[another techie post – a problem I had and can see that other people have had too]
It is common in various web frameworks to pass pretty much everything through a central script using Apache .htaccess file and mod_rewrite. For example enabling permalinks in a WordPress blog generates an .htaccess file like this:
RewriteEngine On
RewriteBase /blog/
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /blog/index.php [L]
I use similar patterns for various sites such as vfridge (see recent post “Phoenix rises“) and Snip!t. For Snip!t however I was using not a local .htaccess file, but an AliasMatch in httpd.conf, which meant I needed to ask Fiona every time I needed to do a change (as I can never remember the root passwords!). It seemed easier (even if slightly less efficient) to move this to a local .htaccess file:
RewriteEngine On RewriteBase / RewriteRule ^(.*)$ code/top.php/$1 [L]
The intention is to map “/an/example?args” into “/code/top.php/an/example?args”.
Unfortunately this resulted in a “500 internal server error” page and in the Apache error log messages saying there were too many internal redirects. This seems to be a common problem reported in forums (see here, here and here). The reason for this is that .htaccess files are encountered very late in Apache’s processing and so anything rewritten by the rules gets thrown back into Apache’s processing almost as if they were a fresh request. While the “[L]”(last) flags says “don’t execute any more rules”, this means “no more rules on this pass”, but when Apache gets back to the .htaccess in the fresh round the rule gets encountered again and again leading to an infinite loop “/code/top/php/code/top.php/…/code/top.php/an/example?args”.
Happily, mod_rewrite thought of this and there is an additional “[NS]” (nosubreq) flag that says “only use this rule on the first pass”. The mod_rewrite documentation for RewriteRule in Apache 1.3, 2.0 and 2.3 says:
Use the following rule for your decision: whenever you prefix some URLs with CGI-scripts to force them to be processed by the CGI-script, the chance is high that you will run into problems (or even overhead) on sub-requests. In these cases, use this flag.
I duly added the flag:
RewriteRule ^(.*)$ code/top.php/$1 [L,NS]
This should work, but doesn’t. I’m not sure why except that the Apache 2.2 documentation for NS|nosubreq reads:
Use of the [NS] flag prevents the rule from being used on subrequests. For example, a page which is included using an SSI (Server Side Include) is a subrequest, and you may want to avoid rewrites happening on those subrequests.
Images, javascript files, or css files, loaded as part of an HTML page, are not subrequests – the browser requests them as separate HTTP requests.
This is identical to the documentation for 1.3, 2.0 and 2.3 except that quote about “URLs with CGI-scripts” is singularly missing. I can’t find anything that says so, but my guess is that there was some bug (feature?) introduced 2.2 that is being fixed in 2.3.
WordPress is immune from the infinite loop as the directive “RewriteCond %{REQUEST_FILENAME} !-f” says “if the file exists use that without rewriting”. As “index.php” is a file, the rule does not rewrite a second time. However, the layout of my files meant that I sometimes have an actual file in the pseudo location (e.g. /an/example really exists). I could have reorganised the complete directory structure … but then I would have been still fixing all the broken links now!
Instead I simply added an explicit “please don’t rewrite my top.php script” condition:
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_URI} !^/code/top.php/.*
RewriteRule ^(.*)$ code/top.php/$1 [L,NS]
I suspect that this will be unnecessary when Apache upgrades to 2.3, but for now … it works 🙂
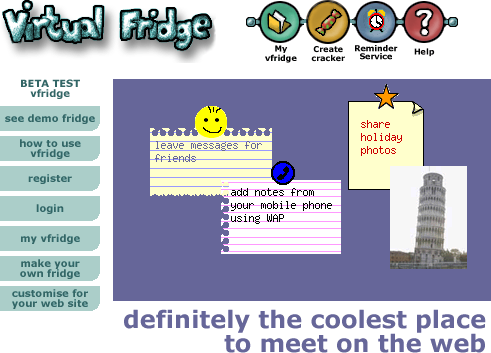
 The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door.
The core idea of vfridge is placing small notes, photos and ‘magnets’ in a shareable web area that can be moved around and arranged like you might with notes held by magnets to a fridge door. Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “
Just over a year ago I thought it would be good to write a retrospective about vfridge in the light of the social networking revolution. We did a poster “




