Query-by-Browsing now has ‘user explanations’, ways for users to tell the machine learning component which features are significant in the user provided examples. As promised in my blog about local AI explanations in QbB a few weeks ago, this version of QbB is released to coincide with our paper “Talking Back: human input and explanations to interactive AI systems” that Tommaso Turchi is presenting at the Workshop on Adaptive eXplainable AI (AXAI) at IUI 2025 in Cagliari, Italy,
As part of the EU Horizon Tango project, on hybrid human–AI decision making, we have been thinking about what it would mean for users to provide the AI with explanations of their human reasoning in order to guide machine learning and improve the AI’s explanations of its outputs.
As an exemplar of this I have modified QbB to include forms of user explanation. These are of two kinds, global user explanations to guide the overall machine learning and local user explanations focused on individual examples.
Play with this version of QbB or see the QbB documentation in Alan Labs.
Basic operation
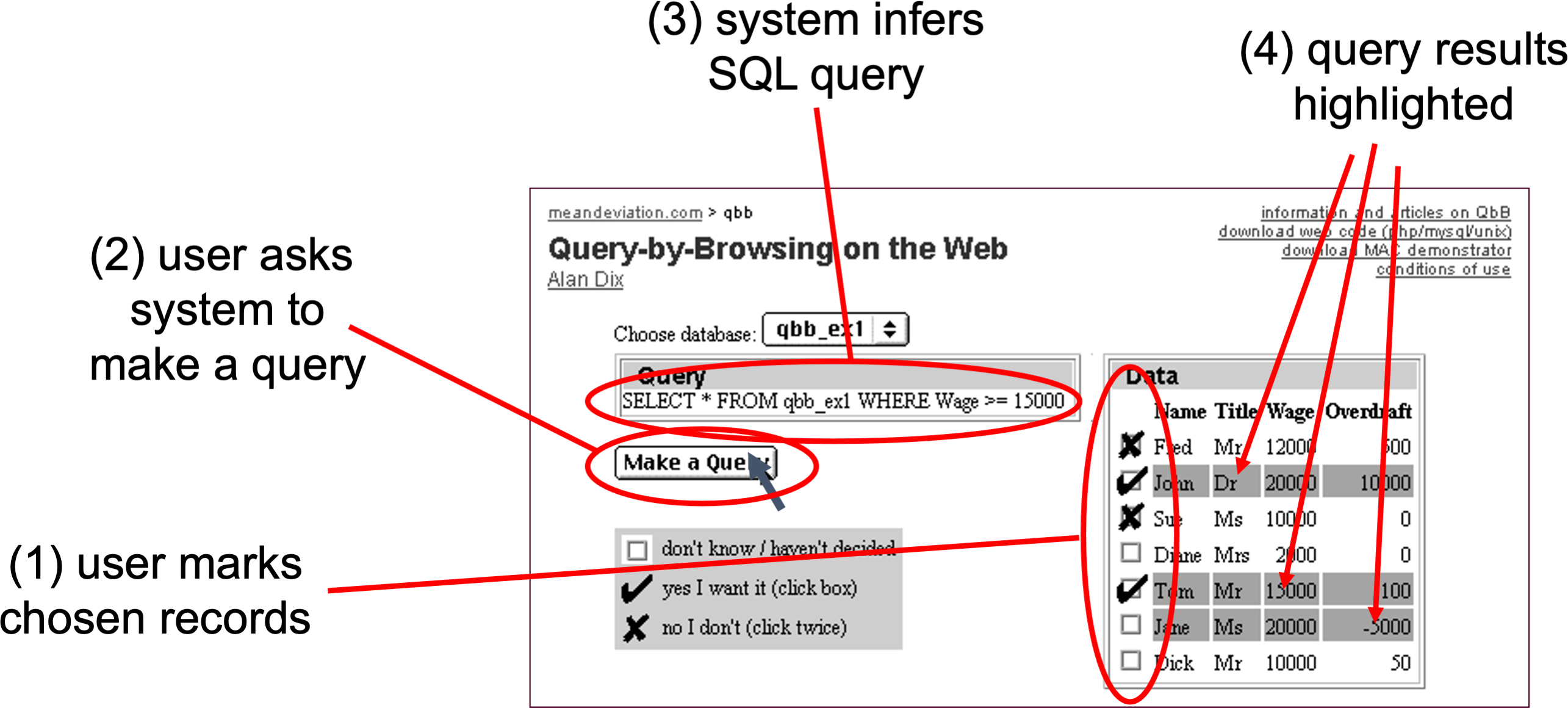
Initially you use QbB as normal: you select examples of records you do and don’t want included and the system infers a query using a variant of ID3 that can be presented as a decision tree or an SQL query.
Global user guidance
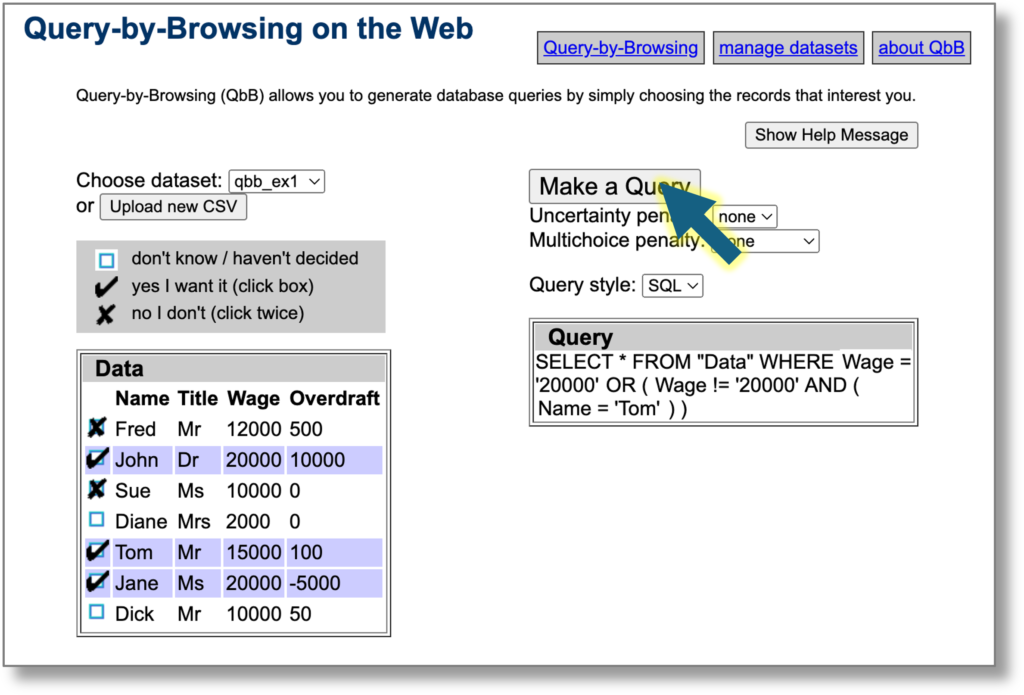
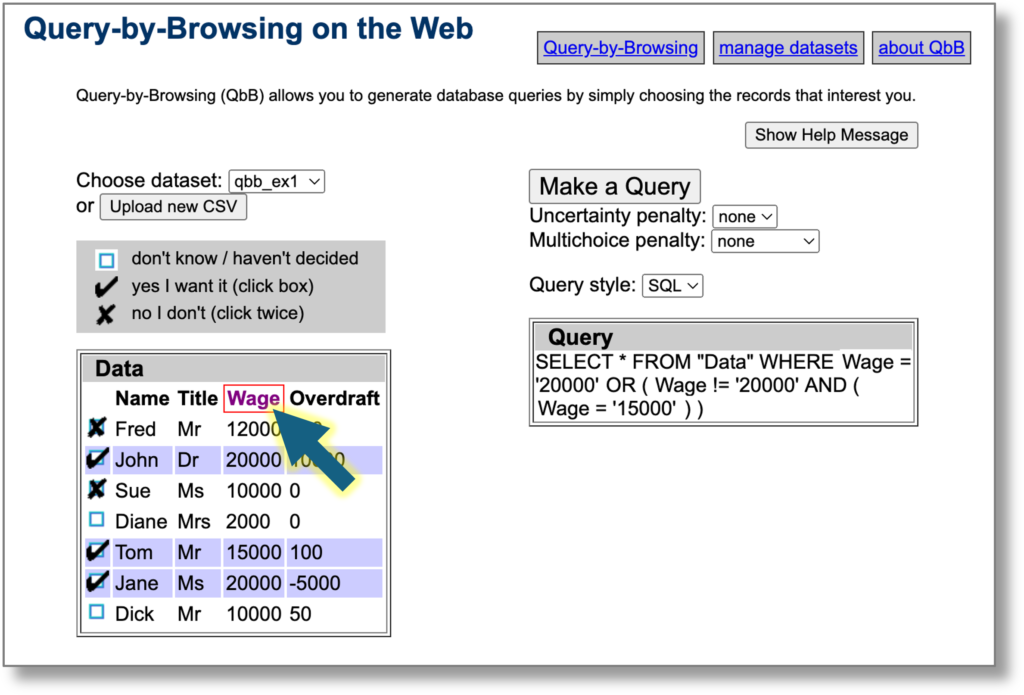
At any point you can click row headers to toggle between important (red border), ignore (grey) or standard. The query refreshes taking into account these preferences . Columns marked ‘ignore’ are not used at all by the machine learning, whereas those marked as ‘important’ are given preference when it creates the query.
In the screenshot below the Wage column is marked as important. Compare this to the previous image where the name ‘Tom’ was used in the query.
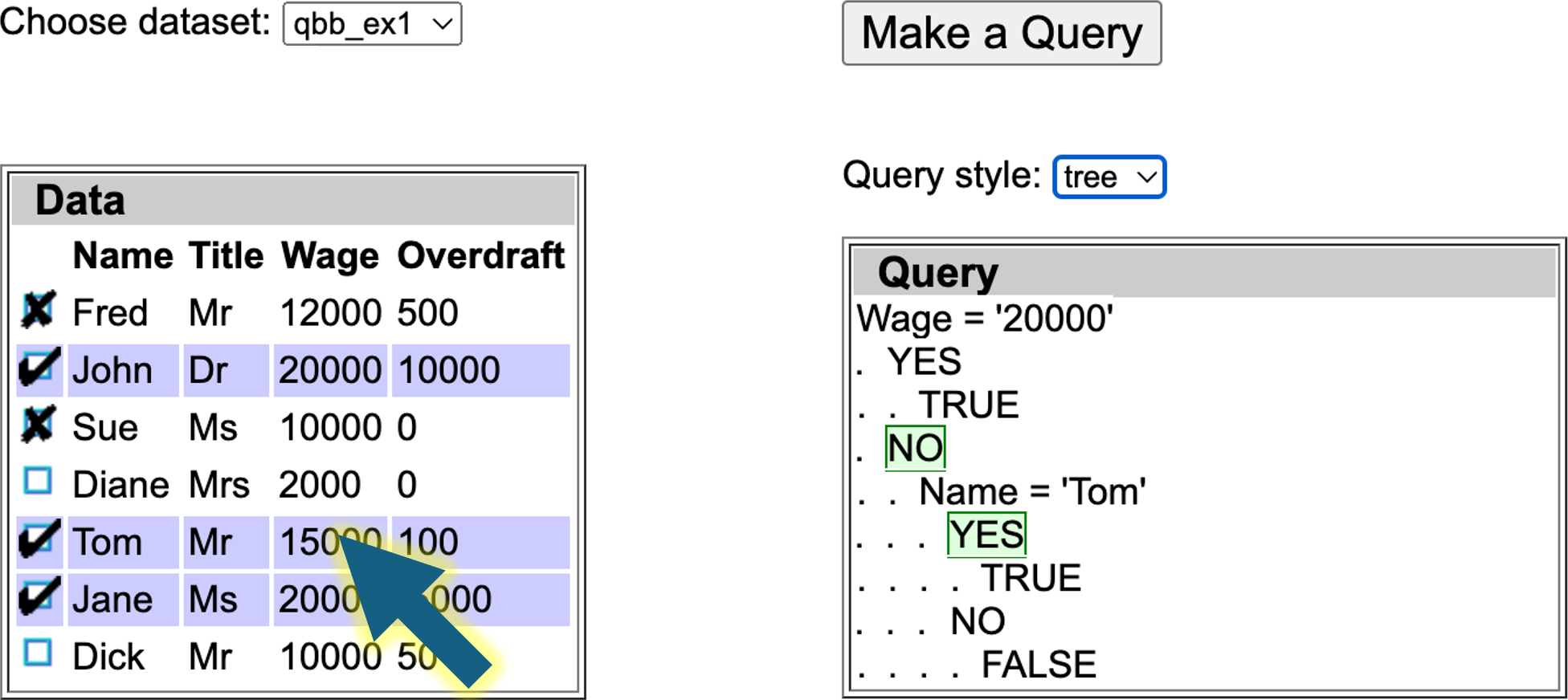
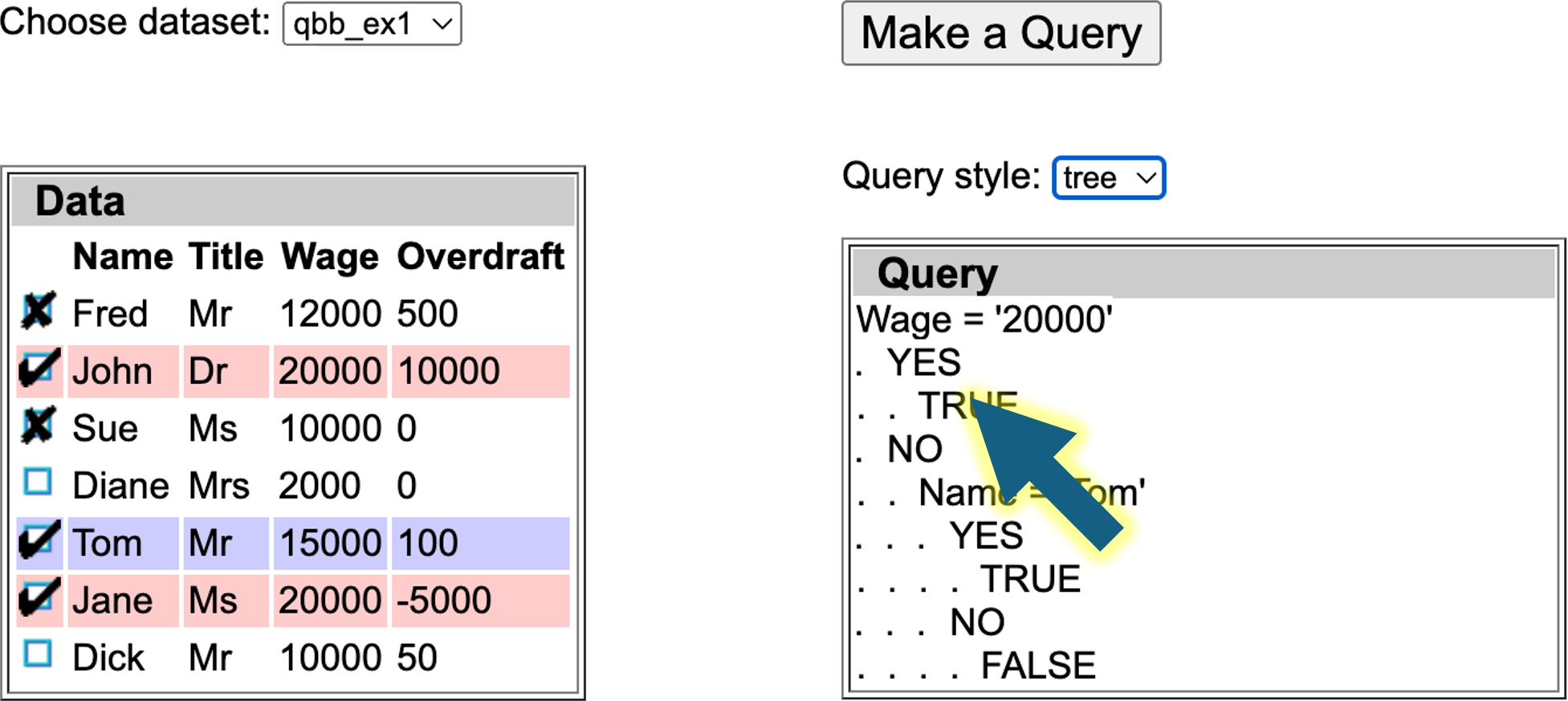
Local user explanations
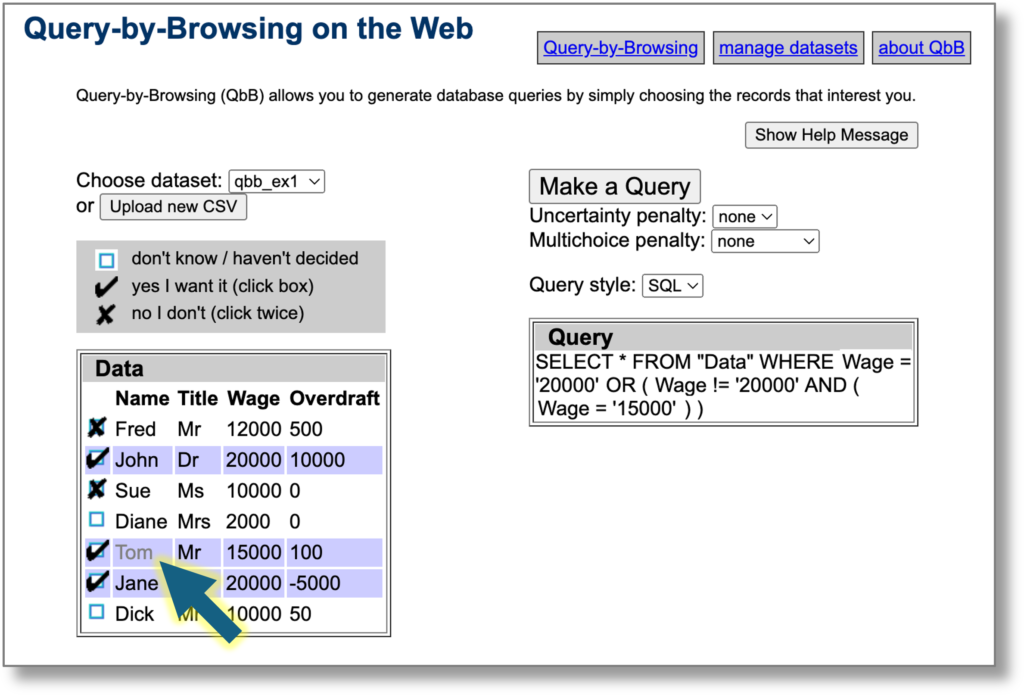
In addition you can click data cells in individual rows to toggle between important (red border), not important (grey) or standard. This means that for this particular example the relevant field is more or less important. Note that is a local explanation, just because a field is important for this record selection, it does not mean it is important for them all.
See below the same example with the column headers all equally important, but the cell with contents ‘Tom’ annotated as unimportant (grey). The generated query does not use this value. However, note that while the algorithm does its best to follow the preferences, it may not always be able to do so.
Under the hood
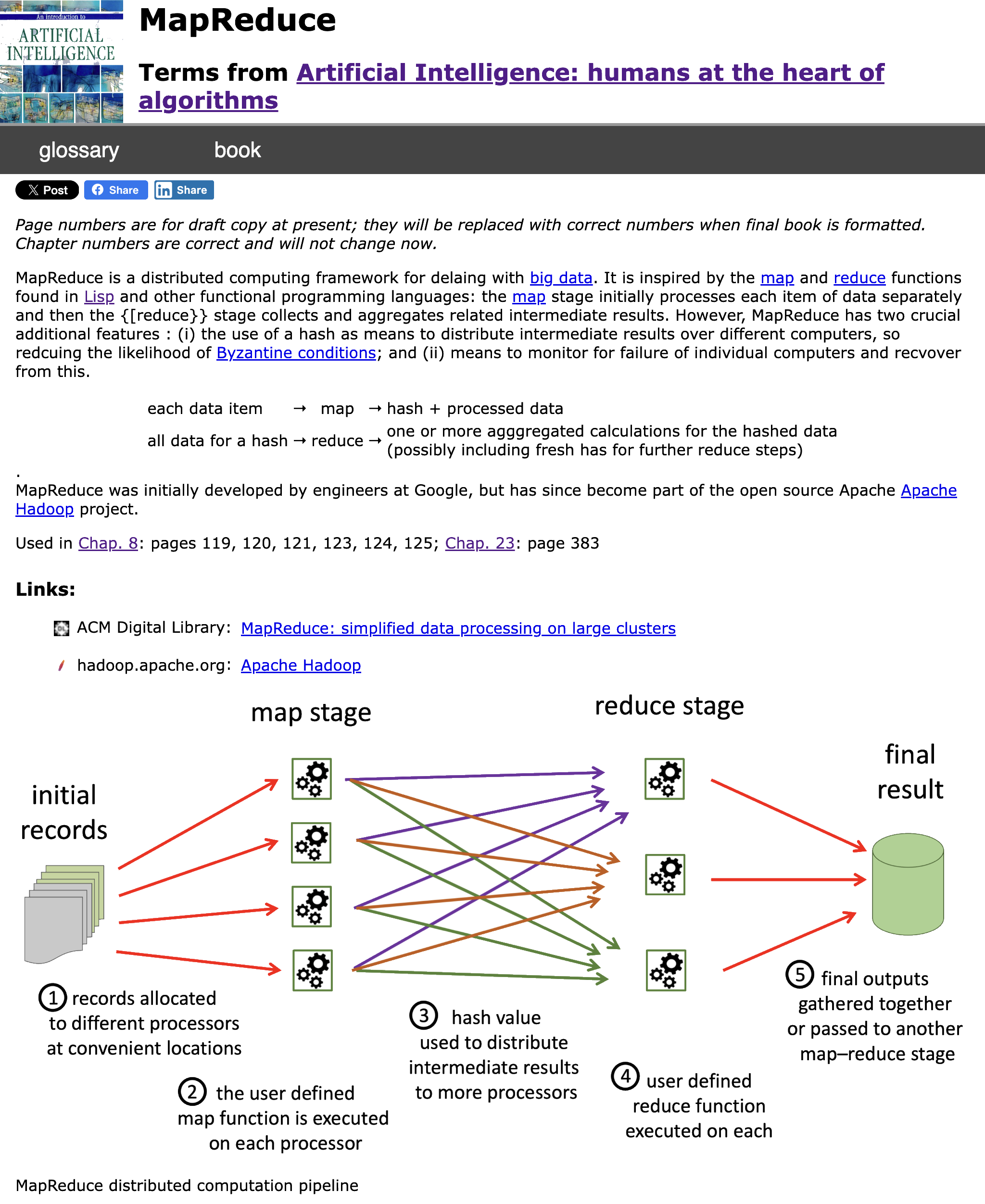
Query-by-Browsing uses a modified version of Quinlan’s ID3 decision tree induction algorithm, which has been one of the early and enduring examples of practical machine learning. The variant used in previous versoins of QbB includes cross-column comparisons (such as ‘outgoings>income‘), but otherwise use the same information-entropy-based procedure to build the decision tree top down.
The modified version to take into account global user guidances and local user explanations still follows the top-down approach.
For the global column-based selections, the ‘ignore’ columns are not included at all and the entropy-score of the ‘important’ columns are multiplied by a weighting to make the algorithm more likely to select decisions based on these columns. Currently this is a fixed scaling factor, but could be made variable to allow levels of importance to be added to columns.
For the local user explanations, a similar process is used except: (a) the columns for unimportant cells are scaled-down to make them less likely to be chosen rather than forbidden entirely; (b) the scaling up/down for the columns of important/unimportant cells depends on the proportion of labelled cells below the current node. This means that the local explanation makes little difference in the higher-level nodes, where an individual cell is one amongst many unless several have similar cell-level labels, however, as one comes closer to the nodes that drive the decision for a particular annotated record its cell labelings become more significant.
Note that this is a relatively simple modification of the current algorithm. One of the things we point out in the ‘talking back‘ paper is that user explanations open up a wide range of challenges in both user interfaces and fundamental algorithms.
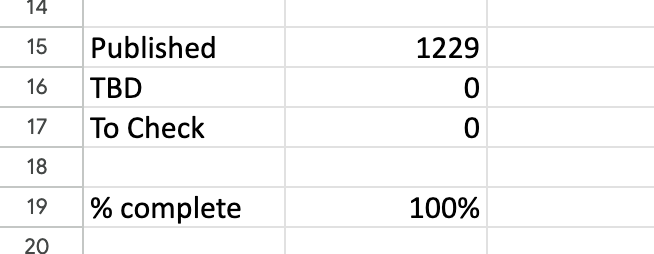





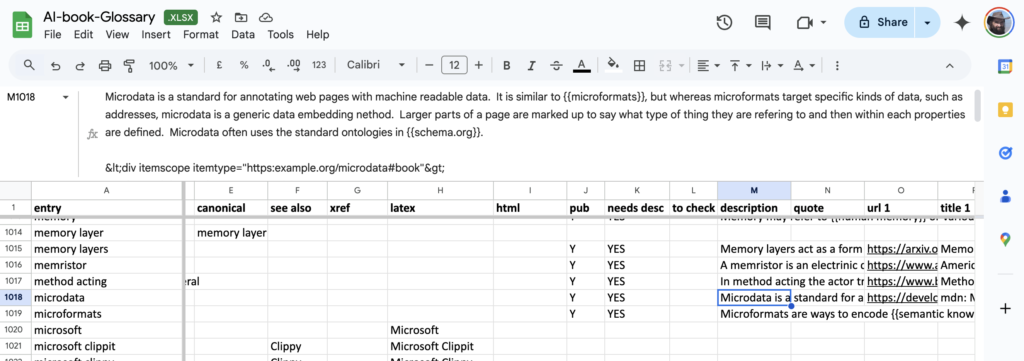


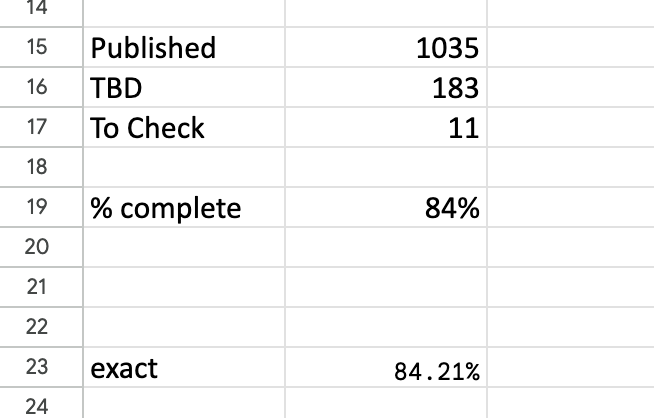 The headline summary has raw counts and a rounded %complete. Seeing this notch up one percent was a major buzz corresponding to about a dozen entries. Below that is a more precise percentage, which I normally kept below the bottom of the window so I had to scroll to see it. I could take a peek and think “nearly at a the next percent mark, I’ll just do a few more”.
The headline summary has raw counts and a rounded %complete. Seeing this notch up one percent was a major buzz corresponding to about a dozen entries. Below that is a more precise percentage, which I normally kept below the bottom of the window so I had to scroll to see it. I could take a peek and think “nearly at a the next percent mark, I’ll just do a few more”.