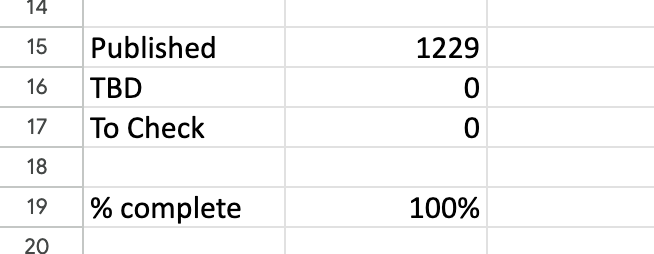
The glossary is complete –1229 entries in all. All ready for the publication of the AI book in June. The AI glossary is a resource in its own right and interlinks with the book as a hybrid digital/physical media. Read on to find more about the glossary and how it was made.
When I wrote my earlier book Statistics for HCI: Making Sense of Quantitative Data back in 2000, I created an online statistics glossary for that with 357 entries … maybe the result of too much time during lockdown? In the paper version each term was formatted with a subtle highlight colour and in the PDF version they are all live links to the glossary.
So, when I started this second edition of Artificial Intelligence: Humans at the Heart of Algorithms I thought I should do the same, but the scale is somewhat different with more than three times as many entries. The book is due to be published in June and you can preorder at the publisher’s site, but the glossary is live now for you to use.
What’s in the AI Glossary
The current AI Book glossary front page is a simple alphabetical list

Some entries are quite short: a couple of sentences and references to the chapters and pages in the book where it is used. However many include examples, links to external resources and images. Some of the images are figures from the book, others created specially for the glossary. In addition keywords in the entry link to other entries ‘wiki-style.
In addition the chapter pages on the AI Book web site each include references to all of the glossary items mentioned as well as a detailed table of contents and links to code examples.




Note that while all the entries are complete, there are currently many typos and before the book is published in June I need to do another pass to fix these! The page numbers will also update once the final production-ready proof is complete, but the chapter links are correct.
How it is made
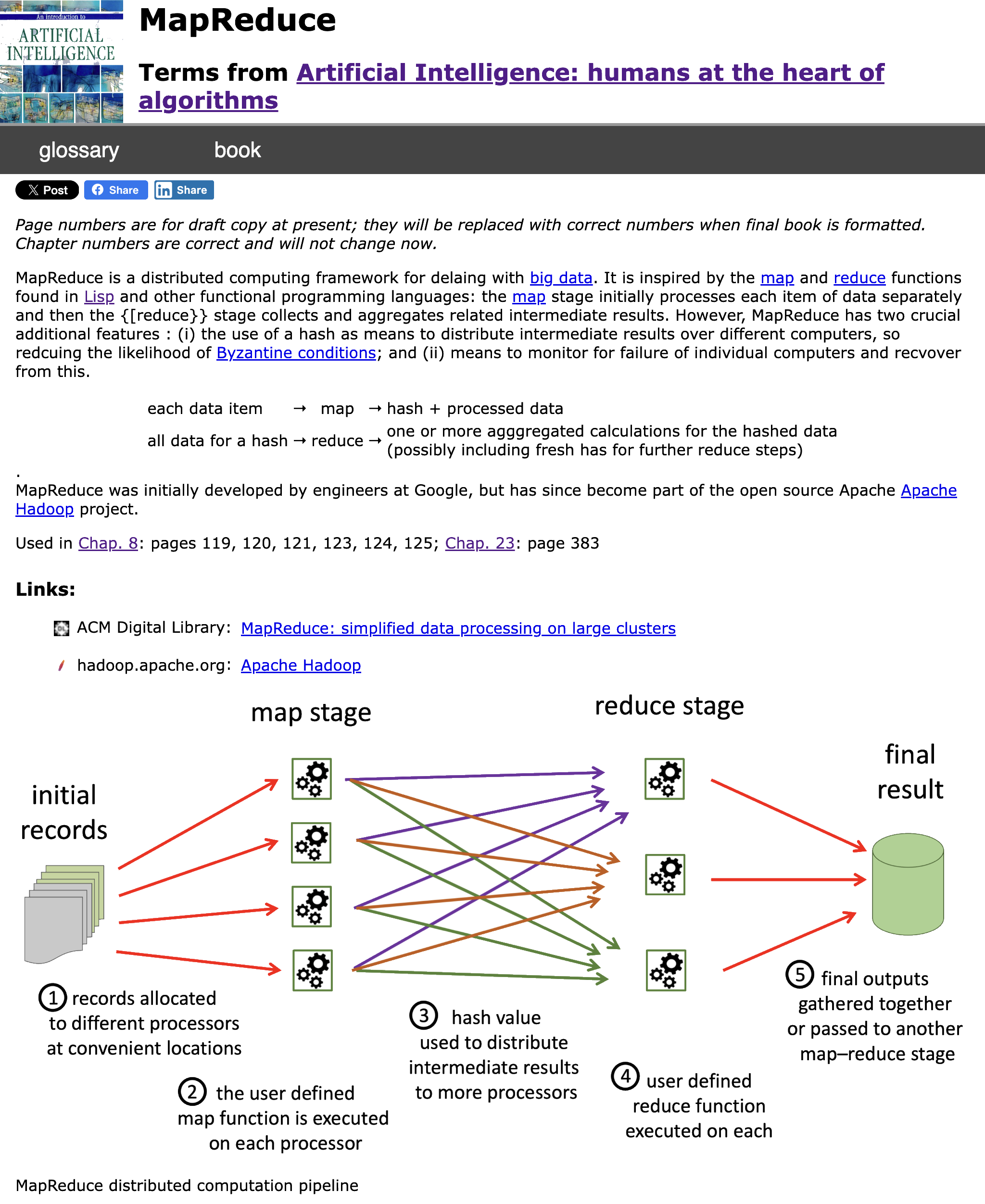
I had already created a workflow for the HCI Stats glossary, and so was able to reuse and update that. Both books are produced using LaTeX and in the text critical terms are marked using a number of macros, for example:
The same information is then shown (ii) with the \term{microdata} added that says that the paragraph is talking about a book, that the author is Alan Dix and that he was born in Cardiff. Finally, the extracted information is shown as \term{JSON} data in (iii).
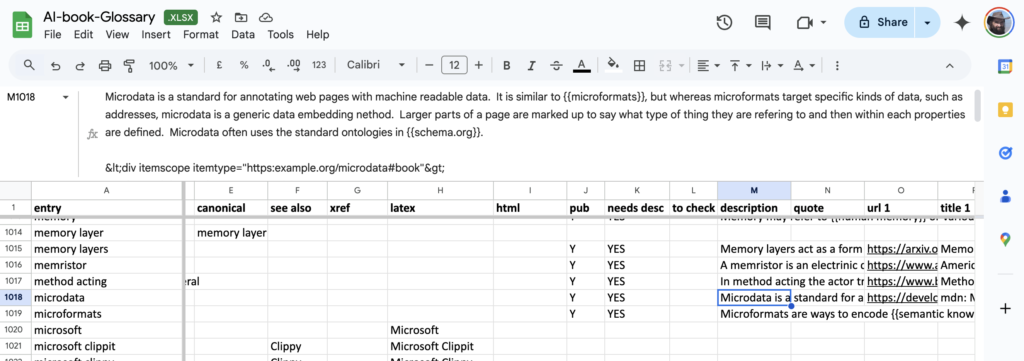
The \term macro (and related ones such as \termdef) expand to: (a) add an entry to the index file for the term; (b) format the text with slight highlight; and (c) add a hyperlink to the glossary. The index items can be gathered and were used to initially populate the first column of a Google Spreadsheet:
Over many months this was gradually updated. In the final spreadsheet today (I will probably add to it over time) there are 1846 raw entries with 1229 definitions. This includes a few items that are not explicitly mentioned in the book, but were useful for defining other entries, or new things that are emerging in the field.
On the left are two columns ‘canonical’ and ‘see also’ linking to other entries; these are used to structure the index. Both lead to immediate redirects in the web glossary and page references in the text to the raw entry are amalgamated into the referenced entry. However, they have slightly different behaviour in the web and book index. If an entry has a canonical form it is usually a very close variant spelling (e.g. ise/ize endings , hyphens or plurals) and does not appear in the index at all as the referenced item will be recognisable. The ‘see also’ links create “See …” cross references in the book and web index.
The ‘latex’ and ‘html’ show how the term should be formatted with correct capitalisation, special characters, etc.
The spreadsheet entries above are formatted on the web as follows (the book version similar):

On the right of the spreadsheet are the definition and urls of links to images or related web resources. The definitions can include cross references to other entries using a wiki-style markup, for example the reference to {
Just before these content entries are a few columns that kept track of which entries needed attention so that I could easily scan for entries with a highlighted ‘TBD’ or ‘CHK’.
The definition of microdata selected in the above spreadsheet fragment is shown as follows:

Gamification
Working one’s way through 1846 raw entries, writing 1229 definitions comprising more than 90,000 words can be tedious! Happily I quite accidentally gamified the experience.
Part way through doing the HCI statistics glossary, I created a summary worksheet that kept track of the number of entries that needed to be processed and a %complete indicator. I found it useful for that, but invaluable for the AI book glossary as it was so daunting.
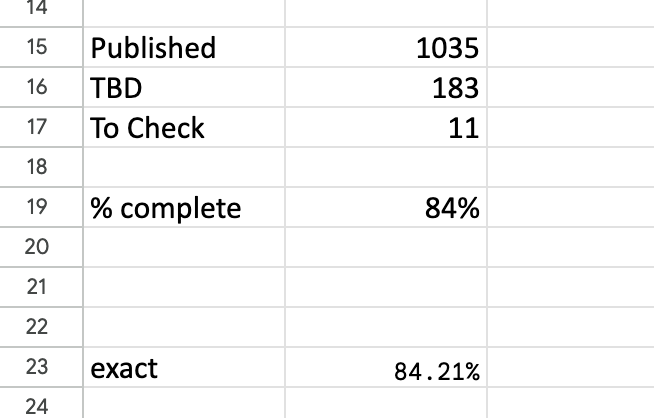 The headline summary has raw counts and a rounded %complete. Seeing this notch up one percent was a major buzz corresponding to about a dozen entries. Below that is a more precise percentage, which I normally kept below the bottom of the window so I had to scroll to see it. I could take a peek and think “nearly at a the next percent mark, I’ll just do a few more”.
The headline summary has raw counts and a rounded %complete. Seeing this notch up one percent was a major buzz corresponding to about a dozen entries. Below that is a more precise percentage, which I normally kept below the bottom of the window so I had to scroll to see it. I could take a peek and think “nearly at a the next percent mark, I’ll just do a few more”.