Naming things seems relatively unproblematic until you try to do it — ask any couple with a baby on the way. Naming files is no easier.
Earlier today Fiona @lovefibre was using the MAC OS Time Machine to retrieve an old version of a file (let’s call it “fisfile.doc”). She wanted to extract a part that she knew she had deleted in order to use in the current version. Of course the file you are retrieving has the same name as the current file, and the default is to overwrite the current version; that is a simple backup restore. However, you can ask Time Machine to retain both versions; at which point you end up with two files called, for example, “fisfile.doc” and “fisfile-original.doc”. In this case ‘original’ means ‘the most recent version’ and the unlabelled one is the old version you have just restored. This was not too confusing, but personally I would have been tempted to call the restored file something like “fisfile-2010-01-17-10-33.doc”, in particular because one wonders what will happen if you try to restore several copies of the same file to work on, for example, to work out when an error slipped into a document.
OK, just an single incident, but only a few minutes later I had another example of problematic naming.
I picked up mail and found I had an email notification from Lancaster University accounts department. The email included the BACS remittance advice for recent expenses as a PDF attachment. However, while they send emails like this every month or so, the attachment always has the same name “lu_remittance_advice_1234567.pdf” (where ‘1234567’ is my ‘supplier ID’ on the Lancaster finance system). As I saved it I remembered to change the name to “lu_remittance_advice_1234567_150210.pdf” to record the date as otherwise, if I did not rename, each remittance would have overwritten the previous one. Note this is a finance systems and these documents could be important for tax purposes (in order to prove the payment was for expenses) and there is only an electronic remittance. That is the use of the same name makes it likely that employees — and presumably also corporate suppliers — will accidentally delete critical records.
Those of you who have run any sort of small conference or workshop (or those who remember running a large one in the days before conference management systems) will have undoubtedly received numerous submission entitled “paper.doc” or “confname.doc” (where ‘confname’ is the name of your conference). And yes, shame on me, I have done the same myself. When I am editing the files myself or exchanging it with co-authors I will almost always call it something like “confname-v7.doc”. However, when I submit it I (try to remember to) rename it to “dix-confname.doc”. (And how many of you forget to add some sort of version number or date to the end of the filename when you exchange it with colleagues?)
Now while it is forgiveable for a person to make these kinds of mistake, it seems inexcusable when an automated system does it. For example, a number of publishers sites will call every paper you download “fulltext.pdf”.
So, if you are designing a system that generates file names, please, pretty please:
- make it readable — a person needs to look at the file name and make sense of it.
- make it unique — add a date or unique id, perhaps page range for a journal
So rather than the web site of the “International Journal of Good Naming” calling the download “fulltext.pdf”, instead call it “IJGN-2010v3p012-Dix-Naming.pdf”
Suitable naming can also help in searching. If you have several chapters calling them “chap01.doc”,”chap02.doc”, etc. (rather than “chap1.doc”,”chap2.doc”), so that in an alphabetic listing “chap09.doc” comes before “chap10.doc”. And Andy Wood taught me to always format dates in file names in reverse order “file-20100217” (rather than “file-17022010.doc”), so that alphabetic order is date order1. I must admit (sorry Andy!) that I more often use UK order (e.g. “lu_remittance_advice_1234567_150210.pdf” as the remittance dated 15th Feb 2010) as I find it easier to read.
When file names escaped the 8+3 formats and became any length, really descriptive names became possible and I’ve known people who could not manage folders/directories on teh machine, but instead created incredibly expressive naming schemes in “My Documents”, which effectively reinvent the hierarchical naming. With the ‘flat’ filing of tags in Flickr and Gmail, similar complex strategies emerged.
Real names of people and places also vary on context. Saying “Nigel” is sufficient to uniquely express who I’m talking about in Lancaster Computing, but not for any reader of this who doesn’t know the department.
Again, something to think about in automated systems.
After many years using my trusted paper to do list, I have tried again an electronic system ‘The Hit List‘. This allows to do ‘tasks’ to have sub-tasks and sub-sub-tasks, etc. So, if I am reviewing papers for EICS I can have a sub-task for each paper and for each paper sub-sub-tasks “read”, “write comments”, “upload comments”.
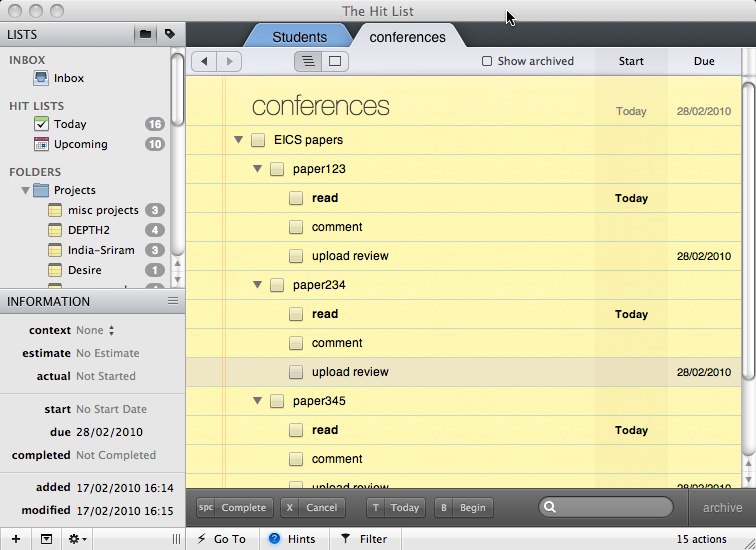
Unfortunately on the ‘Today’ panel, for things I have to do now, I simply get a list saying “read”, “read”, “read”. While the sub-sub-task name “read” is sufficient in the context of the task and sub-task it belonged to, it is very ambiguous on its own. Very quickly I learnt to explicitly include the full details on every sub-task!
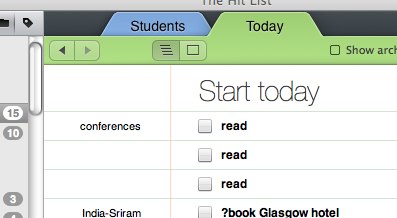
Getting this right is a far more complicated to automate. Helping Fiona on a system where there was a structure of items and sub-items, we allowed the user to explicitly give an alternate name to use ‘out of context’, but otherwise used a default rule. The rule simply checked if the sub-item name started off similarly to the item name (for example, if the user had already entered a descriptive name such as “EICS paper 123”) and if so used that, but otherwise prefixed the item name to make it unique. This of course only works if the individual names are not too long and there is lots of screen space; hence allowing the user the option to explicitly enter a display name if the default did not work.
Naming is tough and there will always be ambiguity and confusion. However, with a little thought when we design systems, we can make it a lot bettter.
- You might wonder why not rely on the file system’s date for the file. However, for various reasons file dates often become confusing: date of creation, update, or download, especially for folders. So while the file system date is “date it was changed on this machine”, the file name date may be “date it pertains to”, for example the date of the BACS payment in the remittance advice, not the date of the email. [back]
Scott Bourne discusses similar issues in relation to digital cameras in “An Open Letter to Digital Camera Manufacturers Regarding Camera File Naming” http://photofocus.com/2010/09/13/an-open-letter-to-digital-camera-manufacturers-regarding-camera-file-naming/