Nad did a brilliant guest lecture for our undergraduate HCI class at Lancaster on Monday. His slides and blog about the lecture are at Virtual Chaos. He touched on issues of democracy vs. authority of information, dynamic content vs. accessibility and of course increasing issues of privacy on social networking sites. He also had awesome slides to using loads of Flickr photos under creative commons … community content in action not just words! Of course also touched on Web3.0 and future convergence between emergent community phenomena and structured Semantic Web technologies.
Category Archives: web development
digging ourselves back from the Semantic Web mire
Discussions on the Talis Platform Advisory Group prompted me to look at some of the APIs of new Semantic-Web-like services such as Freebase1.
Freebase is interesting as its underlying representation is graph/relationship based like RDF, but its Metaweb Query Language (MQL) uses JSON which is a more programming-like whole and parts representation with arrays and slots. Facebook’s new Data Store API also has objects and associations, but does not use RDF or other obvious web technologies.
So the question is – if the closest things to Semantic Web apps on the internet don’t use SemWeb techology like RDF, SPARQL etc. … are these SemWeb techologies fit for purpose or indeed useful at all?
I think the answer is that (i) partly they are not fit for purpose – caught in a backwater by their history, but (ii) that is like all things and they are what we have got, and (iii) we can use some of the tools of computing to make them work …
- listen to Talis’ pod cast interview with Jamie Taylor Freebase’s ‘Minister of Information’ (sic).[back]
Local images – mixing memories and maps
I just came across a really nice part of the BBC web site for Cardiff called Streets of Cardiff. It allows anyone to upload (moderated, this is the BBC!) stories, pictures, or videos about different areas and these are presented as points on a map. Below is the Roath Park and Penylan page … where I grew up:
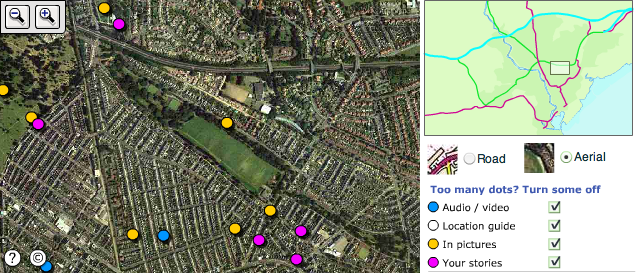
[ screen shot ] [ BBC web page ]
Given it is the BBC no google mashup, but a little flash app! But a very nice bit of webbery, community content etc. … pity they don’t have it for everywhere. For years now I have kept thinking it would be really nice to have a coherent location-based portal of everywhere and even got a domain for it! Whilst google maps and related things are getting close to that dream, still it is hard to find things by location … maybe one day …
This also reminded me of some pictures of Roath Park I took a short while back for a keynote I gave a few years ago “Paths and Patches – patterns of geonosy and gnosis“, so I have just added them as a Roath Park flickr set.
… and now I really must get back to work.
Google’s Vint Cerf avoiding responsibility
Yesterday morning I was on my way into Lancaster and listening to the Today programme. Google’s ‘internet evangelist’ Vint Cerf was being interviewed by John Humphrys and the topic was ‘should the internet be regulated like other media’.1
Not surprisingly Vint Cerf thought not, but I was surprised how well he avoided actually saying so. John Humphrys is experienced and politicians fear him in these early morning interviews, but to be honest he was completely outclassed by Vint Cerf who sidestepped, avoided and generally never addressed the question.
Web 2.0 was the heart of the issue. With end-user content now dominating the internet do service providers such as YouTube (of course owned by Google) have any responsibility for the kinds of material hosted?
This was in the context of videos of ‘happy slappers’ and other violent attacks being posted, but more generally that whereas TV in many countries is limited in the kinds of material it can show, particularly early in the evening when children are more likely to be watching, is limited by a mixture of voluntary and satutory codes. Why not the internet?
Vint Cerf repeatedly re-iterated the same message “Google is law abiding” if content is not legal it is removed. Implicitly the message was “if it is not illegal it is OK”, but as I said he carefully avoided saying so.
The closest point to actually addressing the question was when John Humphrys suggested that technologies could be misused like research for atomic power being used for nuclear weapons (strange I thought it went the other way round?). Vent Cerf’s response was, the standard neutrality of technology stance, that the makers of roads were not responsible for car deaths, strip development … the same argument used by arms dealers, manufacturers of gas guzzling cars, and scientists in every repressive regime in recent history.
According to Cerf if you are a worried parent you need to buy good filtering software; the solution is at the edges of the net … and of course does not involve the likes of Google … who it appears from the context is at the centre?
Now there are very good arguments against regulation both ethical (freedom of expression) and practical (volume of material, international access). The disappointing, and worrying, aspect of this interview was that Google’s key public face was unwilling or unable to constructively enter the debate at all.
- “The 0810 Interview: Godfather of the Internet”, BBC4, Today Programme, Wednesday, 29th August 2007[back]
online image manipulation
I was looking around for online image manipulation programs. I found a few and all seemed quite basic (no real turbocharged web2.0 one), but iaza caught my eye … basic but lots of pictures of the site developer’s Tibetan spaniel Niro!

The other one that seemed interesting was wiredness which is quite basic in functionality, but clearly aiming to be zappy in its interface … and has an API so you can send images to it from other sites for manipulation (what I was looking for).
spell with flickr
I just found a wonderful service spell with flickr that makes images like:




It is built from a pool of letters on flickr which have been collected independently (there are also pools for digits and punctuation), a lovely example of Web2.0 in action!
I’ve added it to Snip!t, so now if you snip a single word ‘spell with flickr’ gets suggested as an action.
tagging … I am not alone … or am I?
I’ve noticed that I reuse very few tags … and thought I was just a poor tag-user. However, I read the other day a reference to a paper at the CSCW confernce last year; it reported that the average number of re-uses of a tag was just 1.311 . I thought this meant that most tags are never reused … I am not alone 🙂
Having downloaded and read the paper it turns out that this is the average number of users who use a tag – that is most tags are used by only one person, in fact individuals reuse their own tags a lot more … so I am no-good tagger after all 🙁
Incidentally, I use ultimate tag warrior plugin for wordpress and it seems OK. Only drawback is that if you want tags displayed with your post, they really get inserted into the post itself. This is not a problem for tags at the end, but would mess up an RSS feed if you like your tags above the post. I guess this is because wordpress does not have a handle for plugins to add things to display loops, so the only way to ensure the tags are displayed are to make them part of the post.
Also Nad sent me a link to a neat tag visualisation by Moritz Stefaner.
- Sen, S., Lam, S. K., Rashid, A., Cosley, D., Frankowski, D., Osterhouse, J., Harper, F. M., and Riedl, J. 2006. tagging, communities, vocabulary, evolution. In Proceedings of the 2006 20th Anniversary Conference on Computer Supported Cooperative Work {Banff, Alberta, Canada, November 04 – 08, 2006}. CSCW ’06. ACM Press, New York, NY, 181-190. DOI= http://doi.acm.org/10.1145/1180875.1180904[back]
omnignorance, the future of the web
The dream of the web seems a form of omniscience, unlmited and universal knowledge available at the vlick ofof a button or least at the click of a Google ‘Seach’ button. However, last night I was on a site that empitomised the problems of the web.
I was pointed to a blog entry about a presentation that the blog said was “Simply the best presentation I’VE EVER SEEN!“. I was intrigued and and followed this to the Identity2.0 site and in particular a page about a keynote at OSCON 2005.
The entry about the talk mentioned ‘Identity2.0’ and ‘digital identity’ so guessed this was something to do with single logins (like MS passport) or open authentication, which has long been an open issue (with many ‘solutions’ but so far little success). However, was this person and this site talking about one of these such as plain open authentication, or something deeper.
Well it is fine for the page about the talk not to say clearly, it is written within the context of the Indetity2.0 site, so I looked for an ‘about’ link or something like that … nothing I stripped the url back to plain identity2.0.com and of course simply got to a stabdard blog front page (I guess rather like this one), with the latest news, but nothing to gove over context or background.
In fact by chasing yet more links to other sites, by half guessing from various abstracts, blog entries, etc. I managed to pick out half a story about what this was about … but why so hard?
This reminds me of the problem I recorded a month or so back when trying to find last week’s (as opposed to yesterday’s) news. Really easy to find the latest item or even the hotest item, but really bad at getting to the background that gives context and turns buzz words into meaning.
At the risk of sounding like a codger at a cafe table, the same is true of much software documentation. If you have seen the software grow and develop over the years it makes sense, but to students trying to make sense of Java packages, AJAX, Mac/Windows APIs, it is like fumbling in the dark. Good signpoosting at every street corner, but no roadmaps.
In all these cases there are real questions we want to ask, this is not like meandering around Flickr or YouTube, travelling just for the journey. However definitive statements (I’ll not say answers) give way to half-overheard conversations in a coffee shop.
It is often said that experts know more and more about less and less untul eventually they know everything about nothing. It seems we are turning into a generation who know less and less about more and more until we know nothing about everthing – omingnorance rules.
paying the tax
tax collectors get a bad press, but we have just got to the end of filling in our annual tax returns online and is an amazingly trouble free process … I can still remember when it was paper forms and 2 days before the final deadline we’d discover we needed extra green pages for this thing or other. Now-a-days you just fill in the boxes on the web form, if you haven’t got the figures it just remembers it all for later, then at the end you press the button and it works out everything. And even better, they said they owed me £80 🙂
If only every online service was as good. A short while ago we tried to open a savings account with the Northern Rock and gave up as the applet-based system they use is not compatable with Apple Macs … other banks seem to be able to use SSL for security and browser-independent HTML, so why not them! Suffice to say we went elsewhere.
Even worse was an experience early last year. I’d given a seminar at another university and submitted an expense claim. The university sent me payment advice as an email, but it displayed oddly when I viewed it and got a high spamassassin rating. A bit of digging and I found that the high spam rating was due to the fact that there was not a closing body tag in the HTML. I was going to mail the university IT support and then saw that the company who supplied the software, Albany Software, was named in the email and decided to mail them directly to avoid embarassing them to their client.
So I went to their web site … but it didn’t display properly in Firefox, I tried Safari … even worse! Eventually I got their ‘support’ contact email by using view source and mailed them, mentioning both the broken HTML in the email and the broken website.
The reply from their ‘support’ email:
“Try using Microsoft Internet Explorer. Though Firefox is vastely superior, most websites/applications are only compatible with Internet Explorer.”
Who said the days of the old sys admins had gone!
The happy end to the last story is that I just revisited their site, they have at last got it working cross browser … well I guess better late than never.
Anyway thumbs up for Her Majesty’s Revenue & Customs, even if others need to catch up a little.
footnotes
I’ve just installed the footnotes plugin in my WordPress1 . It seems to work a dream.
I’ve used the following CSS:
ol.footnotes{
font-size:.9em;
color:#666666;
margin-top:0px;
}ol.footnotes li{
list-style-type:decimal;
}
- makes footnotes like this[back]