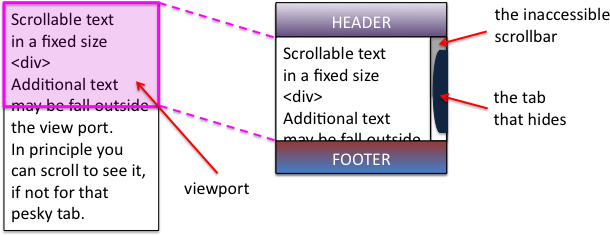
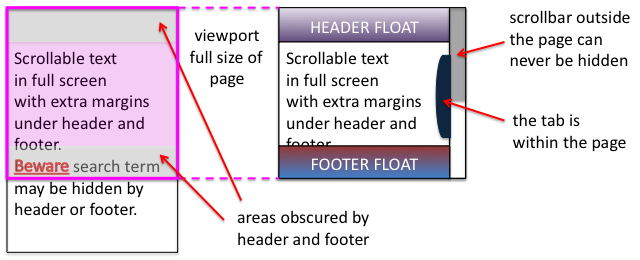
Tiree’s Historical Centre An Iodhlann has just been awarded funding by the Scottish Digital Research and Development Fund for Arts and Culture to make historic archive material available through a mobile application whilst ‘on the ground’ walking, cycling or driving around the island.
Tiree’s Historical Centre An Iodhlann has just been awarded funding by the Scottish Digital Research and Development Fund for Arts and Culture to make historic archive material available through a mobile application whilst ‘on the ground’ walking, cycling or driving around the island.
I’ve been involved in bigger projects, but I can’t recall being more excited than this one: I think partly because it brings together academic interests and local community.
the project
An Iodhlann (Gaelic for a stackyard) is the historical centre on the island of Tiree. Tiree has a rich history from the Mesolithic period to the Second World war base. The archive was established in 1998, and its collection of old letters, emigrant lists, maps, photographs, stories and songs now extends to 12 000 items. 500 items are available online, but the rest of the primary data is only available at the centre itself. A database of 3200 island place names collated by Dr Holliday, the chair of An Iodhlann, has recently been made available on the web at tireeplacenames.org. Given the size of the island (~750 permanent residents) this is a remarkable asset.



To date, the online access at An Iodhlann is mainly targeted at archival / historical use, although the centre itself has a more visitor-centred exhibition. However, the existing digital content has the potential to be used for a wider range of applications, particularly to enhance the island experience for visitors.
 Over the next nine months we will create a mobile application allowing visitors and local historians to access geographically pertinent information, including old photographs, and interpretative maps/diagrams, while actually at sites of interest. This will largely use visitors’ own devices such as smart phones and tablets. Maps will be central to the application, using both OS OpenData and bespoke local maps and sketches of historical sites.
Over the next nine months we will create a mobile application allowing visitors and local historians to access geographically pertinent information, including old photographs, and interpretative maps/diagrams, while actually at sites of interest. This will largely use visitors’ own devices such as smart phones and tablets. Maps will be central to the application, using both OS OpenData and bespoke local maps and sketches of historical sites.
As well as adding an extra service for those who already visit An Iodhlann, we hope that this will attract new users, especially younger tourists. In addition a ‘data layer’ using elements of semantic web technology will mean that the raw geo-coded information is available for third parties to mash-up and for digital humanities research.
the mouse that roars
 The Scottish Digital Research and Development Fund for Arts and Culture is run by Nesta, Creative Scotland and the Arts and Humanities Research Council (AHRC).
The Scottish Digital Research and Development Fund for Arts and Culture is run by Nesta, Creative Scotland and the Arts and Humanities Research Council (AHRC).
This was a highly competitive process with 52 applications of which just 6 were funded. The other successful organisations are: The National Piping Centre, Lyceum Theatre Company and the Edinburgh Cultural Quarter, Dundee Contemporary Arts, National Galleries of Scotland, Glasgow Film Theatre and Edinburgh Filmhouse. These are all big city organisations as were the projects funded by an earlier similar programme run by Nesta England.
As the only rural-based project, this is a great achievement for Tiree and a great challenge for us over the next nine months!
challenges
In areas of denser population or high overall tourist numbers, historical or natural sites attract sufficient visitors to justify full time (volunteer or paid) staff. In more remote rural locations or small islands there are neither sufficient people for volunteers to cover all, or even a significant number, of sites, nor have they sufficient tourist volume to justify commercial visitor centres.
 A recent example of this on Tiree is the closing of the Thatched Cottage Museum. This is one of the few remaining thatched houses on the island, and housed a collection of everyday historical artefacts. This was owned by the Hebridean Trust, and staffed by local volunteers, but was recently closed and the building sold, as it proved difficult to keep it staffed sufficiently given the visitor numbers.
A recent example of this on Tiree is the closing of the Thatched Cottage Museum. This is one of the few remaining thatched houses on the island, and housed a collection of everyday historical artefacts. This was owned by the Hebridean Trust, and staffed by local volunteers, but was recently closed and the building sold, as it proved difficult to keep it staffed sufficiently given the visitor numbers.
 At some remote sites such as the Tiree chapels, dating back to the 10th century, or Iron Age hill forts, there are simple information boards and at a few locations there are also fixed indoor displays, including at An Iodhlann itself. However, there are practical and aesthetic limits on the amount of large-scale external signage and limits on the ongoing running and maintenance of indoor exhibits. Furthermore, limited mobile signals mean that any mobile-based solutions cannot assume continuous access.
At some remote sites such as the Tiree chapels, dating back to the 10th century, or Iron Age hill forts, there are simple information boards and at a few locations there are also fixed indoor displays, including at An Iodhlann itself. However, there are practical and aesthetic limits on the amount of large-scale external signage and limits on the ongoing running and maintenance of indoor exhibits. Furthermore, limited mobile signals mean that any mobile-based solutions cannot assume continuous access.
from challenge to experience
Providing information on visitors’ own phones or tablets will address some of the problems of lack of signage and human guides. However, achieving this without effective mobile coverage means that simple web-based solutions will not work.
The application used whilst on the ground will need to be downloaded, but then this limits the total amount of information that is available whilst mobile; our first app will be built using HTML5 to ensure it will be available on the widest range of mobile devices (iOS, Android, Windows Mobile, ordinary laptops), but using HTML5 further reduces the local storage available.
 In order to deal with this, the on-the-ground experience will be combined with a web site allowing pre-trip planning and post-trip reminiscence. This will also be map focused, allowing visitors to see where they have been or are about to go, access additional resources, such as photos and audio files that are too large to be available when on the ground (remembering poor mobile coverage). This may also offer an opportunity to view social content including comments or photographs of previous visitors and then to associate one’s own photographs taken during the day with the different sites and create a personal diary, which can be shared with others.
In order to deal with this, the on-the-ground experience will be combined with a web site allowing pre-trip planning and post-trip reminiscence. This will also be map focused, allowing visitors to see where they have been or are about to go, access additional resources, such as photos and audio files that are too large to be available when on the ground (remembering poor mobile coverage). This may also offer an opportunity to view social content including comments or photographs of previous visitors and then to associate one’s own photographs taken during the day with the different sites and create a personal diary, which can be shared with others.
On reflection, this focus on preparation and reminiscence will create a richer and more extended experience than simply providing information on demand. Rather than reading reams of on-screen text whilst looking at a monument or attempting to hear an audio recording in the Tiree wind, instead visitors will have some information available in the field and more when they return to their holiday base, or home.



 I was reading a quite disturbing article on a
I was reading a quite disturbing article on a