I use various Adobe products, especially Dreamweaver and want to get the newest version of Creative Suite. This is not cheap, even at academic prices, so you might think Adobe would want to make it easy to buy their products, but life on the web is never that simple!
As you can guess a number of problems ensued, some easily fixable, some demonstrating why effective interaction design is not trivial and apparently good choices can lead to disaster.
There is a common thread. Most usability is focused on the time we are actively using a system – yes obvious – however, most of the problems I faced were about the extended use of the system, the way individual periods of use link together. Issues of long-term interaction have been an interest of mine for many years and have recently come to the fore in work with Haliyana, Corina and others on social networking sites and the nature of ‘extended episodic experience’. However, there is relatively little in the research literature or practical guidelines on such extended interaction, so problems are perhaps to be expected.
First the good bit – the Creative ‘Suite’ includes various individual Adobe products and there are several variants Design/Web, Standard/Premium, however there is a great page comparing them all … I was able to choose which version I needed, go to the academic purchase page, and then send a link to the research administrator at Lancaster so she could order it. So far so good, 10 out of 10 for Adobe …
To purchase as an academic you quite reasonably have to send proof of academic status. In the past a letter from the dept. on headed paper was deemed sufficient, but now they ask for a photo ID. I am still not sure why this is need, I wasn’t going in in person, so how could a photo ID help? My only photo ID is my passport and with security issues and identity theft constantly in the news, I was reluctant to send a fax of that (do US homeland security know that Adobe, a US company, are demanding this and thus weakening border controls?).
After double checking all the information and FAQs in the site, I decided to contact customer support …
Phase 1 customer support
The site had a “contact us” page and under “Customer service online”, there is an option “Open new case/incident”:
… not exactly everyday language, but I guessed this meant “send us a message” and proceeded. After a few more steps, I got to the enquiry web form and asked whether there was an alternative, or if I sent fax of the passport whether I could blot out the passport number and submitted the form.
Problem 1: The confirmation page did not say what would happen next. In fact they send an email when the query is answered, but as I did not know that, so I had to periodically check the site during the rest of the day and the following morning.
Lesson 1: Interactions often include ‘breaks’, when things happen over a longer period. When there is a ‘beak’ in interaction, explain the process.
Lesson 1 can be seen as a long-term equivalent of standard usability principles to offer feedback, or in Nielsen’s Heuristics “Visibility of system status”, but this design advice is normally taken to refer to immediate interactions and what has already happened, not about what will happen in the longer term. Even principles of ‘predictability’ are normally phrased in knowing what I can do to the system and how it will respond to my actions, but not formulated clearly for when the system takes autonomous action.
In terms of status-event analysis, they quite correctly gave me an generated an interaction event for me (the mail arriving) to notify me of the change of status of my ‘case’. It was just that the hadn’t explained that is what they were going to do.
Anyway the next day the email arrived …
Problem 2: The mail’s subject was “Your customer support case has been closed”. Within the mail there was no indication that the enquiry had actually been answered (it had), nor a link to the the location on the site to view the ‘case’ (I had to login and navigate to it by hand), just a general link to the customer ‘support’ portal and a survey to convey my satisfaction with the service (!).
Lesson 2.1: The email is part of the interaction. So apply ‘normal’ interaction design principles, such as Nielsen’s “speak the users’ language” – in this case “case has been closed” does not convey that it has been dealt with, but sounds more like it has been ignored.
Lesson 2.2: Give clear information in the email – don’t demand a visit to the site. The eventual response to my ‘case’ on the web site was entirely textual, so why not simply include it in the email? In fact, the email included a PDF attachment, that started off identical to the email body and so I assumed was a copy of the same information … but turned out to have the response in it. So they had given the information, just not told me they had!
Lesson 2.3: Except where there is a security risk – give direct links not generic ones. The email could easily have included a direct link to my ‘case’ on the web site, instead I had to navigate to it. Furthermore the link could have included an authentication key so that I wouldn’t have to look up my Adobe user name and password (I of course needed to create a web site login in order to do a query).
In fact there are sometimes genuine security reasons for sometimes NOT doing this. One is if you are uncertain of the security of the email system or recipient address, but in this case Adobe are happy to send login details by email, so clearly trust the recipient. Another is to avoid establishing user behaviours that are vulnerable to ‘fishing’ attacks. In fact I get annoyed when banks send me emails with direct links to their site (some still do!), rather than asking you to visit the site and navigate, if users get used to navigating using email links then entering login credentials this is an easy way for malicious emails to harvest personal details. Again in this case Adobe had other URLs in the email, so this was not their reason. However, if they had been …
Lesson 2.4: If you are worried about security of the channel, give clear instructions on how to navigate the site instead of a link.
Lesson 2.5: If you wish to avoid behaviour liable to fishing, do not include direct links to your site in emails. However, do give the user a fast-access reference number to cut-and-paste into the site once they have navigated to the site manually.
Lesson 2.6: As a more general lesson understand security and privacy risks. Often systems demand security procedures that are unnecessary (forcing me to re-authenticate), but omit the ones that are really important (making me send a fax of my passport).
Eventually I re-navigate the Adobe site and find the details of my ‘case’ (which was also in the PDF in the email if I had realised).
Problem 3: The ‘answer’ to my query was a few sections cut-and-pasted from the academic purchase FAQ … which I had already read before making the enquiry. In particular it did not answer my specific question even to say “no”.
Lesson 3.1: The FAQ sections could easily have been identified automatically the day before. If there is going to be delay in human response, where possible offer an immediate automatic response. If this includes a means to say whether this has answered the query, then human response may not be needed (saving money!) or at least take into account what the user already knows.
Lesson 3.2: For human interactions – read what the user has said. Seems like basic customer service … This is a training issue for human operators, but reminds us that:
Lesson 3.3: People are part of the system too.
Lesson 3.4: Do not ‘close down’ an interaction until the user says they are satisfied. Again basic customer service, but whereas 3.2 is a human training issue, this is about the design of the information system: the user needs some way to say whether or not the answer is sufficient. In this case, the only way to re-open the case is to ring a full-cost telephone support line.
Phase 2 customer feedback survey
As I mentioned, the email also had a link to a web survey:
In an effort to constantly improve service to our customers, we would be very
interested in hearing from you regarding our performance. Would you be so
kind to take a few minutes to complete our survey? If so, please click here:
Yes I did want to give Adobe feedback on their customer service! So I clicked the link and was taken to a personalised web survey. I say ‘personalised’ in that the link included a reference to the customer support case number, but thereafter the form was completely standard and had numerous multi-choice questions completely irrelevant to an academic order. I lost count of the pages, each with dozens of tick boxes, I think around 10, but may have been more … and certainly felt like more. Only on the last page was there a free-text area where I could say what was the real problem. I only persevered because I was already so frustrated … and was more so by the time I got to the end of the survey.
Problem 4: Lengthy and largely irrelevant feedback form.
Lesson 4.1: Adapt surveys to the user, don’t expect the user to adapt to the survey! The ‘case’ originated in the education part of the web site, the selections I made when creating the ‘case’ narrowed this down further to a purchasing enquiry; it would be so easy to remove many of the questions based on this. Actually if the form had even said in text “if your support query was about X, please answer …” I could then have known what to skip!
Lesson 4.2: Make surveys easy for the user to complete: limit length and offer fast paths. If a student came to me with a questionnaire or survey that long I would tell them to think again. If you want someone to complete a form it has to be easy to do so – by all means have longer sections so long as the user can skip them and get to the core issues. I guess cynically making customer surveys difficult may reduce the number of recorded complaints 😉
Phase 3 the order arrives
Back to the story: the customer support answer told me no more than I knew before, but I decided to risk faxing the passport (with the passport number obscured) as my photo ID, and (after some additional phone calls by the research administrator at Lancaster!), the order was placed and accepted.
When I got back home on Friday, the box from Adobe was waiting 🙂
I opened the plastic shrink-wrap … and only then noticed that on the box it said “Windows” 🙁
I had sent the research adminstrator a link to the product, so had I accidentally sent a link to the Windows version rather than the Mac one? Or was there a point later in the purchasing dialogue where she had had to say which OS was required and not realised I used a Mac?
I went back to my mail to her and clicked the link:
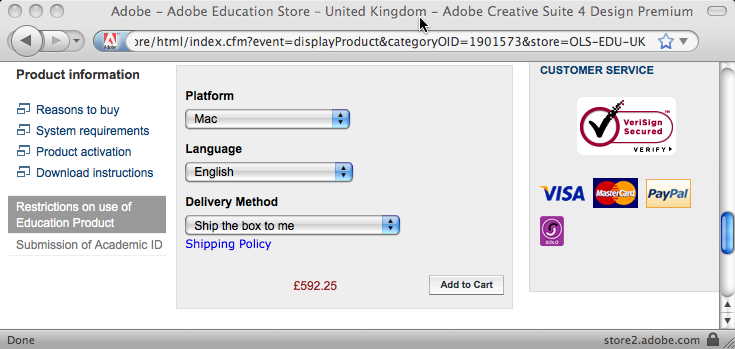
The “Platform” field clearly says “Mac”, but it is actually a selection field:
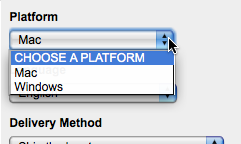
It seemed odd that the default value was “Mac” … why not “CHOOSE A PLATFORM”, I wondered if it was remembering a previous selection I had made, so tried the URL in Safari … and it looked the same.
… then I realised!
The web form was being ‘intelligent’ and had detected that I was on a Mac and so set the field to “Mac”. I then sent the URL to the research administrator and on her Windows machine it will have defaulted to “Windows”. She quite sensibly assumed that the URL I sent her was for the product I wanted and ordered it.
In fact offering smart defaults is good web design advice, so what went wrong here?
Problem 5: What I saw and what the research administrator saw were different, leading to ordering the wrong product.
Lesson 5.1: Defaults are also dangerous. If there are defaults the user will probably agree to them without realising there was a choice. We are talking about a £600 product here, that is a lot of room for error. For very costly decisions, this may mean not having defaults and forcing the user to choose, but maybe making it easy to choose the default (e.g. putting default at top of a menu).
Lesson 5.2: If we decide the advantages of the default outweigh the disadvantages then we need to make defaulted information obvious (e.g. highlight, special colour) and possibly warn the user (one of those annoying “did you really mean” dialogue boxes! … but hey for £600 may be worth it). In the case of an e-commerce system we could even track this through the system and keep inferred information highlighted (unless explicitly confirmed) all the way through to the final order form. Leading to …
Lesson 5.3: Retain provenance. Automatic defaults are relatively simple ‘intelligence’, but as more forms of intelligent interaction emerge it will become more and more important to retain the provenance of information – what came explicitly from the user, what was inferred and how. Neither current database systems nor emerging semantic web infrastructure make this easy to achieve internally, so new information architectures are essential. Even if we retain this information, we do not yet fully understand the interaction and presentation mechanisms needed for effective user interaction with inferred information, as this story demonstrates!
Lesson 5.4: The URL is part of the interaction. I mailed a URL believing it would be interpreted the same everywhere, but in fact its meaning was relative to context. This can be problematic even for ‘obviously’ personalised pages like a Facebook home page which always comes out as your own home page, so looks different. However, it is essential when someone might want to bookmark, or mail the link.
This last point has always been one of the problems with framed sites and is getting more problematic with AJAX. Ideally when dynamic content changes on the web page the URL should change to reflect it. I had mistakenly thought this impossible without forcing a page reload, until I noticed that the multimap site does this.

The map location at the end of the URL changes as you move around the map. It took me still longer to work out that this is accomplished because changing the part of the URL after the hash (sometimes called the ‘fragment’ and accessed in Javascript via location.hash) does not force a page reload.
If this is too complicated then it is relatively easy to use Javascript to update some sort of “use this link” or “link to this page” both for frame-based sites or those using web form elements or even AJAX. In fact, multimap does this as well!
Lesson 5.5: When you have dynamic page content update the URL or provide a “link to this page” URL.
Extended interaction
Some of these problems should have been picked up by normal usability testing. It is reasonable to expect problems with individual web sites or low-budget sites of small companies or charities. However, large corporate sites like Adobe or central government have large budgets and a major impact on many people. It amazes and appals me how often even the simplest things are done so sloppily.
However, as mentioned at the beginning, many of the problems and lessons above are about extended interaction: multiple visits to the site, emails between the site and the customer, and emails between individuals. None of my interactions with the site were unusual or complex, and yet there seems to be a systematic lack of comprehension of this longer-term picture of usability.
As noted also at the beginning, this is partly because there is scant design advice on such interactions. Norman has discussed “activity centred design“, but he still focuses on the multiple interactions within a single session with an application. Activity theory takes a broader and longer-term view, but tends to focus more on the social and organisational context whereas the story here shows there is also a need for detailed interaction design advice. The work I mentioned with Haliyana and Corina has been about the experiential aspects of extended interaction, but the problems on the Adobe were largely at a functional level (I never got so far as appreciating an ‘experience’ except a bad one!). So there is clearly much more work to be done here … any budding PhD students looking for a topic?
However, as with many things, once one thinks about the issue, some strategies for effective design start to become obvious.
So as a last lesson:
Overall Lesson: Think about extended interaction.
[ See HCI Book site for other ‘War Stories‘ of problems with popular products. ]