Do free markets generate the best AI? Not always, and this not only hits the bottom line, but comes with costs for personal privacy and the environment. The combination of network effects and winner-takes-all advertising expenditure means that the resulting algorithms may be worst for everyone.
A few weeks ago I was talking with Maria Ferrario (Queens University Belfast) and Emily Winter (Lancaster University) regarding privacy and personal data. Social media sites and other platforms are using ever more sophisticated algorithms to micro-target advertising. However, Maria had recently read a paper suggesting that this had gone beyond the point of diminishing returns: far simpler – and less personally intrusive – algorithms achieve nearly as good performance as the most complex AI. As well as having an impact on privacy, this will also be contributing to the ever growing carbon impact of digital technology.
At first this seemed counter-intuitive. While privacy and the environment may not be central concerns, surely companies will not invest more resources in algorithms than is necessary to maximise profit?
However, I then remembered the peacock tail.

Jatin Sindhu, CC BY-SA 4.0, via Wikimedia Commons
The simple story of Darwinian selection suggests that this should never happen. The peacocks that have smaller and less noticeable tails should have a better chance of survival, passing their genes to the next generation, leading over time to more manageable and less bright plumage. In computational terms, evolution acts as a slow, but effective optimisation algorithm, moving a population ever closer to a perfect fit with its environment.
However, this simple story has twists, notably runaway sexual selection. The story goes like this. Many male birds develop brighter plumage during mating season so that they are more noticeable to females. This carries a risk of being caught by a predator, but there is a balance between the risks of being eaten and the benefits of copulation. Stronger, faster males are better able to fight off or escape a predator, and hence can afford to have slightly more gaudy plumage. Thus, for the canny female, brighter plumage is a proxy indicator of a more fit potential mate. As this becomes more firmly embedded into the female selection process, there is an arms race between males – those with less bright plumage will lose out to those with brighter plumage and hence die out. The baseline constantly increases.
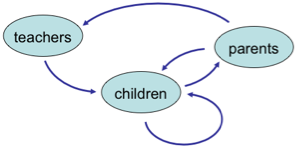
Similar things can happen in free markets, which are often likened to Darwinian competition.
Large platforms such as Facebook or Google make the majority of their income through advertising. Companies with large advertising accounts are constantly seeking the best return on their marketing budgets and will place ads on the platform that offers the greatest impact (often measured by click-through) for the least expenditure. Rather like mating, this is a winner-takes-all choice. If Facebook’s advertising is 1% more effective than Google’s a canny advertiser will place all their adverts with Facebook and vice versa. Just like the peacock there is an existential need to outdo each other and thus almost no limit on the resources that should be squandered to gain that elusive edge.
In practice there are modifying factors; the differing demographics of platforms mean that one or other may be better for particular companies and also, perhaps most critically, the platform can adjust its pricing to reflect the effectiveness so that click-through-per-dollar is similar.
The latter is the way the hidden hand of the free market is supposed to operate to deliver ‘optimal’ productivity. If spending 10% more on a process can improve productivity by 11% you will make the investment. However, the theory of free markets (to the extent that it ever works) relies on an ‘ideal’ situation with perfect knowledge, free competition and low barriers to entry. Many countries operate collusion and monopoly laws in pursuit of this ‘ideal’ market.
Digital technology does not work like this.
For many application areas, network effects mean that emergent monopolies are almost inevitable. This was first noticed for software such as Microsoft Office – if all my collaborators use Office then it is easier to share documents with them if I use Office also. However, it becomes even more extreme with social networks – although there are different niches, it is hard to have multiple Facebooks, or at least to create a new one – the value of the platform is because all one’s friends use it.
For the large platforms this means that a substantial part of their expenditure is based on maintaining and growing this service (social network, search engine, etc.). While the income is obtained from advertising, only a small proportion of the costs are developing and running the algorithms that micro-target adverts.
Let’s assume that the ratio of platform to advertising algorithm costs is 10:1 (I suspect it is a lot greater). Now imagine platform P develops an algorithm that uses 50% more computational power, but improves advertising targeting effectiveness by 10%; at first this sounds a poor balance, but remember that 10:1 ratio.
The platform can charge 10% more whilst being competitive. However, the 50% increase in advertising algorithm costs is just 5% of the overall company running costs, as 90% are effectively fixed costs of maintaining the platform. A 5% increase in costs has led to a 10% increase in corporate income. Indeed one could afford to double the computational costs for that 10% increase in performance and still maintain profitability.
Of course, the competing platforms will also work hard to develop ever more sophisticated (and typically privacy reducing and carbon producing) algorithms, so that those gains will be rapidly eroded, leading to the next step.
In the end there are diminishing returns for effective advertising: there are only so many eye-hours and dollars in users’ pockets. The 10% increase in advertising effectiveness is not a real productivity gain, but is about gaining a temporary increase in users’ attention, given the current state of competing platforms’ advertising effectiveness.
Looking at the system as a whole, more and more energy and expenditure are spent on algorithms that are ever more invasive of personal autonomy, and in the end yield no return for anyone.
And it’s not even a beautiful extravagance.




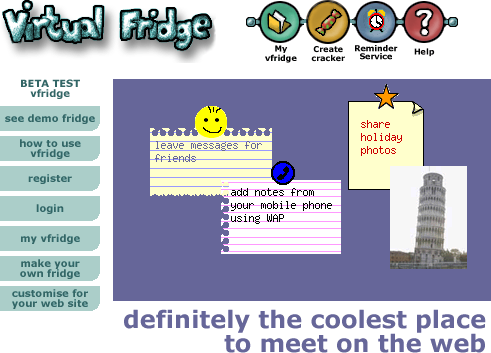
 The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door.
The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door. Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “
Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “




{kind=link}