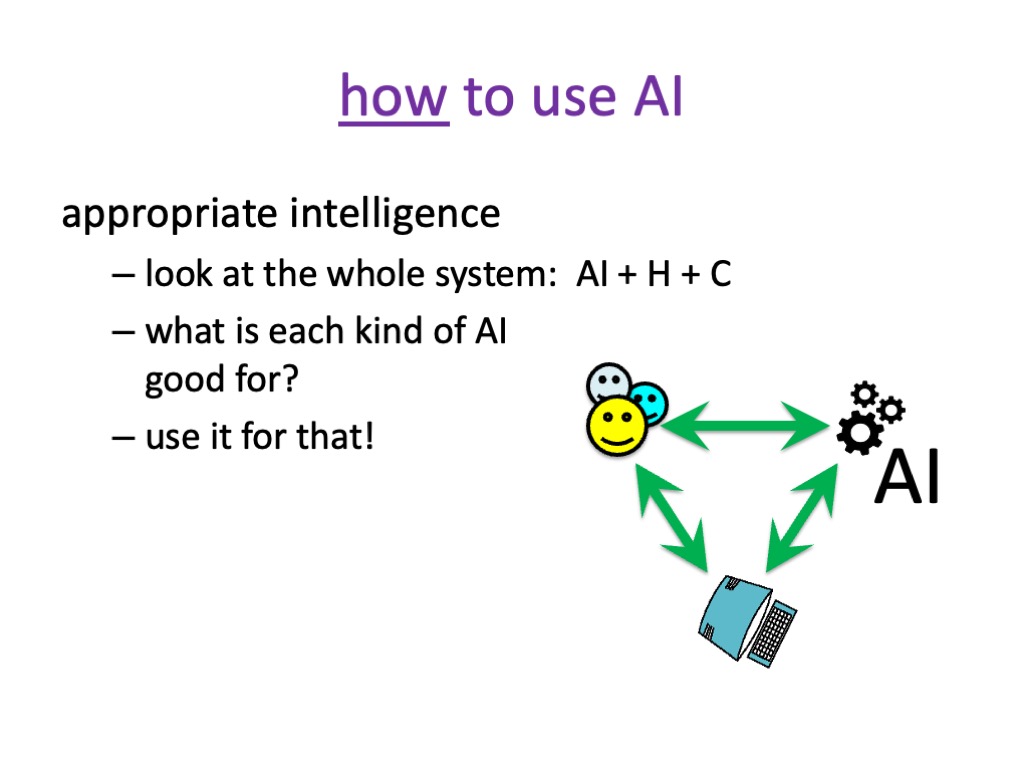
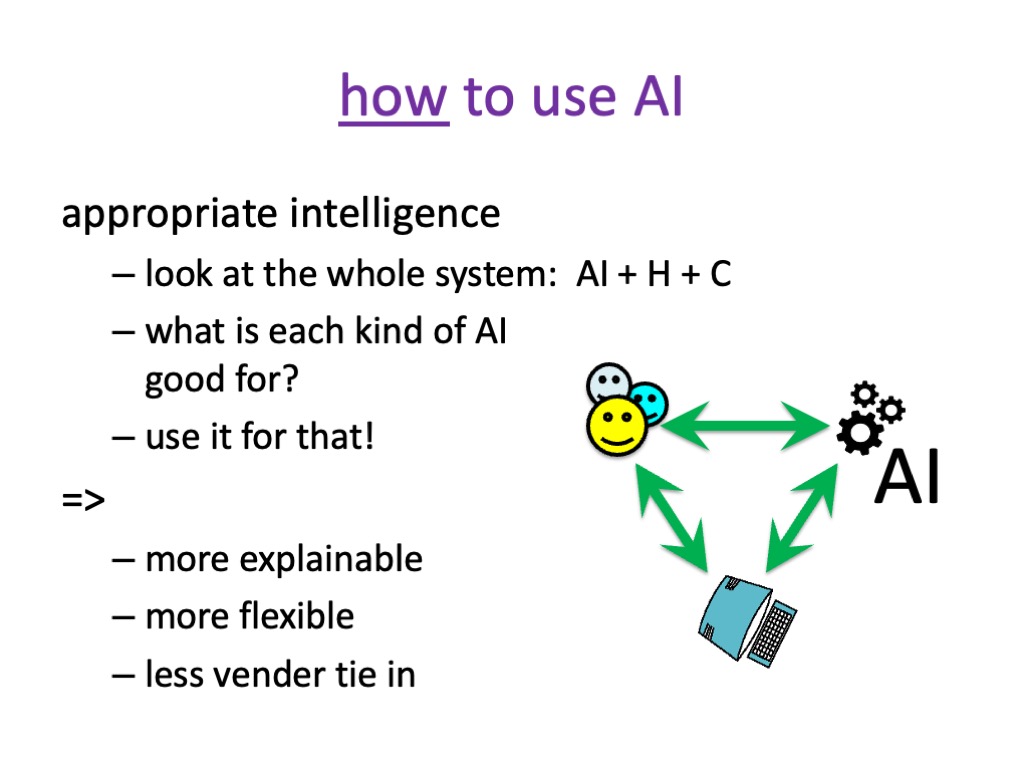
Finally, if you are using AI think carefully about the kind of AI you are going to use, and how to incorporate it into a system. For many years I’ve talked about appropriate intelligence, most often in relation to AI error and the need to design human–AI systems that together are robust and effective, not focusing in the AI accuracy alone [DB00,BD23]. However, the same lesson can be applied more broadly.

Often, we think about human interaction with AI, but it can be useful to think of a three-way interaction with human(s), AI and plain-old computing – that is hand coded algorithms or classic AI. Now look at each kind of AI that you are thinking of using and ask what is it good for?
What kind of things do I mean? One of the problems with traditional AI is that it was good with hard-nosed rules, but much more problematic with fuzzy things. There are various techniques such as Bayesian methods and fuzzy logic, but they require you to formalize the fuzziness into probabilities or similar functions. Amongst other things this limited various forms of natural language understanding and common-sense reasoning
Of course, large language models are really good at dealing with the nuances of language, but LLMs are less good when they try to be very precise, not least because they keep hallucinating!
So as you design for AI, ask what is it good for, how can I use it most appropriately?
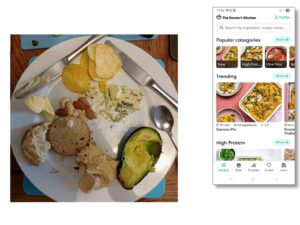
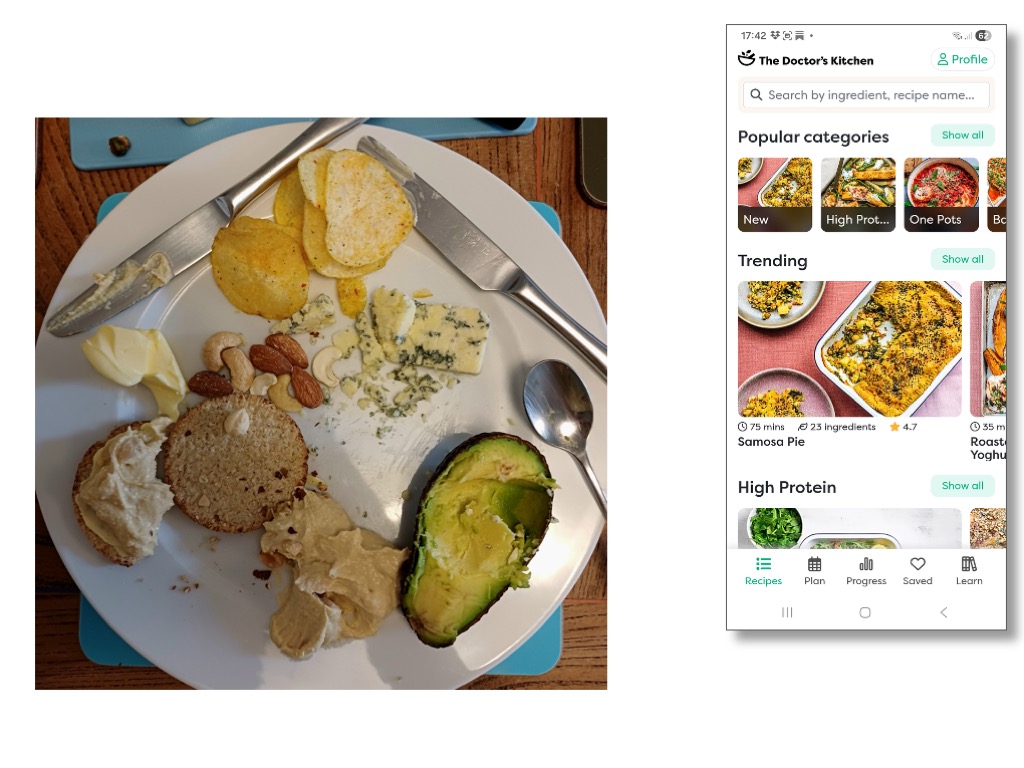
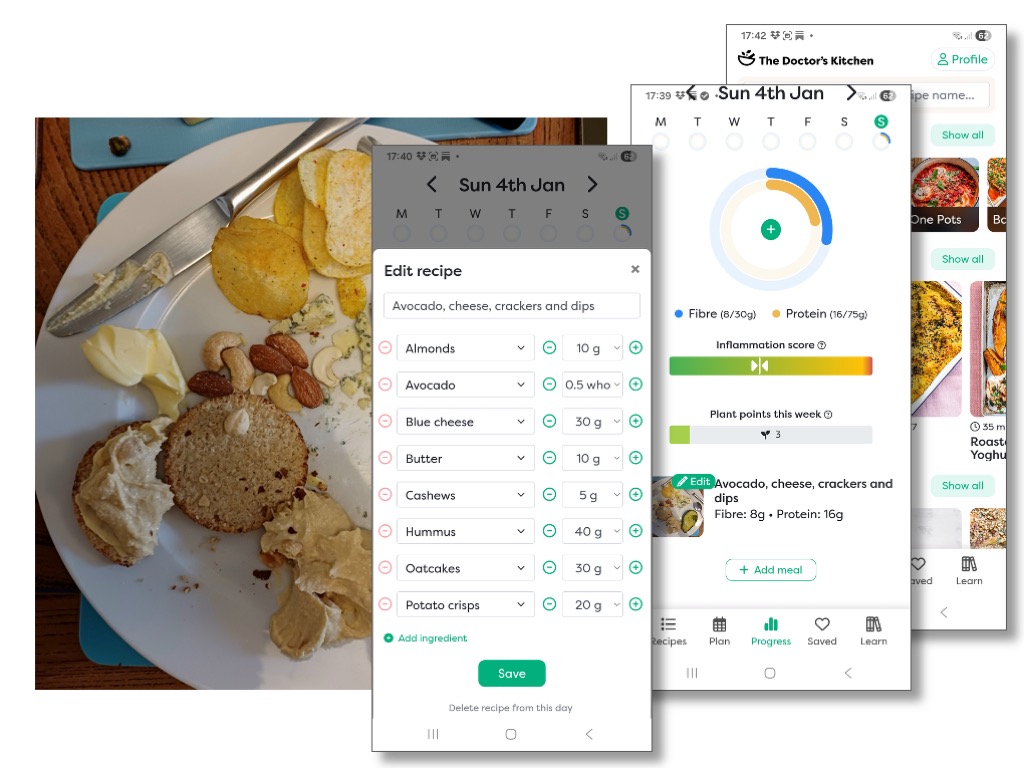
As an example of the appropriate use of AI, my wife uses an app from “The Doctor’s Kitchen” (https://www.thedoctorskitchen.com) to help keep track of the health value of food.
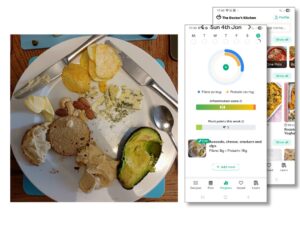
You take a photo of a plate of food before you eat it and the app creates a report on its nutritional value: how much fibre and protein it contains and its inflammation index. Is it likely to be good for you or bad?
You could imagine doing this by writing a complicated prompt to an LLM or train a deep learning algorithm with lots of plates of food and hand-curated reports. The app does not work like that.
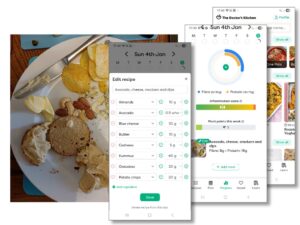
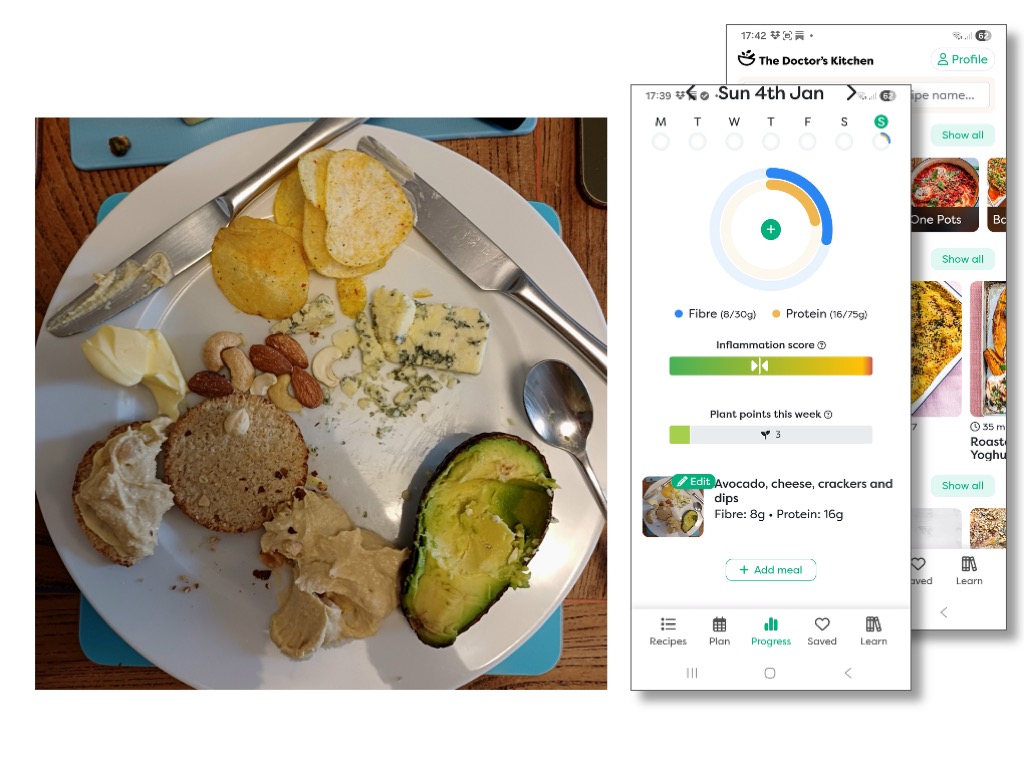
What it does is to use image processing AI to analyse the plate and work out what food is on it. Indeed, you can press an edit button to see what it thinks you’ve got on your plate, and, if it’s got it wrong, edit it. One assumes that a log of these edits helps to further train the image processing AI.
So the AI has been used for the fuzzy part of the task, working out that there are crisps on the plate but a no cake. It even manages to recognise hummus and estimate how much. It is amazingly good, but does sometimes get things wrong in terms of the volume or even what is there; however, when that happens you can easily see and correct it.
So this is using AI for the fuzzy bit.
This table of contents will then go into a standard algorithm that uses tables of nutritional values to look up how much protein is in, say, 10 grams of almonds, add this up for the plate and hence generate the final nutritional report.
AI and traditional computing together — combining the two using the best aspects of each.

Note that this is more explainable, you know, what’s going on.
It is also more flexible in terms of you can choose to enhance different components and change others.
There is also less vendor tie in. This is not removed entirely as you need a new AI to be retrained. However, it is easier to swap just the food recognition part than if the whole system were in a single AI.
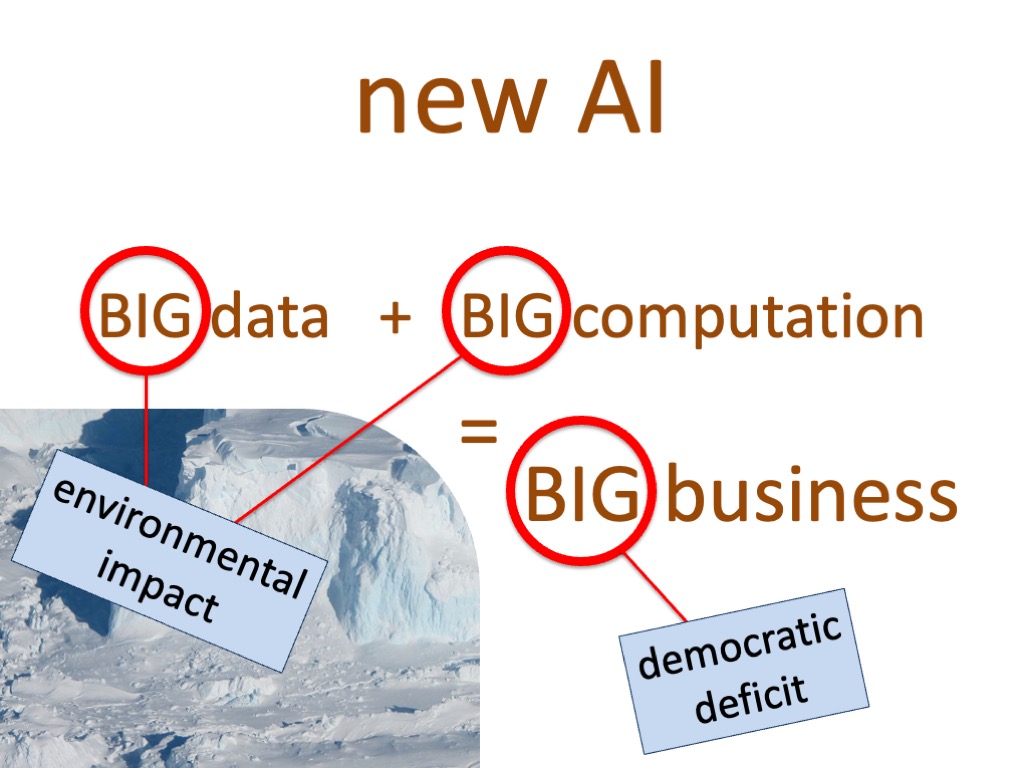
This is good from a business point of view, but it also means you are using less large-scale AI with its environmental, financial and democratically damaging effects, when you could be using simpler computation.
Coming next …
Part 8 – summary and recap
This final post will recap what we’ve learnt about the runaway nature of the AI industry, how it undermines free markets, and how we can make a difference. The core question is not what can AI do, but what should AI do?
Update
Since the talk in January I read about A.T.L.A.S. (Adaptive Test-time Learning and Autonomous Specialization) an AI coding system built by a business student Johnathon Tigges wanting to challenge the assumption that “only the biggest players can build meaningful things” [Ti26] . It is able to outcompete the big coding agents by being clever – rather than just throwing a problem into a big code-optimised LLMs and asking for a solution, it uses AI to generate lots of potential code fragments and tests them, using the best to further refine the AI model … all on a consume GPU. A lovely example of smart use of AI! For a more detailed description see Sebastian Buzdugan’s Medium story about it [Bu26].
References
[BD23] Alba Bisante, Alan Dix, Emanuele Panizzi, and Stefano Zeppieri (2023). To err is AI.In Proceedings of the 15th Biannual Conference of the Italian SIGCHI Chapter, pp.1–11. https://dsoi.org/10.1145/3605390.3605414
[Bu26] Sebastian Buzdugan (2026). Why a $500 GPU Can Beat Claude Sonnet on Coding Benchmarks. Medium. Mar 28, 2026. https://medium.com/@sebuzdugan/why-a-500-gpu-can-beat-claude-sonnet-on-coding-benchmarks-6c8169ffe4fe
[DS24] DeepSeek-AI (2024). DeepSeek-V3 Technical Report. arXiv preprint. 27 Dec 2024. https://arxiv.org/abs/2412.19437
[DS25] DeepSeek-AI (2025). DeepSeek-V3. GitHub Repository. Release v1.0.0. 27 Jun 2025. https://github.com/deepseek-ai/DeepSeek-V3
[Di22] Dickson, B. (2022). Can large language models be democratized? TechTalk,-May 16, 2022. https://bdtechtalks.com/2022/05/16/opt-175b-large-language-models/
[DB00] A. Dix, R. Beale and A. Wood (2000). Architectures to make Simple Visualisations using Simple Systems. Proceedings of Advanced Visual Interfaces – AVI2000, ACM Press, pp. 51-60. https://www.alandix.com/academic/papers/avi2000/
[Dx24] Alan Dix (2024). Patient Interaction – for well-being, productivity and sustainability. FUSION 2024, Kuala Lumpur, Malaysia, 28 Sept. 2024. https://www.alandix.com/academic/talks/FUSION2024/
[Dx25] Dix, A. (2025). Artificial Intelligence – Humans at the Heart of Algorithms, 2nd Edition, Chapman and Hall. https://alandix.com/aibook/
[bibitelm name=Dx26b] A. Dix. (2026). AI for Human–Computer Interaction. CRC Press, in press. https://alandix.com/ai4hci/
[Hi20] Hinton, G. (2020). Extrapolating the spectacular performance of GPT3 into the future suggests that the answer to life, the universe and everything is just 4.398 trillion parameters. Twitter (now X), Jun 10, 2020. https://x.com/geoffreyhinton/status/1270814602931187715
[HS22] Hu, E. J., Shen, Y., et al. (2022). LoRa: Low-rank adaptation of large language models. ICLR, 1(2), 3. https://arxiv.org/abs/2106.09685
[LF24] Liu, A., Feng, B., et al. (2024). Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. https://arxiv.org/abs/2412.19437
[Sa23] Sajid, H. (2023). Artificial Intelligence: Can You Build Large Language Models Like ChatGPT At Half Cost? Unite.ai, May 11, 2023. https://www.unite.ai/can-you-build-large-language-models-like-chatgpt-at-half-cost/
[Ti26] Johnathon Tigges (2026). A.T.L.A.S. – Adaptive Test-time Learning and Autonomous Specialization. GitHub. https://github.com/itigges22/ATLAS
[TH23] Touvron, H., Martin, L., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288. https://arxiv.org/abs/2307.09288
[WP23] Wang, P., Panda, R., et al. (2023). Learning to grow pretrained models for efficient transformer training. arXiv preprint. https://arxiv.org/abs/2303.00980
[We25b] Werner, J. (2025). Did DeepSeek Copy Off Of OpenAI? And What Is Distillation? Forbes, Jan 30, 2025. https://www.forbes.com/sites/johnwerner/2025/01/30/did-deepseek-copy-off-of-openai-and-what-is-distillation/
[ZD22] Zhang, S., Diab, M. and Zettlemoyer, L. (2022). Democratizing access to large-scale language models with OPT-175B. Meta Research Blog, May 3, 2022. https://ai.meta.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/